Amazon Redshift is een cloudoplossing aangeboden door AWS die voldoet aan het doel van een datawarehouse. Een datawarehouse is een grote ruimte in de cloud waar enorme hoeveelheden data worden opgeslagen. Het verschil tussen een datawarehouse en een database is dat de eerste niet alleen actuele gegevens opslaat, maar ook de volledige geschiedenis van de gegevens.
Dit artikel leert over Amazon Redshift van AWS en de gegevenstypen die deze service ondersteunt.
Wat is Amazon RedShift?
Het is een cloudoplossing voor datawarehousing die is gebaseerd op 'PostgreSQL' . Het maakt gebruik van een technologie genaamd ‘Massively Parallel Processing (MPP)’ om petabytes aan data razendsnel te verwerken. Dit biedt een gemakkelijke oplossing voor real-time voorspelling op basis van historische gegevens en streamingoplossingen.
De volgende afbeelding toont het werkingsmechanisme van Amazon Redshift:
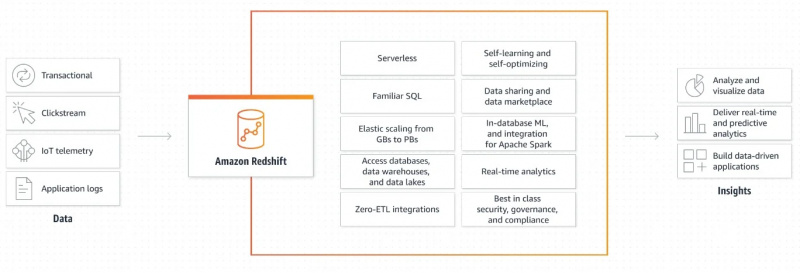
Deze grafische uitleg van hoe Amazon Redshift werkt is heel eenvoudig en duidelijk. Het geeft ons informatie over hoe gegevens worden opgehaald en verder verwerkt om output te genereren en datagestuurde toepassingen te creëren.
De datawarehouse-architectuur van Amazon Redshift is ook te zien in de onderstaande figuur:
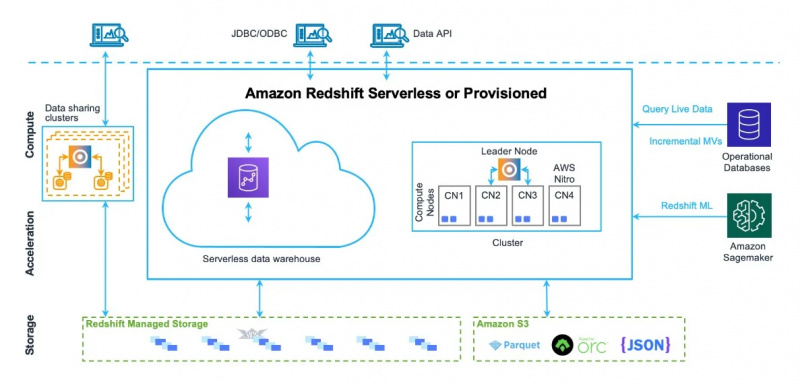
Nu gaan we naar het gebruik en de functies van deze service.
Functies
Zoals eerder vermeld, is Amazon Redshift gebaseerd op PostgreSQL en maakt het gebruik van een technologie genaamd Massively Parallel Processing waarmee het in een mum van tijd petabytes aan gegevens kan verwerken. Daarom biedt Redshift een groot aantal functies en toepassingen. Enkele van deze functies zijn hieronder:
- Gegevensbeveiliging en encryptie.
- Bedrijfsanalyse.
- Datagestuurde applicatieondersteuning.
- Voorspellende analyse.
- Geautomatiseerde taakherhaling.
- Gelijktijdige gegevensschaling.
- Data opslagplaats.
