In deze gids worden lijstcrawlers in AWS uitgelegd.
Wat zijn lijstcrawlers in AWS?
Een crawler is een onderdeel van de AWS-lijm die wordt gebruikt om over de gegevenslocatie te kruipen en die informatie terugleidt naar de catalogus. De informatie die een crawler verzamelt, kunnen gegevenstypen van de gegevens, schemastructuur of met andere woorden, het verzamelt metagegevens zijn. Crawler kan ook worden gebruikt met de gegevenscatalogus die wordt gebruikt wanneer de gegevens binnen het Glue-ecosysteem worden verplaatst tijdens het gebruik van ETL-taken, enz.
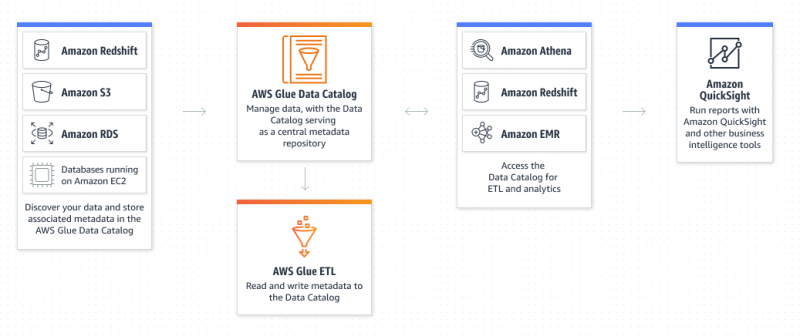
Wat is Amazon Glue-service?
AWS Glue is een Amazon Extract Transform and Load-service waarmee de gebruiker alle gegevens kan organiseren, lokaliseren, verplaatsen en transformeren. AWS Glue is serverloos omdat de gebruiker de servers niet hoeft in te richten en te configureren of levenscycli te beheren. Datacatalogus en crawlers zijn de componenten van de AWS Glue die fungeert als de persistente metadata-repository:

Hoe maak je een crawler op AWS?
Om een crawler op AWS te maken, gaat u naar de AWS Glue-service vanuit de AWS Management Console:
Ga naar de “ Kruipers '-pagina door op de naam in het linkerdeelvenster te klikken:
Klik op de ' Maak een crawler ' knop:
Typ de naam van de crawler en klik op de ' Volgende ' knop:
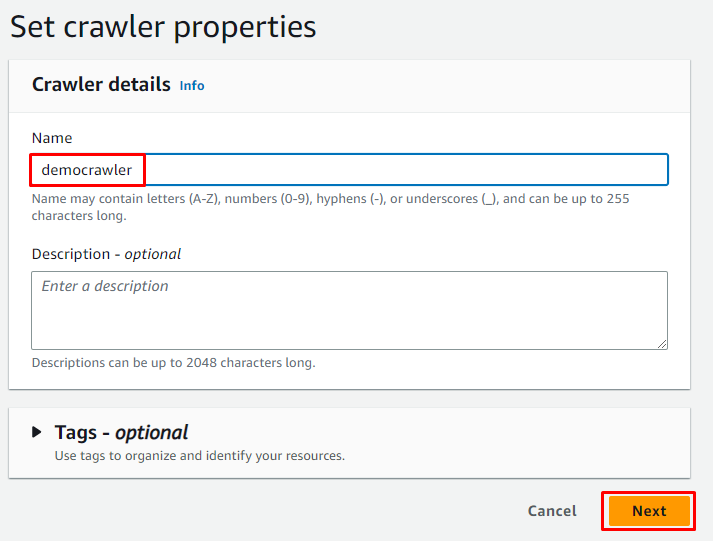
Selecteer de toewijzingsoptie voor lijmtabellen en klik op de knop ' Voeg een bron toe ”-knop om gegevens te krijgen van:

Selecteer de S3-service en klik op de ' Blader door S3 ” knop om de locatie van de bron te krijgen:

Selecteer gewoon de S3-map en klik op de ' Kiezen ' knop:

Zodra de locatie aan de bron is toegevoegd, klikt u eenvoudig op de knop ' Voeg een S3-gegevensbron toe ' knop:
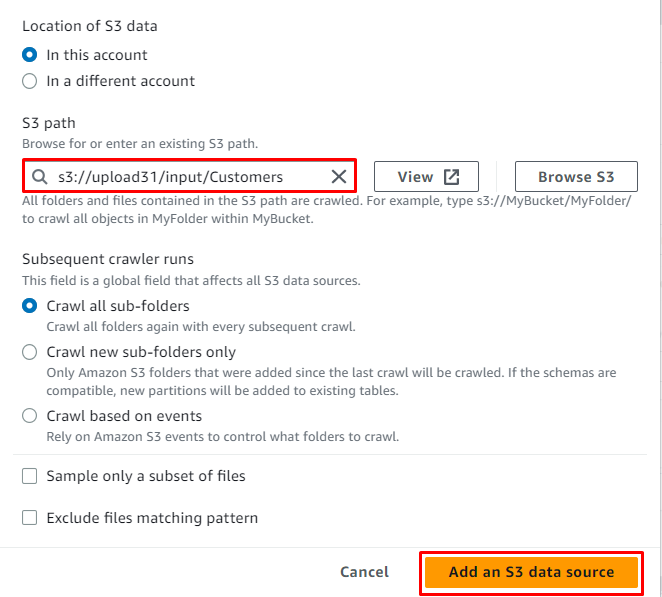
Klik op de ' Volgende ' knop:

Klik op de ' Maak een nieuwe IAM-rol aan ” knop van de “ Beveiligingsinstellingen configureren ' sectie:
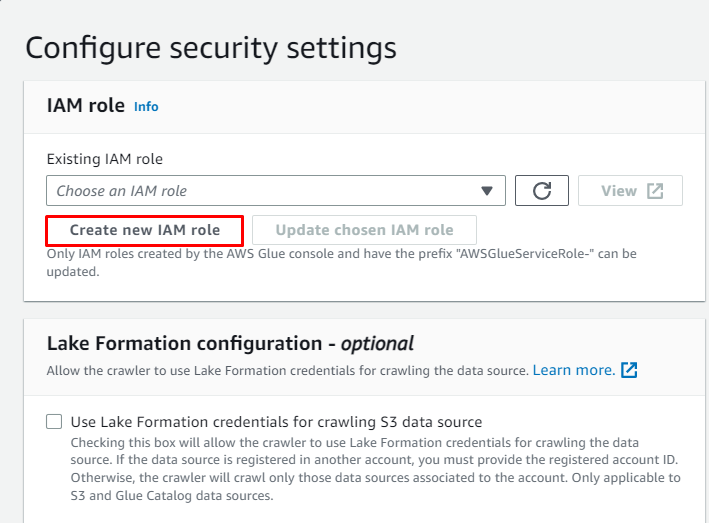
Voer de naam van de rol in en klik op de knop ' Creëren ' knop:
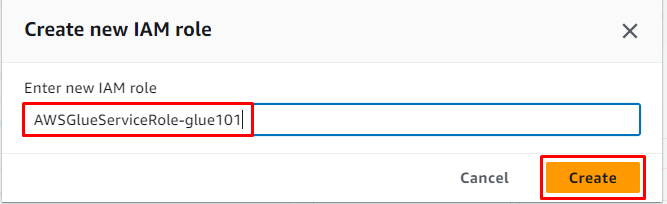
Klik daarna gewoon op de ' Volgende ' knop:

Selecteer de doeldatabase en typ de naam die voor de tabel zal worden gebruikt:
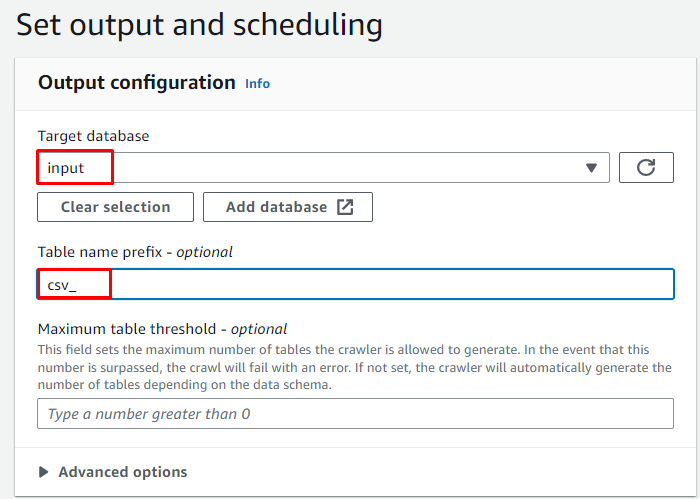
Plan de crawler voor ' Op aanvraag ' en klik op de ' Volgende ' knop:
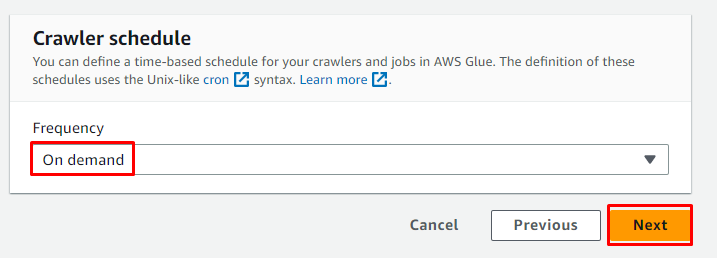
Controleer de configuratie en klik op de ' Maak een crawler ' knop:
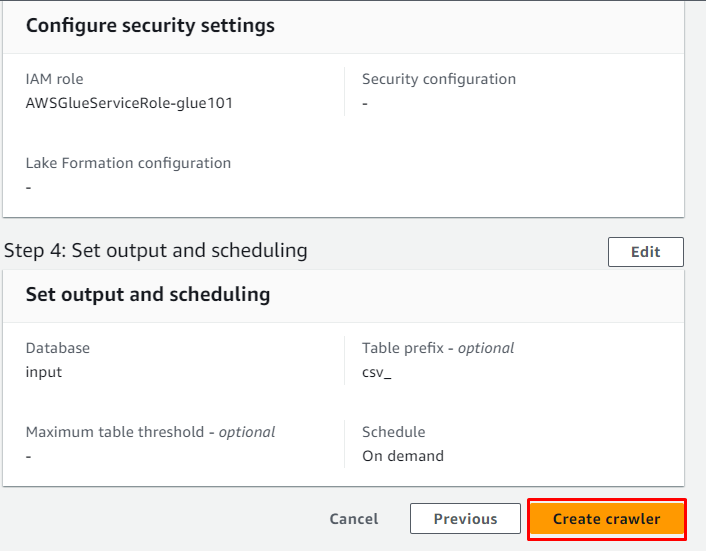
De crawler is met succes gemaakt en kan worden gebruikt om de gegevens van de bron op te halen door te klikken op de knop ' Loop ' knop:

Dat is alles over de lijstcrawlers in AWS.
Conclusie
ListCrawler is het onderdeel van de AWS Glue-service dat kan worden gebruikt om informatie uit bronnen te crawlen en terug te gaan naar de catalogus. Gegevenscatalogi en crawlers kunnen worden gebruikt om gegevens te verzamelen om informatie over de gegevens te krijgen, ook wel metagegevens genoemd. De gebruiker kan ook een crawler maken van de AWS Glue om gegevens uit de S3-service of andere bronnen te halen en maak tabellen in de database te plaatsen. Deze gids heeft de ListCrawlers in AWS uitgelegd en hoe je ze kunt maken.