Snel overzicht
Dit bericht zal het volgende aantonen:
- Toegang krijgen tot de tussenstappen van een agent in LangChain
- Kaders installeren
- OpenAI-omgeving instellen
- Bibliotheken importeren
- LLM en agent bouwen
- Het gebruik van de agent
- Methode 1: Standaardretourtype voor toegang tot de tussenstappen
- Methode 2: “dumps” gebruiken om toegang te krijgen tot de tussenstappen
- Conclusie
Hoe krijg ik toegang tot de tussenstappen van een agent in LangChain?
Om de agent in LangChain te bouwen, moet de gebruiker de tools en de structuur van de sjabloon configureren om het aantal stappen in het model te bepalen. De agent is verantwoordelijk voor het automatiseren van de tussenstappen zoals gedachten, acties, observaties, enz. Om te leren hoe u toegang krijgt tot de tussenstappen van een agent in de LangChain, volgt u eenvoudigweg de vermelde stappen:
Stap 1: Frameworks installeren
Installeer allereerst eenvoudig de afhankelijkheden van de LangChain door de volgende code uit te voeren in de Python Notebook:
pip installeer langchain_experimental
Installeer de OpenAI-module om de afhankelijkheden ervan op te halen met behulp van de Pip commando en gebruik ze om het taalmodel te bouwen:
pip installeer openai
Stap 2: OpenAI-omgeving instellen
Zodra de modules zijn geïnstalleerd, stelt u de OpenAI-omgeving met behulp van de API-sleutel die is gegenereerd vanuit zijn account:
importeren Jij
importeren Krijg een pas
Jij. ongeveer [ 'OPENAI_API_KEY' ] = Krijg een pas. Krijg een pas ( 'OpenAI API-sleutel:' )
Stap 3: Bibliotheken importeren
Nu we de afhankelijkheden hebben geïnstalleerd, kun je ze gebruiken om bibliotheken uit de LangChain te importeren:
van langketen. agenten importeren laad_toolsvan langketen. agenten importeren initialiseer_agent
van langketen. agenten importeren Agenttype
van langketen. llms importeren OpenAI
