“Comma-Separated Values (CSV) is een van de meest veelzijdige en gebruiksvriendelijke gegevensformaten. Het is een lichtgewicht gegevensformaat waarmee ontwikkelaars en toepassingen gegevens van de ene bron naar de andere kunnen overbrengen en parseren.
CSV-gegevens slaan gegevens op in tabelvorm waarbij elke kolom wordt gescheiden door een komma en een nieuw record wordt toegewezen aan een nieuwe regel. Dit maakt het een zeer goede keuze voor het exporteren van databases zoals SQL-databases, Cassandra-gegevens en meer.
Het is daarom geen verrassing dat u een scenario tegenkomt waarin u een CSV-bestand in uw database moet importeren.
Het doel van deze tutorial is om u een snelle en eenvoudige methode te laten zien om een CSV-bestand in uw Elasticsearch-cluster te importeren met behulp van het Kibana-dashboard.”
Laten we erin springen.
Vereisten
Zorg ervoor dat u aan de volgende vereisten voldoet voordat u erin gaat duiken:
- Een Elasticsearch-cluster met groene gezondheidsstatus.
- Kibana-server verbonden met uw Elasticsearch-cluster.
- Voldoende machtigingen om indexen op uw cluster te beheren.
Voorbeeld CSV-bestand
Zoals gewoonlijk is de eerste vereiste uw bron-CSV-bestand. Het is goed om ervoor te zorgen dat de gegevens in uw CSV-bestand goed zijn opgemaakt en dat deze geen fouten bevatten.
Ter illustratie gebruiken we een gratis dataset met films en tv-programma's van Amazon Prime.
Open uw browser en ga naar de onderstaande bron:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Volg de procedure om de dataset naar uw lokale computer te downloaden. U kunt het gedownloade archief uitpakken met de opdracht:
$ uitpakken een~ / Downloads / archief.zip
CSV-bestand importeren
Zodra u uw bronbestand gereed heeft, kunnen we doorgaan en bespreken hoe u het kunt importeren.
Begin door naar uw Kibana-startdashboard te gaan en de optie 'een bestand uploaden' te selecteren.
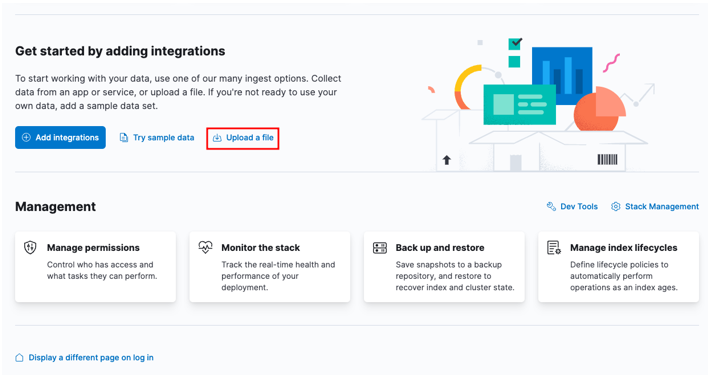
Zoek het doel-CSV-bestand dat u wilt importeren in het opstartvenster.
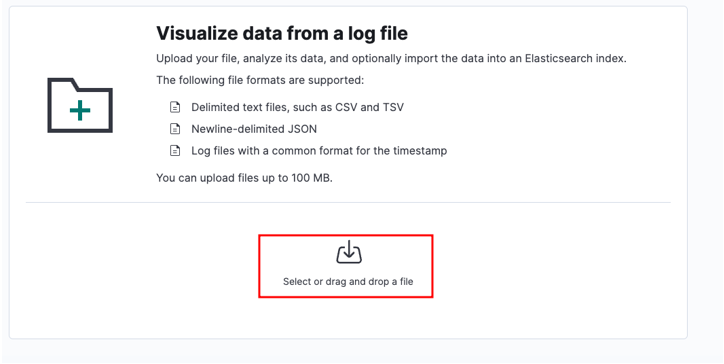
Selecteer je bronbestand en klik op uploaden.
