XML lezen in C#
Er zijn verschillende manieren om een XML-bestand in C# te lezen en elke methode heeft zijn voor- en nadelen, en de keuze hangt af van de vereisten van het project. Hieronder staan enkele manieren om een XML-bestand in C# te lezen:
- XmlDocument gebruiken
- XDocument gebruiken
- XmlReader gebruiken
- Xml gebruiken voor LINQ
- XPath gebruiken
Hier is de inhoud van het XML-bestand dat ik heb gemaakt en zal worden gebruikt voor demonstratie in komende methoden:
< ?xml versie = '1.0' codering = 'utf-8' ? >
< medewerkers >
< medewerker >
< ID kaart > 1 ID kaart >
< naam > Sam bos naam >
< afdeling > Marketing afdeling >
< salaris > 50000 salaris >
medewerker >
< medewerker >
< ID kaart > 2 ID kaart >
< naam > Jane Doe naam >
< afdeling > Financiën afdeling >
< salaris > 60000 salaris >
medewerker >
< medewerker >
< ID kaart > 3 ID kaart >
< naam > Jacobus naam >
< afdeling > Personeelszaken afdeling >
< salaris > 70000 salaris >
medewerker >
medewerkers >
1: XmlDocument gebruiken
Om een XML-bestand in C# te lezen, kunt u de klasse XmlDocument of de klasse XDocument gebruiken, die beide deel uitmaken van de naamruimte System.Xml. De XmlDocument-klasse biedt een DOM-benadering (Document Object Model) voor het lezen van XML, terwijl de XDocument-klasse een LINQ-benadering (Language-Integrated Query) biedt. Hier is een voorbeeld waarbij de klasse XmlDocument wordt gebruikt om een XML-bestand te lezen:
systeem gebruiken;
met behulp van System.Xml;
klasse programma
{
statische leegte Main ( snaar [ ] argumenten )
{
XmlDocument-document = nieuw XmlDocument ( ) ;
doc.Laden ( 'medewerkers.xml' ) ;
XmlNodeList-knooppunten = doc.DocumentElement.SelectNodes ( '/werknemers/werknemer' ) ;
voor elk ( XmlNode-knooppunt in knooppunten )
{
snaar ID kaart = knooppunt.SelectSingleNode ( 'ID kaart' ) .InnerTekst;
tekenreeksnaam = knooppunt.SelectSingleNode ( 'naam' ) .InnerTekst;
tekenreeks afdeling = node.SelectSingleNode ( 'afdeling' ) .InnerTekst;
string salaris = node.SelectSingleNode ( 'salaris' ) .InnerTekst;
Console.WriteLine ( 'ID: {0}, Naam: {1}, Afdeling: {2}, Salaris: {3}' , ID kaart , naam, afdeling, salaris ) ;
}
}
}
Deze code gebruikt de klasse XmlDocument om het XML-bestand te laden en de methode SelectNodes om een lijst met werknemersknooppunten op te halen. Vervolgens gebruikt het voor elk werknemersknooppunt de SelectSingleNode-methode om de waarden van de onderliggende id-, naam-, afdelings- en salarisknooppunten op te halen en deze weer te geven met Console.WriteLine:

2: XDocument gebruiken
U kunt ook de XDocument-klasse gebruiken om een XML-bestand te lezen met behulp van een LINQ-benadering, en hieronder staat de code die illustreert hoe u dit moet doen:
systeem gebruiken;klasse programma
{
statische leegte Main ( snaar [ ] argumenten )
{
XDocument doc = XDocument.Laden ( 'medewerkers.xml' ) ;
voor elk ( XElement-element in doc.Afstammelingen ( 'medewerker' ) )
{
int ID kaart = int.Ontleden ( element.Element ( 'ID kaart' ) .Waarde ) ;
tekenreeksnaam = element.Element ( 'naam' ) .Waarde;
tekenreeks afdeling = element.Element ( 'afdeling' ) .Waarde;
int salaris = int.Parse ( element.Element ( 'salaris' ) .Waarde ) ;
Console.WriteLine ( $ 'ID: {id}, Naam: {naam}, Afdeling: {afdeling}, Salaris: {salaris}' ) ;
}
}
}
Het XML-bestand wordt in een XDocument-object geladen met de methode XDocument.Load. De 'werknemer' -elementen van het XML-bestand worden vervolgens allemaal opgehaald met behulp van de Descendants-techniek. Voor elk element worden de onderliggende elementen benaderd met behulp van de Element-methode en hun waarden worden geëxtraheerd met behulp van de Value-eigenschap. Ten slotte worden de geëxtraheerde gegevens naar de console afgedrukt.
