Elasticsearch is een robuuste, populaire oplossing om omvangrijke, ongestructureerde en semi-structurele gegevens op te slaan. Het is puur een NoSQL-database en gebruikt een totaal andere benadering om gegevens op te slaan, te beheren en op te halen. Het slaat gegevens op in een document in JSON-indeling en gebruikt rest-API's om verschillende bewerkingen op opgeslagen gegevens uit te voeren.
In deze blog laten we zien:
- Hoe Elasticsearch werkt om gegevens op te slaan en te doorzoeken?
- Wat zijn Elasticsearch-documenten?
- Gegevens opslaan in een Elasticsearch-document?
Hoe Elasticsearch werkt om gegevens op te slaan en te doorzoeken?
De belangrijkste componenten of hiërarchie van Elasticsearch die wordt gebruikt om gegevens op te slaan, wordt hieronder weergegeven:
- Document: Het document is het belangrijkste onderdeel van Elasticsearch dat gegevens opslaat in JSON-indeling. Leuk vinden
- Indexen: Indexen worden indexen genoemd. Het is een verzameling documenten. Net als in SQL wordt het een database genoemd.
- Omgekeerde indexen: Het ondersteunt zeer snel zoeken in volledige tekst. Het slaat het woord op als index en de naam van het document als referentie.
Wat zijn Elasticsearch-documenten?
Het Elasticsearch-document is een opslageenheid van gegevens in JSON-indeling. Net als in relationele databases kan naar het document worden verwezen als een tabel of een rij van een database die in een index is opgeslagen. De index kan meerdere documenten bevatten en wordt een database met meerdere tabellen genoemd. Het slaat meestal een complexe gegevensstructuur op en steriliseert de gegevens in JSON-indeling.
Bovendien kan elk document meerdere velden bevatten die ' sleutel waarde ”-paren om de gegevens op te slaan, net zoals een tabel meerdere kolommen of velden heeft in een relationele database. Vervolgens worden deze sleutel-waardeparen verondersteld te worden geïndexeerd op een manier om de documenttoewijzing te bepalen. De toewijzing definieert vervolgens het gegevenstype van het document volgens de veldgegevens zoals tekst, float, geo-punt, tijd en nog veel meer.
Elasticsearch heeft ons nooit verplicht om de indexveldstructuur vooraf te definiëren en de documenten kunnen verschillende veldstructuren in een index hebben. Als de toewijzing van het veld echter is gedefinieerd voor een specifiek gegevenstype, moeten alle Elasticsearch-documenten in een index hetzelfde toewijzingstype volgen. Ga door de volgende sectie om de werking van het document te bekijken om gegevens in Elasticsearch op te slaan.
Gegevens opslaan in een Elasticsearch-document?
Om gegevens in Elasticsearch op te slaan, moet de gebruiker eerst een index maken. Geef vervolgens de velden op om de gegevens op te slaan in het Elasticsearch-document. Doorloop voor de demonstratie de vermelde stappen.
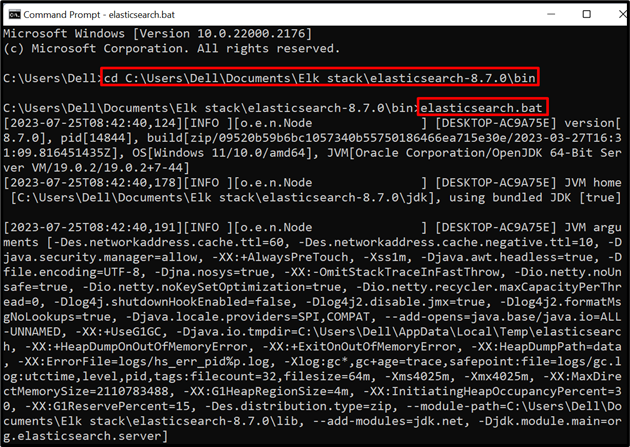
Stap 1: Start Elasticsearch
Om de Elasticsearch-database of -engine op het systeem uit te voeren, start u de systeemterminal zoals de opdrachtprompt. Bezoek daarna de “ bak ” map van Elasticsearch door de “ CD ” commando:
CD C:\Users\Dell\Documents\Elkstack\elasticsearch-8.7.0\bin
Voer daarna het batchbestand van Elasticsearch uit om de database op het systeem uit te voeren:
elasticsearch.bat
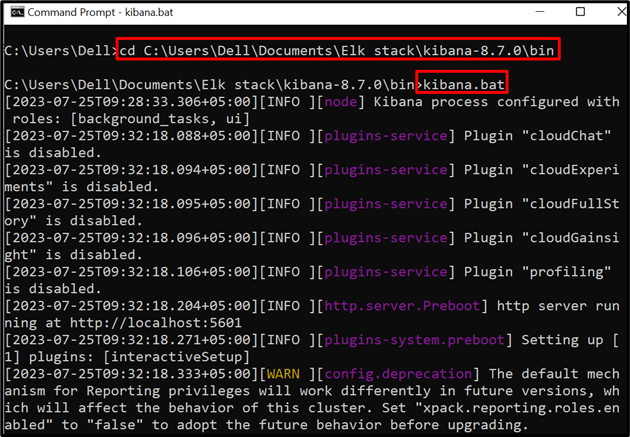
Stap 2: Start Kibana
Voer vervolgens de Kibana uit op het systeem. Bezoek hiervoor de “ bak ” map vanaf de opdrachtprompt:
CD C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Voer vervolgens de onderstaande opdracht uit om Kibana uit te voeren:
kibana.vleermuis
Opmerking: Als je Elasticsearch en Kibana niet op het systeem hebt geïnstalleerd en ingesteld, navigeer dan naar onze berichten en bekijk de stapsgewijze procedure om ze op het systeem te installeren.