Laat Elasticsearch en Kibana het geüploade bestand analyseren. Dit zal het CSV-bestand ontleden en het gegevensformaat, de velden, de gegevenstypen, enz. bepalen.
OPMERKING: Afhankelijk van uw clusterconfiguratie en de gegevensgrootte kan dit proces enige tijd duren. Zorg ervoor dat het hoofdknooppunt reageert om time-outs te voorkomen.
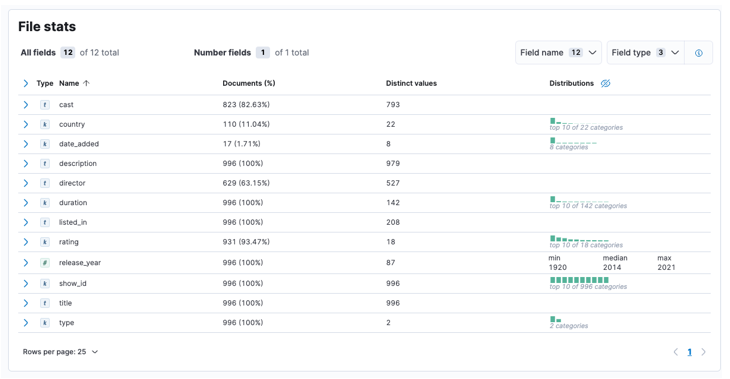
Zodra het proces is voltooid, moet u een voorbeeld krijgen van uw bestandsinhoud en de bestandsstatistieken zoals geanalyseerd door Elastic.
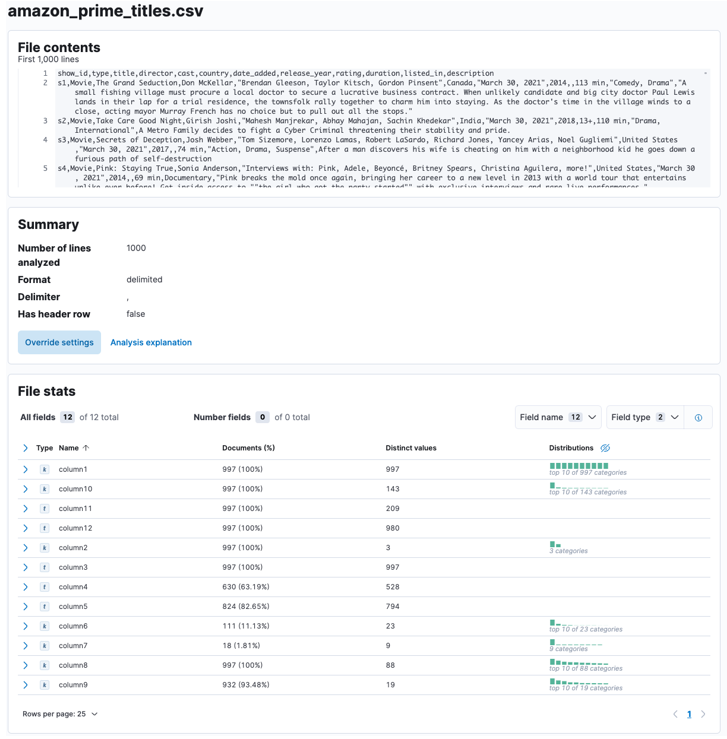
U kunt tal van parameters aanpassen, bijvoorbeeld het scheidingsteken, koptekstrijen, enz. We kunnen bijvoorbeeld de bovenstaande uitvoer aanpassen om Elastic te laten weten dat ons CSV-bestand koptekstbestanden bevat.
