Voorbeeld 1: Haal de positie van het patroon uit de string met behulp van de Grep()-functie in R
Om de positie van het gespecificeerde patroon uit de string te extraheren, wordt de grep() functie van R gebruikt.
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, waarde=FALSE)Hier gebruiken we de functie grep() waarbij het patroon “+i” wordt gespecificeerd als een argument dat moet worden gekoppeld binnen de vector van tekenreeksen. We stellen de karaktervectoren in die vier strings bevatten. Daarna stellen we het “perl”-argument in met de TRUE-waarde, wat aangeeft dat R een perl-compatibele reguliere expressiebibliotheek gebruikt, en de “value”-parameter wordt gespecificeerd met de “FALSE”-waarde die wordt gebruikt om de indices van de elementen op te halen. in de vector die overeenkomt met het patroon.
De “+i” patroonpositie van elke reeks vectortekens wordt weergegeven in de volgende uitvoer:

Voorbeeld 2: Match het patroon met behulp van de functie Gregexpr() in R
Vervolgens halen we de indexpositie op samen met de lengte van de specifieke string in R met behulp van de functie gregexpr().
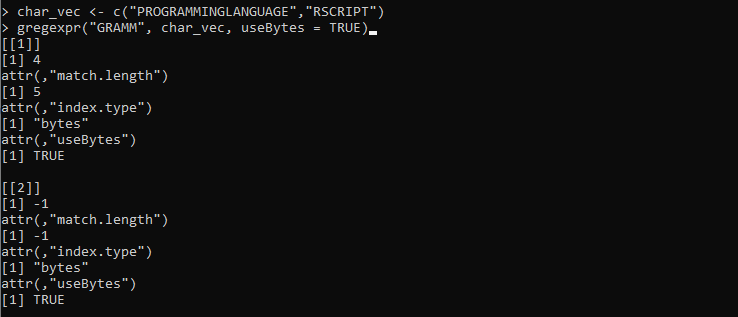
char_vec <- c('PROGRAMMEERTAAL','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = WAAR)
Hier stellen we de variabele “char_vect” in, waarbij de strings van verschillende karakters worden voorzien. Daarna definiëren we de functie gregexpr() die het stringpatroon “GRAMM” nodig heeft om te matchen met de strings die zijn opgeslagen in de “char_vec”. Vervolgens stellen we de parameter useBytes in met de waarde 'TRUE'. Deze parameter geeft aan dat de matching byte per byte moet worden gerealiseerd in plaats van karakter per karakter.
De volgende uitvoer die wordt opgehaald uit de functie gregexpr() vertegenwoordigt de indices en de lengte van beide vectortekenreeksen:
Voorbeeld 3: Tel het totale aantal tekens in een tekenreeks met behulp van de functie Nchar() in R
Met de methode nchar() die we hieronder implementeren, kunnen we ook bepalen hoeveel tekens er in de string staan:
Res <- nchar('Tel elk teken')afdrukken(onderzoek)
Hier roepen we de methode nchar() aan die is ingesteld binnen de variabele “Res”. De methode nchar() wordt geleverd met de lange tekenreeks die wordt geteld door de methode nchar() en geeft het aantal tellertekens in de opgegeven tekenreeks weer. Vervolgens geven we de variabele “Res” door aan de methode print() om de resultaten van de methode nchar() te bekijken.
Het resultaat wordt ontvangen in de volgende uitvoer, waaruit blijkt dat de opgegeven tekenreeks 20 tekens bevat:

Voorbeeld 4: Extraheer de substring uit de string met behulp van de functie Substring() in R
We gebruiken de methode substring() met de argumenten “start” en “stop” om de specifieke substring uit de string te extraheren.
str <- substring('OCHTEND', 2, 4)afdrukken(str)
Hier hebben we een “str” -variabele waarin de substring() -methode wordt aangeroepen. De methode substring() gebruikt de string “MORNING” als het eerste argument en de waarde van “2” als het tweede argument, wat aangeeft dat het tweede teken uit de string moet worden geëxtraheerd, en de waarde van het argument “4” geeft aan dat het vierde teken moet worden geëxtraheerd. De methode substring() extraheert de tekens uit de string tussen de opgegeven positie.
De volgende uitvoer toont de geëxtraheerde subtekenreeks die tussen de tweede en de vierde positie in de tekenreeks ligt:

Voorbeeld 5: Voeg de tekenreeks samen met de functie Paste() in R
De functie paste() in R wordt ook gebruikt voor tekenreeksmanipulatie, waarbij de opgegeven tekenreeksen worden samengevoegd door de scheidingstekens te scheiden.
msg1 <- 'Inhoud'msg2 <- 'Schrijven'
plakken(msg1, msg2)
Hier specificeren we de tekenreeksen voor respectievelijk de variabelen “msg1” en “msg2”. Vervolgens gebruiken we de methode paste() van R om de opgegeven tekenreeks samen te voegen tot één enkele tekenreeks. De methode paste() neemt de variabele strings als argument en retourneert de enkele string met de standaardspatie tussen de strings.
Bij de uitvoering van de methode paste() vertegenwoordigt de uitvoer de enkele string met de spatie erin.

