'In 'panda's' kunnen we het tekstbestand gemakkelijk lezen met behulp van de 'panda's'-methode. “Pandas” geeft ons de mogelijkheid om het tekstbestand te lezen. 'Panda's' geeft verschillende ingebouwde methoden voor het lezen van het tekstbestand. We zullen alle methoden in deze tutorial samen met alle parameters hier bespreken en ze in detail uitleggen. We zullen ook het tekstbestand in 'panda's' lezen door de methoden van 'panda's' in onze codes hier te gebruiken.
Methoden voor het lezen van het tekstbestand in 'panda's'
In 'panda's' hebben we drie methoden die ons helpen bij het lezen van het tekstbestand. We hebben hier ook enkele voorbeelden gedaan waarin we het tekstbestand lezen. De methoden die de 'panda's' bieden, worden hieronder besproken:
-
- Door gebruik te maken van de pd.read_csv() methode.
- Door gebruik te maken van de pd.read_table() methode.
- Door gebruik te maken van de pd.read_fwf() methode.
Nu leggen we de syntaxis van al deze methoden uit en bespreken we ook de parameters van alle methoden in detail in deze tutorial.
Syntaxis van read_csv()
pd.read_csv ( ‘bestandsnaam.txt’, sep =' ', koptekst =Geen, namen = [ “Kol_naam1”, “Kol_naam2, “Kol_naam2”, ………….. ] )
Bij deze methode voegen we eerst de naam toe van het tekstbestand waarvan we de gegevens willen lezen, en het is de eerste parameter van deze methode. Vervolgens plaatsen we de 'sep', wat een scheidingsteken is in deze methode, en we plaatsen hier spatie als het teken, zodat het de spatie als scheidingsteken zal beschouwen. Hierna hebben we de header-parameter en de waarde 'None' van deze parameter wordt gebruikt, dus het zal de standaardheader maken en als we deze parameter niet toevoegen, zal het de eerste regel van het tekstbestand beschouwen als de kop. In de parameter 'names' kunnen we de kolomnamen toevoegen die we als koptekst moeten toevoegen.
Syntaxis van read_table()
pd.read_table ( 'bestandsnaam.txt' , scheidingsteken = ' ' )
Bij deze methode plaatsen we de bestandsnaam van het tekstbestand als de eerste parameter. Als we in het scheidingsteken ‘ ’ plaatsen, wordt het spatieteken als scheidingsteken gebruikt.
Syntaxis van read_fwf()
pd.read_fwf ( 'bestandsnaam.txt' )
Deze methode heeft slechts één parameter nodig, namelijk de naam van het tekstbestand.
Nu zullen we deze methoden gebruiken om de tekstbestanden in 'panda's' -codes te lezen en de gegevens van het tekstbestand op de terminal te tonen.
Voorbeeld # 01
De 'Spyder' -app is hier waarin we al deze codes hebben gedaan die in deze tutorial worden gepresenteerd. Het tekstbestand waarvan we de gegevens willen lezen, wordt hieronder weergegeven. We zullen de methode 'read_csv()' gebruiken om dit tekstbestand in 'panda's' te lezen.
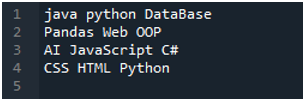
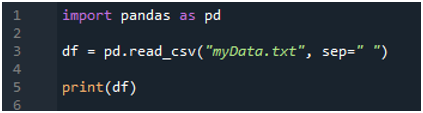
We importeren eerst de 'panda's'-bibliotheek omdat we de 'read_csv()'-methode willen gebruiken, en dit is de methode van 'panda's'. We hebben alleen toegang tot deze methode als we de bibliotheek van 'panda's' hebben geïmporteerd. Hier noemen we 'panda's als pd', dus deze 'pd' wordt geplaatst bij de naam van de methode om het te gebruiken. Hierna maken we hier een variabele 'df' aan, die wordt gebruikt voor het opslaan van de gegevens van het tekstbestand na het lezen. We plaatsen hier de 'pd.read_csv()'-methode, die helpt bij het lezen van het tekstbestand en het converteren van de tekstbestandsgegevens naar het DataFrame en het opslaan in de 'df' -variabele.
