Kiel (Knowledge Extraction based on Evolutionary Learning) is een op Java gebaseerde softwaretool die gespecialiseerd is in de implementatie van evolutionaire algoritmen. Omdat het een open source is, biedt het een breed scala aan algoritmen voor het ontdekken van kennis die kunnen worden gebruikt in experimenten die de datamining- en analysegemeenschap van stroom voorzien. Het biedt een eenvoudige en gebruiksvriendelijke grafische gebruikersinterface die de algehele complexiteit van deze tool aanzienlijk vermindert. De meeste vergelijkbare tools op de markt vereisen dat de gebruikers ermee communiceren door de code te schrijven, terwijl Keel deze vereiste verwijdert door een intuïtieve GUI te bieden die zowel door beginners als experts kan worden gebruikt.
Keel biedt een breed scala aan verschillende algoritmen op basis van computationele intelligentie, waaronder classificatie, regressie, kenmerkextractie, patroonanalyse, clustering en meer. Met reguliere modellen die rechtstreeks in de applicatie zelf zijn ingebakken, is Keel een zeer nuttige tool als het gaat om het uitvoeren van verkennende data-analyses op onbewerkte datasets. De eenvoudige interface voor slepen en neerzetten in combinatie met het gemak van het gebruik van functionaliteit zorgt voor snelle en efficiënte datamining-experimenten voor zowel educatieve als onderzoeksdoeleinden. Tools zoals Keel worden steeds populairder vanwege hun simplistische benadering van anderszins complexe algoritmische praktijken.
Installatie
Er zijn twee belangrijke manieren waarop we kunnen installeren Kiel op elke Linux-machine. De eerste houdt in dat je naar de Kiel webpagina en daar de software downloaden. De tweede, die we in deze installatiehandleiding zullen volgen, vereist dat we Keel downloaden met behulp van de wkrijg downloadtool beschikbaar voor Linux-gebruikers.
1. We beginnen met krijgen wkrijg op onze Linux-machine.
Voer de volgende opdracht uit om de wget te downloaden met behulp van de geschikt pakket manager:
$ sudo apt-get installeren wkrijg
U ziet een vergelijkbare terminaluitvoer:
2. Nu we de wkrijg tool geïnstalleerd op onze Linux-machine, gebruiken we het om het Kiel hulpmiddel.
Dit is de koppeling die we doorgeven aan wget.
Voer de volgende opdracht uit in uw terminal:
$ wkrijg http: // sci2s.ugr.es / kiel / software / prototypen / openversie / Software- 2018 -04-09.zip
U zou een vergelijkbare uitvoer op uw terminal moeten zien:
Zodra Keel klaar is met downloaden, kunnen we doorgaan met de rest van de installatie.
3. We pakken nu het gecomprimeerde bestand uit dat we in de vorige stap hebben gedownload met behulp van de Linux Unzip-tool.
Voer de volgende opdracht uit:
$ uitpakken Software- 2018 -04-09.zip
U zou een vergelijkbare uitvoer in de terminal moeten zien:
4. Navigeer naar de Keel-map door de volgende opdracht uit te voeren:
$ CD Software- 2018 -04-09 / documenten / experimenten / KIEL / afstand /
5. Voer de volgende opdracht uit om met de installatie te beginnen:
$ Java -kan . / GraphInterKeel.jar
Hiermee zou Keel voor u beschikbaar moeten zijn om op uw Linux-machine te gebruiken.
Gebruikershandleiding
Interactie met de Kiel applicatie is heel gemakkelijk en eenvoudig. Laten we beginnen met het importeren van de Iris-gegevensset in onze werkruimte.