Stap 4: LLM en agent bouwen
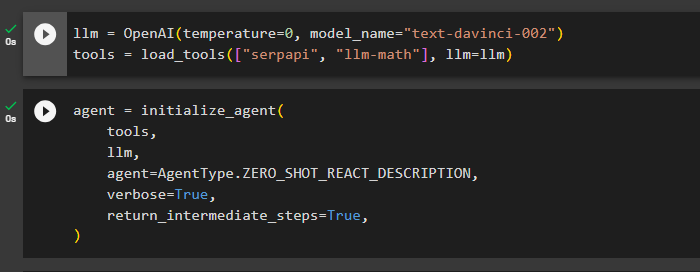
Zodra de bibliotheken zijn geïmporteerd, is het tijd om ze te gebruiken voor het bouwen van het taalmodel en de hulpmiddelen voor de agent. Definieer de llm-variabele en wijs deze toe met de OpenAI()-methode die de argumenten temperatuur en modelnaam bevat. De ' hulpmiddelen ”variabele bevat de methode load_tools() met de tools SerpAPi en llm-math en het taalmodel in zijn argument:
llm = OpenAI ( temperatuur = 0 , modelnaam = 'tekst-davinci-002' )hulpmiddelen = laad_tools ( [ 'serpapi' , 'llm-wiskunde' ] , llm = llm )
Zodra het taalmodel en de tools zijn geconfigureerd, ontwerpt u eenvoudigweg de agent om de tussenstappen uit te voeren met behulp van de tools in het taalmodel:
tussenpersoon = initialiseer_agent (hulpmiddelen ,
llm ,
tussenpersoon = Agenttype. ZERO_SHOT_REACT_DESCRIPTION ,
uitgebreid = WAAR ,
return_intermediate_steps = WAAR ,
)
Stap 5: De agent gebruiken
Stel de agent nu op de proef door een vraag te stellen in de invoer van de agent() -methode en deze uit te voeren:
antwoord = tussenpersoon ({
'invoer' : 'Wie is de vriendin van Leo DiCaprio en wat is hun leeftijdsverschil'
}
)
Het model heeft efficiënt gewerkt om de naam van de vriendin van Leo DiCaprio, haar leeftijd, de leeftijd van Leo DiCaprio en het verschil daartussen te achterhalen. De volgende schermafbeelding toont verschillende vragen en antwoorden die door de agent zijn doorzocht om tot het uiteindelijke antwoord te komen:
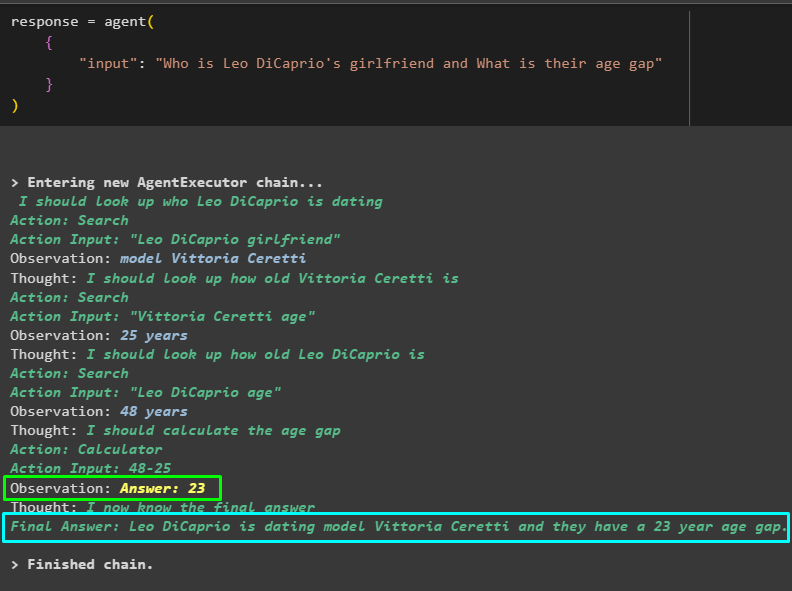
De bovenstaande schermafbeelding laat niet zien hoe de agent werkt en hoe hij in dat stadium komt om alle antwoorden te vinden. Laten we naar het volgende gedeelte gaan om de stappen te vinden:
Methode 1: Standaardretourtype voor toegang tot de tussenstappen