We hebben hier de bestandsnaam doorgegeven, namelijk 'myData.txt', en dan gebruiken we 'sep' en wijzen we het lege teken toe aan deze 'sep'. Dit blanco teken werkt dus als scheidingsteken in het tekstbestand. Vervolgens hebben we de onderstaande 'print()' gebruikt, die wordt gebruikt voor het afdrukken van de gegevens van het tekstbestand. Het toont de gegevens van het tekstbestand in het DataFrame-formulier.
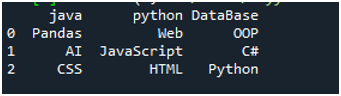
Voor de uitvoering van deze code moeten we op 'Shift + Enter' drukken en de uitvoer wordt weergegeven op de 'Spyder's' -terminal. Het resultaat van de bovenstaande code wordt weergegeven in de gegeven schermafbeelding en u kunt zien dat de gegevens van het tekstbestand worden weergegeven als het DataFrame en dat de eerste regel van ons tekstbestand hier wordt weergegeven als de kolomnamen van dat DataFrame. Het scheidt ook de gegevens waar het spatieteken aanwezig is in het tekstbestand.
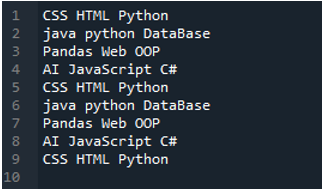
Voorbeeld # 02
Het tekstbestand dat we in dit voorbeeld zullen lezen, wordt hier getoond en we zullen opnieuw de 'read_csv()'-methode gebruiken, maar met andere parameters.
De 'panda's'-methode 'pd.read_csv()' wordt gebruikt en we geven hier drie parameters door. Eerst plaatsen we de bestandsnaam, dit is 'Record.txt'. De tweede parameter is de 'sep' -parameter en wijst er het lege teken aan toe, en dan hebben we de derde parameter waarin we de 'header' instellen en deze aanpassen aan 'None', dus het zal de standaardheader van het DataFrame maken wanneer we deze code uitvoeren. We hebben dit alles opgeslagen in de variabele 'My_Record' en ook 'My_Record' toegevoegd in de functie 'print()' om af te drukken.

Alle gegevens worden opgeslagen in het DataFrame en het scheidt de gegevens waar het spatieteken aanwezig is in de tekstbestandsgegevens. Het heeft hier ook de standaardheader van het DataFrame gemaakt omdat we de parameter 'header' hebben aangepast naar 'Geen'.
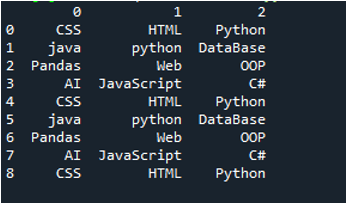
Voorbeeld # 03
Het tekstbestand van dit voorbeeld wordt weergegeven en we zullen opnieuw de methode 'read_csv()' gebruiken met gewijzigde parameters.
In deze code worden hier vier parameters doorgegeven aan de 'panda's'-methode 'pd.read_csv()'. De naam van het tekstbestand is de eerste parameter. De parameter 'sep' krijgt het lege teken in de tweede parameter. De parameter 'header' is ingesteld op 'None' in het derde argument en als vierde parameter hebben we de 'names' ingesteld die zullen verschijnen als de kolomnamen van het DataFrame na het lezen van het tekstbestand, en deze kolomnamen zijn 'COL_1, COL_2, COL_3, COL_4 en COL_5'. Al deze informatie is opgeslagen in de variabele 'My_Record' en 'My_Record' is ook toegevoegd aan de methode 'print()', zodat het op de terminal wordt afgedrukt.