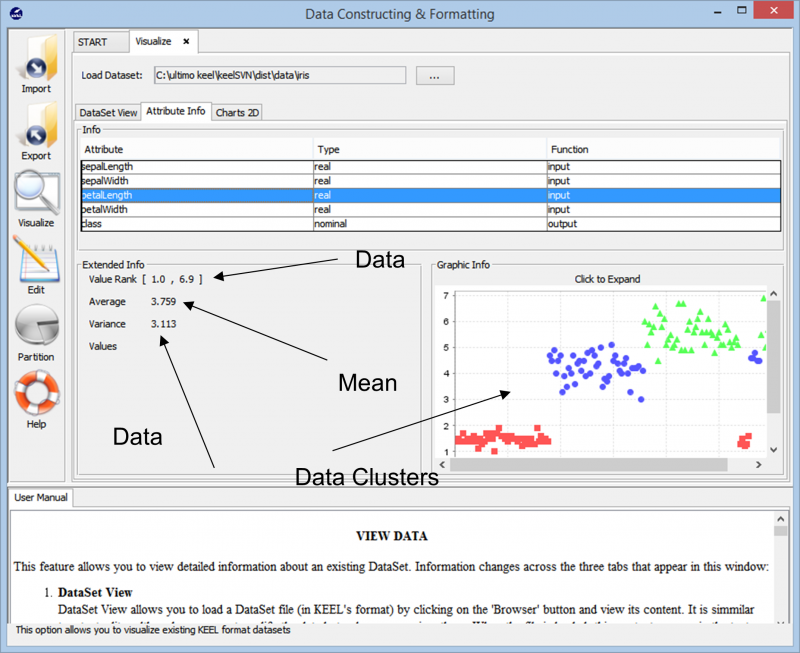
Terwijl we de gegevens importeren, toont de tool ons de algehele clustering van het datapunt in de dataset. Het toont ons ook de verschillende klassen die aanwezig zijn in de dataset, samen met de basisinformatie zoals de numerieke bereiken die deze datapunten overspannen en de algehele variantie en gemiddelde waarden die deze presenteren. Met deze informatie kunnen de gebruikers beter begrijpen hoe ze verder moeten gaan met de gegevensvoorbereiding voor elke vorm van gegevensanalysetaak.
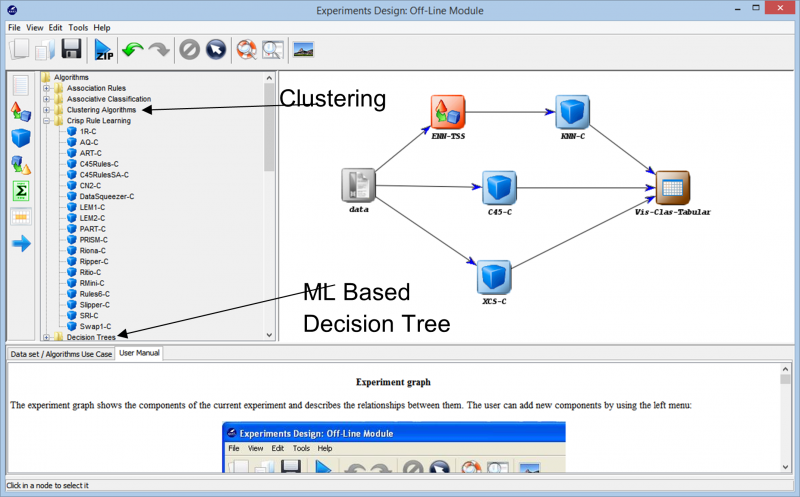
Als we verder gaan met experimenteren, komen we de verschillende technieken tegen die kunnen worden gebruikt om ons experiment op elke dataset te maken. De verschillende leeralgoritmen die op onze gegevens kunnen worden gebruikt, zijn te zien in de volgende afbeelding. Afhankelijk van de aard van de dataset en de vereisten van het experiment, kan met verschillende algoritmen worden geëxperimenteerd.
Als u bijvoorbeeld werkt met niet-gelabelde gegevens en overeenkomsten moet vinden tussen de verschillende gegevenspunten in uw gegevensset, kan het gebruik van een clusteralgoritme uit de verschillende beschikbare opties u helpen de gegevenspunten beter te begrijpen. Dit helpt u uiteindelijk om de gegevenspunten te labelen en te classificeren, zodat het experiment kan worden gebaseerd op het gebruik van uitgebreidere begeleide leeralgoritmen.
Conclusie
De Kiel platform voor data-analyse is een goede bron voor zowel onderzoeks- als educatieve doeleinden. De gebruiksvriendelijke grafische gebruikersinterface helpt de gebruikers om de vereisten van de gegevens beter te begrijpen, samen met logische verwijzingen naar nuttige technieken en algoritmen die de gebruikers verder helpen bij hun workflows. Met een breed scala aan verschillende algoritmen die onder de verschillende categorieën vallen en algoritmische technieken, kunnen gebruikers experimenteren met talloze logische richtingen en deze resultaten vergelijken, zodat de meest optimale oplossing voor elk probleem kan worden bereikt.
Keel's codevrije drag-and-drop-benadering van datamining helpt zelfs beginners om moeiteloos te werken met uitgebreide computationele intelligentiemodellen. Dit geeft inzicht in complexe datasets en leidt daaruit tot bruikbare gevolgtrekkingen die helpen bij het oplossen van de problemen in de echte wereld.