De eerste methode om toegang te krijgen tot de tussenstap is het gebruik van het standaard retourtype dat door de LangChain wordt aangeboden met behulp van de volgende code:
afdrukken ( antwoord [ 'tussenstappen' ] )De volgende GIF geeft de tussenstappen op één regel weer, wat niet helemaal goed is als het gaat om de leesbaarheid:

Methode 2: “dumps” gebruiken om toegang te krijgen tot de tussenstappen
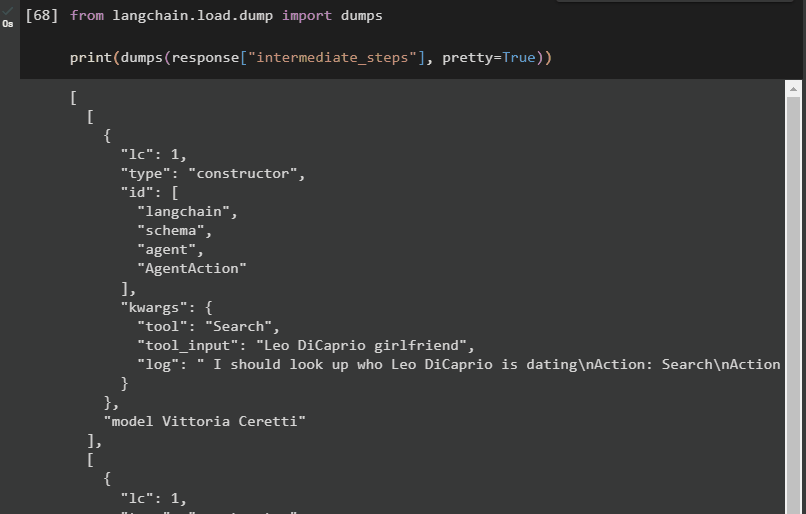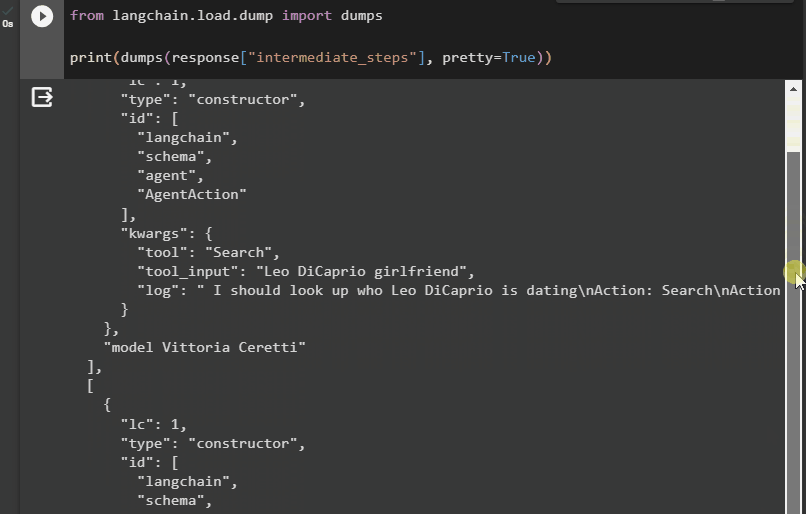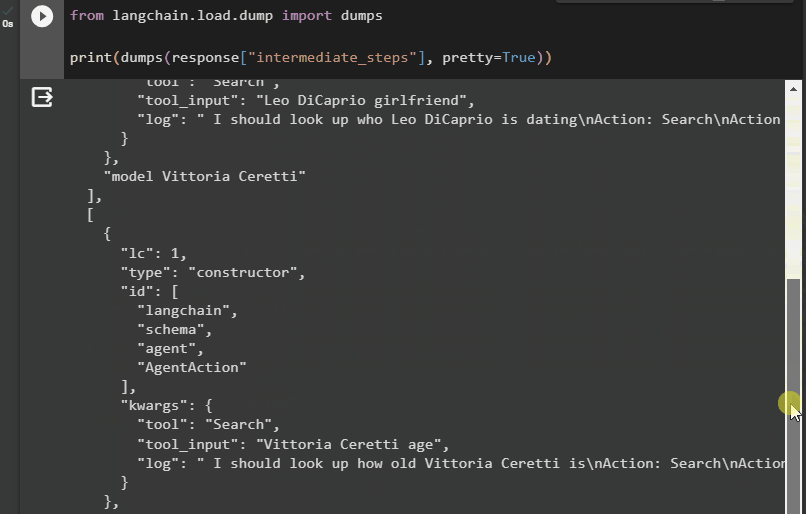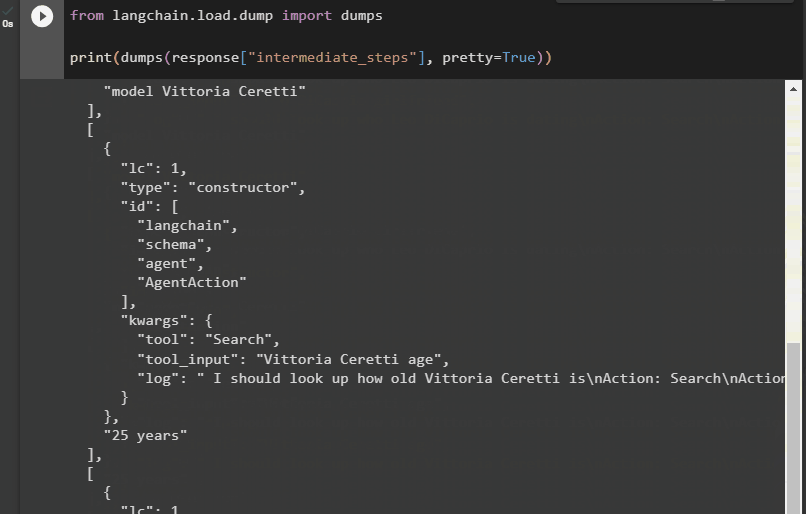
De volgende methode legt een andere manier uit om de tussenstappen te verkrijgen met behulp van de dumpbibliotheek uit het LangChain-framework. Gebruik de methode dumps() met het argument pretty om de uitvoer gestructureerder en gemakkelijker leesbaar te maken:
van langketen. laden . dumpen importeren stortplaatsenafdrukken ( stortplaatsen ( antwoord [ 'tussenstappen' ] , zeer = WAAR ) )
Nu hebben we de uitvoer in een meer gestructureerde vorm die gemakkelijk leesbaar is voor de gebruiker. Het is ook opgesplitst in meerdere secties om het logischer te maken, en elke sectie bevat de stappen om antwoorden op de vragen te vinden:
Dat draait allemaal om toegang tot de tussenstappen van een agent in LangChain.
Conclusie
Om toegang te krijgen tot de tussenstappen van een agent in LangChain, installeert u de modules om bibliotheken te importeren voor het bouwen van taalmodellen. Stel daarna tools in om de agent te initialiseren met behulp van de tools, llm en het type agent dat de vragen kan beantwoorden. Zodra de agent is geconfigureerd, test u deze om de antwoorden te krijgen en gebruikt u vervolgens de standaardtype- of dumpbibliotheek om toegang te krijgen tot de tussenstappen. In deze handleiding wordt dieper ingegaan op het proces van toegang tot de tussenstappen van een agent in LangChain.