Alle informatie van het tekstbestand wordt hier weergegeven als het DataFrame, en het scheidt ook de gegevens waar de spaties in het tekstbestand worden toegevoegd. Het voegt ook de kolomnamen dienovereenkomstig toe, die we hierboven in de code hebben toegevoegd.
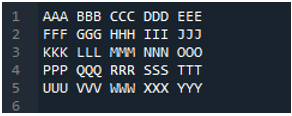
Voorbeeld # 04
Dit is het tekstbestand dat we in dit voorbeeld zullen lezen door een andere methode te gebruiken, de 'pd.read_table()' methode.
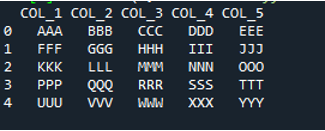
De methode 'pd.read_table()' is hier toegevoegd voor het lezen van het tekstbestand, en we voegen 'ABC.txt' toe, wat de naam van het tekstbestand is. Deze methode helpt bij het lezen van het tekstbestand, en we hebben ook de parameter 'delimiter' aangepast aan het spatieteken, dus het zal ook werken als het scheidingsteken dat we hierboven hebben uitgelegd. Vervolgens worden alle bestandsgegevens van de tekst opgeslagen in de variabele 'My_Data' en ook hier afgedrukt.

De eerste regel van ons tekstbestand wordt hier weergegeven als de kolomnamen van het DataFrame en de gegevens van het tekstbestand worden afgedrukt als het DataFrame. Bovendien scheidt het de gegevens van het tekstbestand waarin het spatieteken aanwezig is.
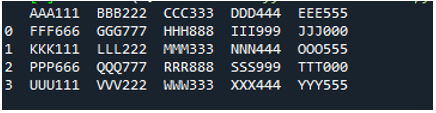
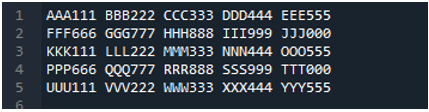
Voorbeeld # 05
Nu bevat het tekstbestand de gegevens, die hieronder worden weergegeven. We zullen deze keer de 'read_fwf()' toepassen en laten zien hoe gegevens worden weergegeven na het lezen van het tekstbestand.
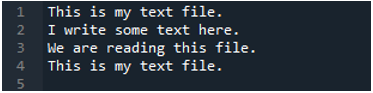
Zoals we weten, heeft deze methode 'read_fwf()' slechts één parameter nodig, namelijk de bestandsnaam die we willen lezen. We voegen hier 'textfile.txt' toe, wat de naam is van ons tekstbestand en wijzen deze panda-methode toe aan de variabele 'File_Data', die de gegevens van dit tekstbestand zal opslaan. Vervolgens plaatsen we 'print(File_Data)', zodat deze gegevens ook worden afgedrukt.

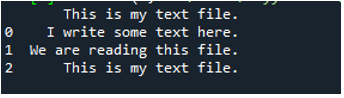
Hier worden alle gegevens van het tekstbestand getoond. Het scheidde de gegevens niet waar spatietekens aanwezig zijn, omdat er geen parameter zoals 'Sep' of 'scheidingsteken' in deze functie is.
Conclusie
Deze tutorial legt uit hoe je het tekstbestand in 'panda's' kunt lezen en welke methoden worden gebruikt voor het lezen van het tekstbestand in 'panda's'. We hebben alle methoden besproken die ons helpen bij het lezen van het tekstbestand in 'panda's'. We hebben in deze tutorial drie verschillende methoden van 'panda's' onderzocht voor het lezen van onze tekstbestanden in 'panda's'. We hebben hier ook de syntaxis van alle methoden en de parameters van alle methoden in detail uitgelegd en hebben veel tekstbestanden gelezen door verschillende methoden toe te passen met alle mogelijke parameters in deze tutorial.