Enkele extra functies van deze service zijn te zien in de onderstaande afbeelding:
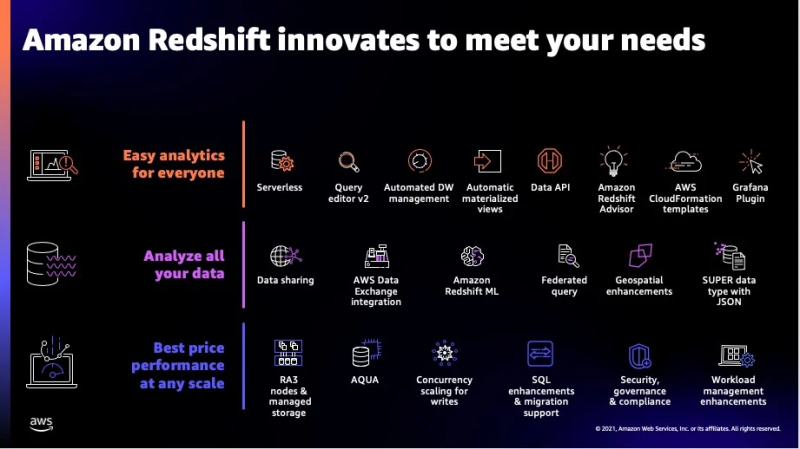
Dit waren de meeste functies die Redshift biedt en nu gaan we over op de gegevenstypen die door deze service worden ondersteund.
Gegevenstypen
Amazon Redshift is een datawarehousing-oplossing met een groot aantal functies. Het ondersteunt zowel gestructureerde als ongestructureerde gegevenstypen. Omdat het is gebaseerd op PostgreSQL, kunnen de gegevens worden gemanipuleerd door middel van eenvoudige SQL-query's.
Nu rijst een andere vraag, namelijk hoe deze gegevensformaten van elkaar verschillen? Laten we deze twee gegevensformaten bespreken.
Gestructureerde gegevens
Een zeer geformatteerd gegevenstype dat gemakkelijk kan worden vertaald door algoritmen voor machine learning, wordt gestructureerde gegevens genoemd. Een SQL-database werkt met gestructureerde gegevens. Gestructureerde gegevens zijn in tabelvorm, zoals gegevens die worden gebruikt door relationele databases
Een van de meest gebruikte SQL-databasebeheersystemen is MYSQL. De architectuur is hieronder te zien in de gegeven afbeelding:
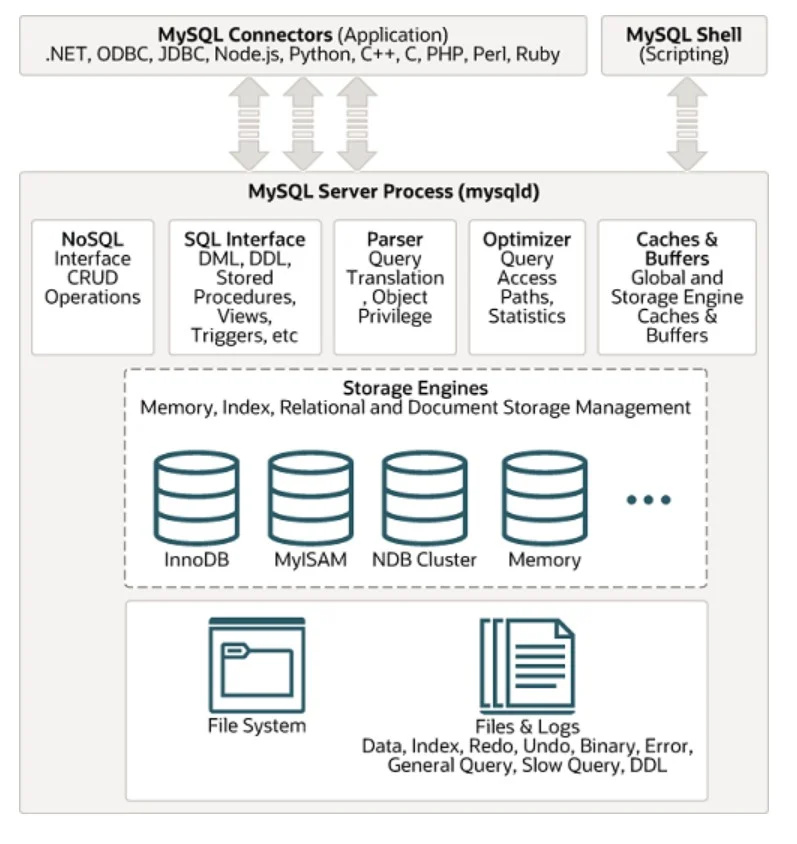
Ongestructureerde gegevens
Ongestructureerde gegevens bevatten geen patronen en vormen minder gegevens, zoals gegevens die worden gebruikt in niet-relationele databases. MongoDB is een beroemde niet-relationele database. SQL-query's werken niet op niet-relationele databases, dus deze databases worden ook wel NoSQL-databases genoemd.