Voorbeeld 6: Wijzig de tekenreeks met behulp van de functie Substring() in R
Bovendien kunnen we de tekenreeks ook bijwerken door de subtekenreeks of een ander teken aan de tekenreeks toe te voegen met behulp van de functie substring() met behulp van het volgende script:
str1 <- 'Helden'subtekenreeks(str1, 5, 6) <- 'ic'
cat(' Gewijzigde tekenreeks:', str1)
We stellen de string “Heroes” in binnen de variabele “str1”. Vervolgens implementeren we de methode substring() waarbij “str1” wordt opgegeven samen met de indexwaarden “start” en “stop” van de substring. De methode substring() wordt toegewezen met de substring “iz” die op de positie wordt geplaatst die is opgegeven binnen de functie voor de gegeven string. Daarna gebruiken we de cat()-functie van R die de bijgewerkte tekenreekswaarde vertegenwoordigt.
De uitvoer die de string weergeeft, wordt bijgewerkt met de nieuwe met behulp van de substring () methode:

Voorbeeld 7: Formatteer de tekenreeks met de functie Format() in R
De tekenreeksmanipulatie in R omvat echter ook het dienovereenkomstig opmaken van de tekenreeks. Hiervoor gebruiken we de functie format() waarmee de string kan worden uitgelijnd en de breedte van de specifieke string kan worden ingesteld.
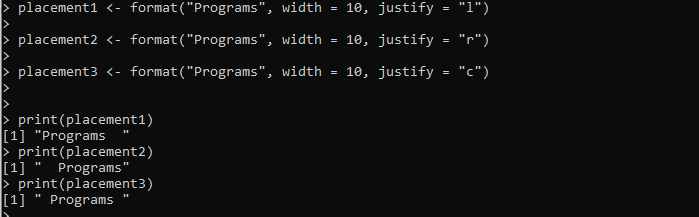
plaatsing1 <- format('Programma's', breedte = 10, uitvullen = 'l')plaatsing2 <- format('Programma's', breedte = 10, uitvullen = 'r')
plaatsing3 <- format('Programma's', breedte = 10, uitvullen = 'c')
afdrukken(plaatsing1)
afdrukken(plaatsing2)
afdrukken(plaatsing3)
Hier stellen we de variabele “placement1” in die wordt geleverd bij de format() -methode. We geven de te formatteren string “programma's” door aan de format() methode. De breedte wordt ingesteld en de uitlijning van de string wordt naar links ingesteld met behulp van het argument 'justify'. Op dezelfde manier maken we nog twee variabelen, “placement2” en “placement2”, en passen we de methode format() toe om de opgegeven tekenreeks dienovereenkomstig op te maken.
De uitvoer toont drie opmaakstijlen voor dezelfde tekenreeks in de volgende afbeelding, inclusief de uitlijning links, rechts en midden:
Voorbeeld 8: Transformeer de tekenreeks naar kleine letters en hoofdletters in R
Bovendien kunnen we de tekenreeks ook in kleine letters en hoofdletters transformeren met behulp van de functies tolower() en toupper() als volgt:
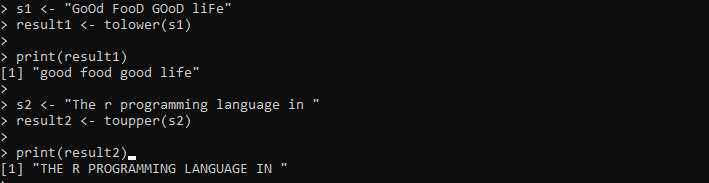
s1 <- 'Goed eten, goed leven'resultaat1 <- tolager(s1)
afdrukken(resultaat1)
s2 <- 'De r-programmeertaal in '
resultaat2 <- topper(s2)
afdrukken(resultaat2)
Hier geven we de string op die de hoofdletters en kleine letters bevat. Daarna wordt de string bewaard in de variabele “s1”. Vervolgens roepen we de methode tolower() aan en geven de string “s1” daarin door om alle tekens in de string in kleine letters te transformeren. Vervolgens drukken we de resultaten af van de methode tolower() die is opgeslagen in de variabele “result1”. Vervolgens stellen we nog een string in de variabele “s2” in, die alle tekens in kleine letters bevat. We passen de toupper()-methode toe op deze “s2”-tekenreeks om de bestaande tekenreeks naar hoofdletters te transformeren.
De uitvoer toont beide tekenreeksen in het opgegeven geval in de volgende afbeelding:
Conclusie
We leerden de verschillende manieren om de snaren te beheren en te analyseren, wat ook wel stringmanipulatie wordt genoemd. We hebben de positie van het personage uit de string gehaald, de verschillende strings aaneengeschakeld en de string naar de opgegeven naamval getransformeerd. Ook hebben we de string geformatteerd, de string aangepast en worden hier verschillende andere bewerkingen uitgevoerd om de string te manipuleren.