Bezoek voor Elasticsearch onze “ Installeer en stel Elasticsearch in met .zip op Windows ' artikel. Om Kibana op Windows in te stellen, volgt u de ' Stel Kibana in voor Elasticsearch ' artikel.
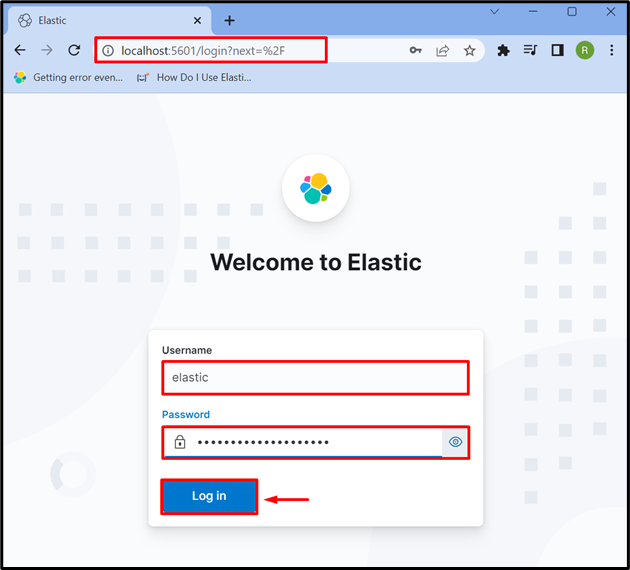
Stap 3: Log in op Kibana
Nadat je de Kibana op het systeem hebt gestart, navigeer je naar het standaardadres van Kibana ' lokalehost:5601 ' in de browser en geef de inloggegevens van Elasticsearch op, zoals ' elastisch ” gebruiker en wachtwoord. Druk daarna op de ' Log in ' knop:
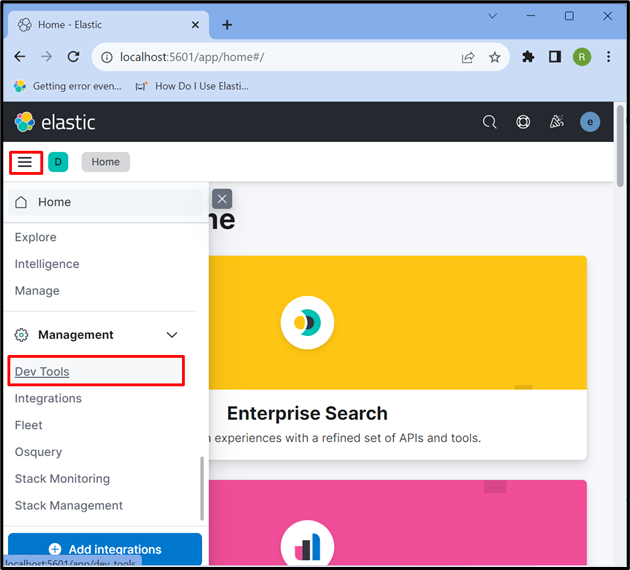
Stap 4: Open Kibana 'Dev Tool'
Klik daarna op de ' Drie horizontale balken ” pictogram en open de Kibana “ Ontwikkeltool ” om API's te gebruiken om de gegevens op te slaan, op te halen en bij te werken:
Stap 5: Index maken
Maak nu een nieuwe index met ' PUT /
De uitvoer laat zien dat de ' werknemer-gegevens ” index is succesvol gemaakt:
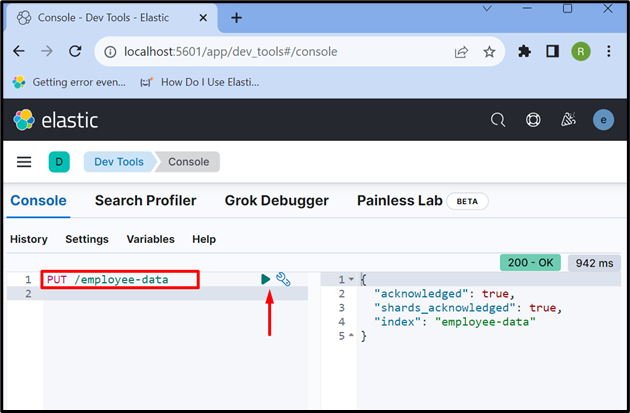
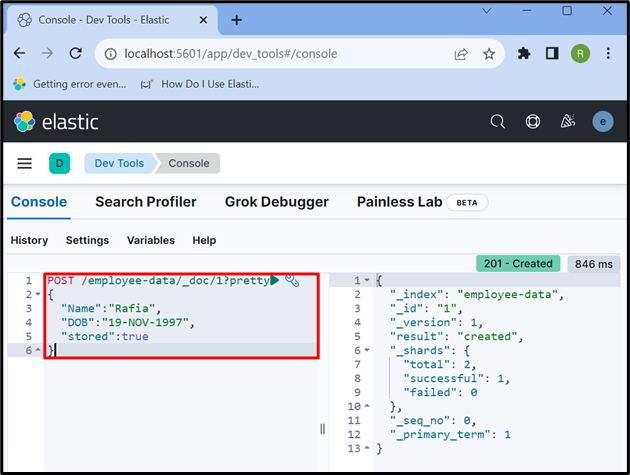
Stap 6: gegevens in document invoegen
Gebruik nu de ' NA ” API om de gegevens in de index op te slaan. In het onderstaande verzoek, ' werknemer-gegevens ” is een index van Elasticsearch, “ _doc ” wordt gebruikt om gegevens op te slaan in het Elasticsearch-document, en “ 1 ” is het identificatienummer:
NA / werknemer-gegevens / _doc / 1 ?zeer{
'Naam' : 'Raffia' ,
'DOB' : '19-NOV-1997' ,
'opgeslagen' :WAAR
}
Stap 7: gegevens ophalen uit Elasticsearch-document
Om toegang te krijgen tot de gegevens uit de index of het Elasticsearch-document, gebruikt u de KRIJGEN ”API zoals hieronder gebruikt:
KRIJGEN / werknemer-gegevens / _doc / 1 ?zeer
De uitvoer laat zien dat we met succes de gegevens hebben geëxtraheerd uit het Elasticsearch-document met id ' 1 ”:
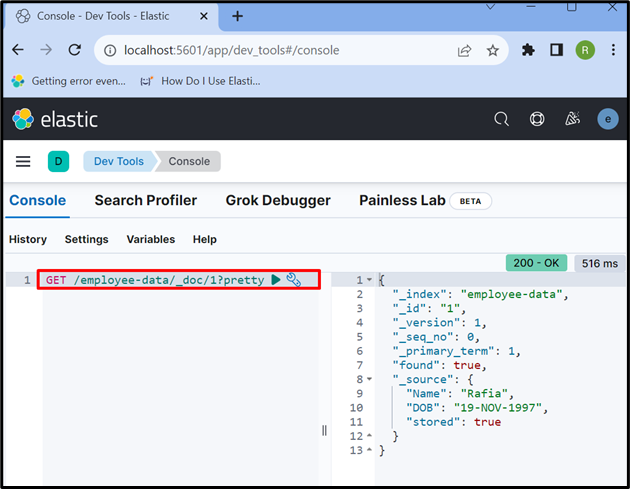
Dat is alles over het Elasticsearch-document.
Conclusie
Het Elasticsearch-document wordt meestal gebruikt om gegevens in JSON-indeling op te slaan. Net als in relationele databases kan naar het document worden verwezen als een rij die is opgeslagen in een index. Deze indexen kunnen meerdere documenten bevatten, net zoals databases verschillende tabellen hebben. Deze documenten bevatten meerdere velden die ' sleutel waarde ”-paren om de gegevens op te slaan. Dit artikel heeft gedemonstreerd wat Elasticsearch-documenten zijn en hoe ze werken in Elasticsearch.