Zoals eerder vermeld, is MongoDB een niet-gestructureerd databasebeheersysteem en de architectuur ervan is hieronder te zien in de gegeven afbeelding:
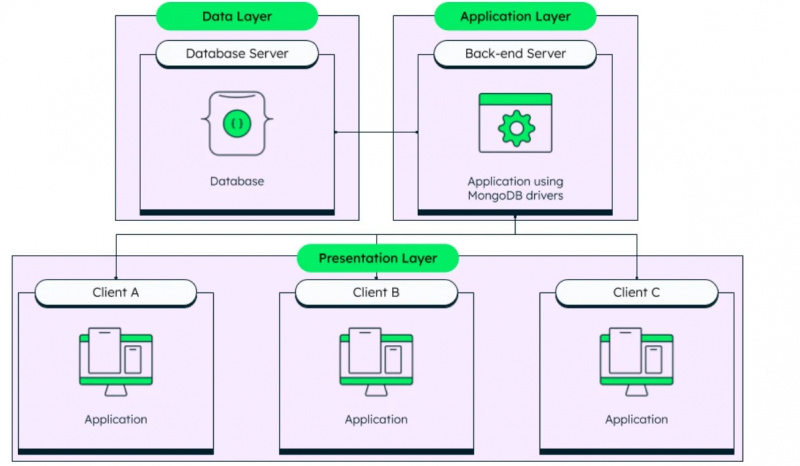
We hebben de twee fundamentele gegevenstypen doorlopen die in databases worden gebruikt en we gaan nu naar de daadwerkelijke gegevenstypen die worden ondersteund door Amazon Redshift. Deze gegevenstypen zijn:
- Numerieke gegevens
- Karakter gegevens
- Datum/tijd-gegevens
- Booleaanse gegevens
- HLLSKETCH-gegevens
- SUPER-gegevens
- VERVANGING Gegevens
Laten we deze gegevenstypen bespreken:
Numerieke gegevens
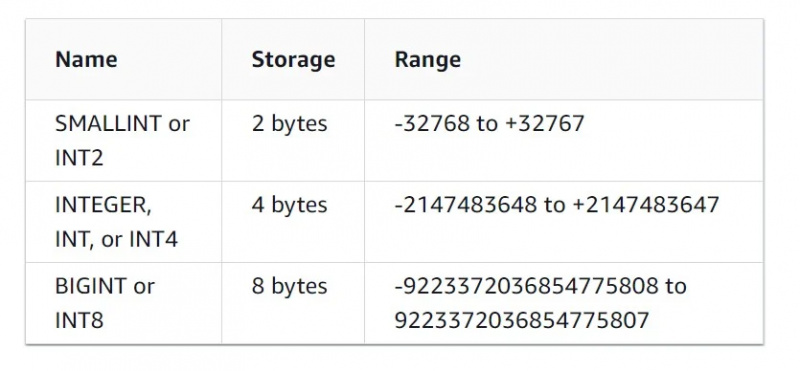
Dit gegevenstype spreekt voor zich. Het ondersteunt gegevens in de vorm van gehele getallen, decimalen, drijvende komma en andere numerieke gegevenstypen.