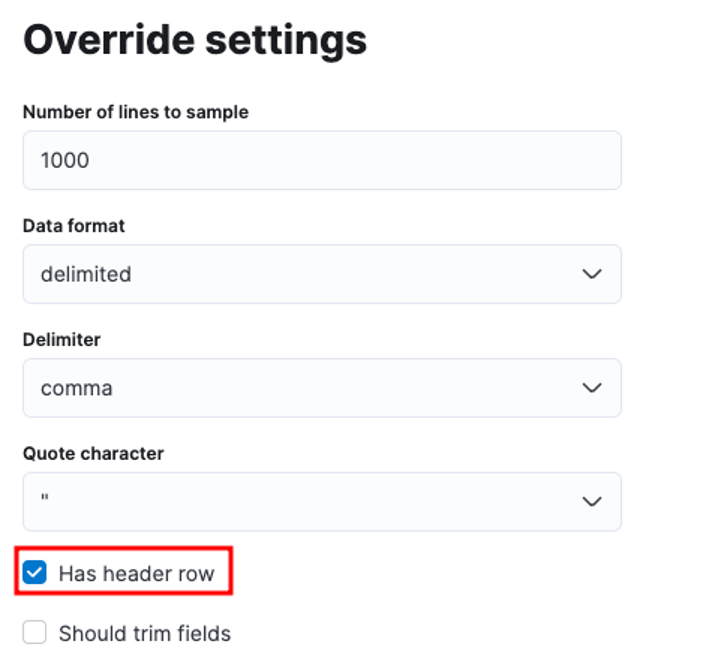
We kunnen dan op toepassen klikken en de gegevens opnieuw analyseren. Dit moet de gegevens in het juiste formaat opmaken, inclusief de velden.
Vervolgens kunnen we op importeren klikken om door te gaan naar het geïmporteerde dashboard.
Hier moeten we een index maken waarin de CSV-gegevens worden opgeslagen. U kunt elke ondersteunde naam aan uw index toewijzen.
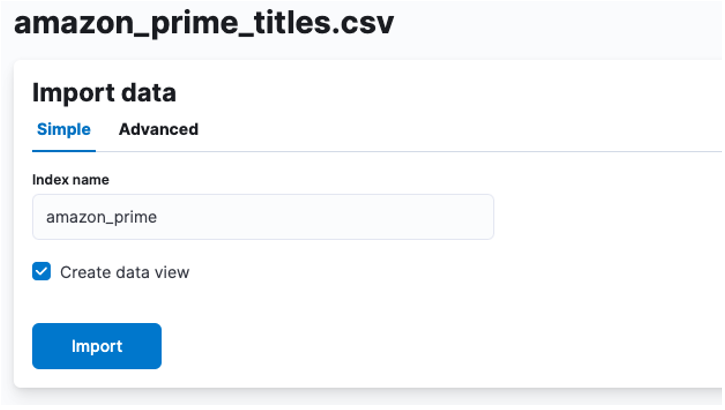
Als u uw indexeigenschappen wilt aanpassen, zoals het aantal shards, replica's, toewijzingen, enz. Selecteer de geavanceerde optie en pas uw instellingen naar wens aan.
Klik ten slotte op importeren en kijk hoe Kibana zijn 'magie' doet. Eenmaal voltooid, hebt u toegang tot uw index via Elasticsearch API of via het Kibana-dashboard.
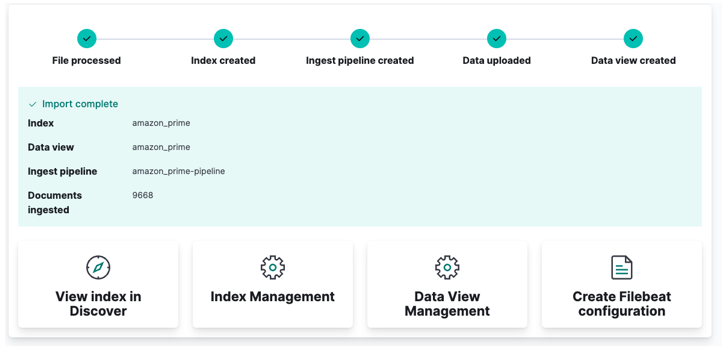
En je bent klaar!!
Conclusie
In dit bericht hebben we het proces behandeld van het ophalen en importeren van uw CSV-gegevensset in uw Elasticsearch-cluster met behulp van het Kibana-dashboard.
Bedankt voor het lezen en veel plezier met coderen!!