De kenmerken van het gegevenstype integer zijn te zien in de onderstaande afbeelding:
Decimaal gegevenstype slaat de gegevens op op basis van precisie van de gebruiker. De kenmerken zijn als volgt:

Karakter gegevens
CHAR- en VARCHAR-gegevenstypen vallen onder de categorie van op tekens gebaseerde gegevenstypen. NCHAR en NVARCHAR zijn ook gegevenstypen van het tekentype. In tegenstelling tot CHAR en VARCHAR slaan deze twee gegevenstypen Unicode-tekens met een vaste lengte op. Laten we eens kijken naar de eigenschappen van deze gegevenstypen, zoals:
- CHAR, CHARACTER, NCHAR hebben een bereik van 4KB.
- VARCHAR, NVARCHAR heeft een bereik van 64KB.
- BPCHAR heeft een bereik van 256 bytes.
- TEXT heeft een bereik van 260 bytes.
Datum/tijd-gegevens
Datetime-gegevenstypen zijn DATE, TIME, TIMETZ,TIMESTAMP, TIMESTAMPTZ. De functionele mogelijkheden van deze gegevenstypen zijn als volgt:
- DATE slaat gewoon kalenderdata op.
- TIME slaat de tijd op zonder verwijzing naar een tijdzone. Het is standaard UTC.
- TIMETZ slaat de tijd op met betrekking tot de tijdzone. Het is standaard UTC in zowel de gebruikerstabellen als de systeemtabellen.
- TIMESTAMP bevat niet alleen tijd, maar ook datums. Het is standaard UTC in zowel de gebruikerstabellen als de systeemtabellen.
- TIMESTAMPTZ bevat niet alleen tijd, maar ook datums. Het is standaard UTC in alleen gebruikerstabellen.
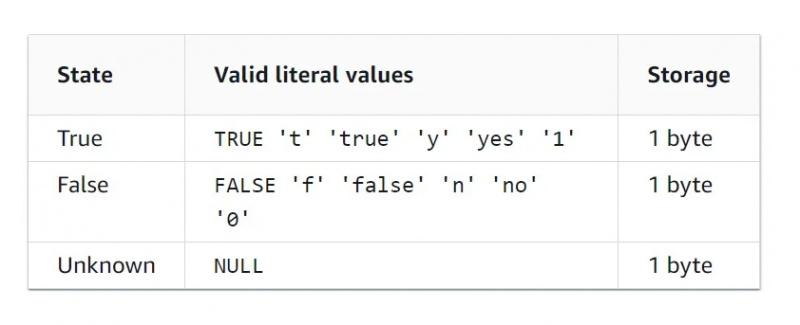
Booleaanse gegevens
Booleaans gegevenstype is een binair gegevenstype, wat betekent dat er slechts twee waarden zijn. De kenmerkentabel voor het Booleaanse gegevenstype wordt hieronder weergegeven in de afbeelding:
HLLSKETCH-gegevens
Dit gegevenstype wordt gebruikt om schetsen op te slaan. Roodverschuiving kan de schetsen in dunne of dichte vorm weergeven. Schetsen beginnen schaars en worden geleidelijk dichter wanneer een dicht formaat meer efficiëntie biedt door de link te volgen.
SUPER-gegevens
Dit gegevenstype behandelt ongestructureerde gegevens die de vorm kunnen hebben van arrays, geneste structuren of JSON. Er is geen model of formaat van de gegevens. Gebruikers kunnen meer informatie bekijken door op de link te navigeren.
VERVANGING Gegevens
Dit gegevenstype slaat ook tekens op. De lengte is echter beperkt. Amazon Redshift maakt het casten van VARBYTE-gegevens naar gegevens van elk type geheel getal of teken mogelijk. Volg de onderstaande link voor meer informatie over dit datatype.
Dit is alles wat er is voor Amazon Redshift en de gegevenstypen die het ondersteunt.
Conclusie
Amazon Redshift is een AWS-service die in zijn basisvorm het doel van een datawarehouse dient, maar een zeer krachtige en functionele oplossing is voor analyse en voorspelling. Dit artikel heeft Redshift besproken en de gegevenstypen die het ondersteunt. Deze gegevenstypen werden kort toegelicht met hun kenmerken.