Merk op dat XDocument tot de naamruimte System.Xml.Linq behoort, dus u moet de volgende using-instructie bovenaan uw C#-bestand opnemen

3: XMLReader gebruiken
XmlReader is een snelle en efficiënte manier om een XML-bestand in C# te lezen. Het leest het bestand sequentieel, wat betekent dat het slechts één knooppunt tegelijk laadt, waardoor het ideaal is voor het werken met grote XML-bestanden die anders moeilijk te verwerken zouden zijn in het geheugen.
systeem gebruiken;met behulp van System.Xml;
klasse programma
{
statische leegte Main ( snaar [ ] argumenten )
{
gebruik makend van ( XmlReader-lezer = XmlReader.Create ( 'medewerkers.xml' ) )
{
terwijl ( reader.Read ( ) )
{
als ( reader.NodeType == XmlNodeType.Element && lezer.Naam == 'medewerker' )
{
Console.WriteLine ( 'ID KAART: ' + reader.GetAttribute ( 'ID kaart' ) ) ;
reader.ReadToDescendant ( 'naam' ) ;
Console.WriteLine ( 'Naam: ' + lezer.ReadElementContentAsString ( ) ) ;
reader.ReadToNextSibling ( 'afdeling' ) ;
Console.WriteLine ( 'Afdeling: ' + lezer.ReadElementContentAsString ( ) ) ;
reader.ReadToNextSibling ( 'salaris' ) ;
Console.WriteLine ( 'Salaris: ' + lezer.ReadElementContentAsString ( ) ) ;
}
}
}
}
}
In dit voorbeeld gebruiken we XmlReader.Create een methode om een instantie van XmlReader te maken en het XML-bestandspad als parameter door te geven. Vervolgens gebruiken we een while-lus om het XML-bestand knooppunt voor knooppunt te lezen met behulp van de Read-methode van XmlReader.
Binnen de lus controleren we eerst of het huidige knooppunt een werknemerselement is met behulp van de eigenschappen NodeType en Name van XmlReader. Als dat het geval is, gebruiken we de GetAttribute-methode om de waarde van het id-attribuut op te halen.
Vervolgens gebruiken we de methode ReadToDescendant om de lezer naar het name-element in het employee-element te verplaatsen. De waarde van het naamelement wordt vervolgens verkregen met behulp van de functie ReadElementContentAsString.
Op dezelfde manier gebruiken we de ReadToNextSibling-methode om de lezer naar het volgende broer of zus-element te verplaatsen en de waarde van afdelings- en salariselementen te krijgen.
Ten slotte gebruiken we het gebruik van een blok om ervoor te zorgen dat het XmlReader-object op de juiste manier wordt verwijderd nadat we het XML-bestand hebben gelezen:
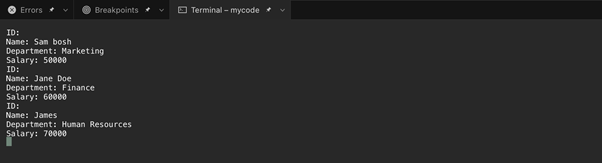
4: XML naar LINQ
Het lezen van een XML-bestand met behulp van LINQ naar XML in C# is een krachtige manier om toegang te krijgen tot XML-gegevens en deze te manipuleren. LINQ to XML is een onderdeel van de LINQ-technologie die een eenvoudige en efficiënte API biedt voor het werken met XML-gegevens.
systeem gebruiken;met behulp van System.Linq;
met behulp van System.Xml.Linq;
klasse programma
{
statische leegte Main ( snaar [ ] argumenten )
{
XDocument doc = XDocument.Laden ( 'medewerkers.xml' ) ;
var werknemers = van e in doc.Afstammelingen ( 'medewerker' )
selecteren nieuw
{
Id = e.Element ( 'ID kaart' ) .Waarde,
Naam = e.Element ( 'naam' ) .Waarde,
Afdeling = e.Element ( 'afdeling' ) .Waarde,
Salaris = e.Element ( 'salaris' ) .Waarde
} ;
voor elk ( var medewerker in medewerkers )
{
Console.WriteLine ( $ 'Id: {employee.Id}, Naam: {employee.Name}, Afdeling: {employee.Department}, Salaris: {employee.Salary}' ) ;
}
}
}
In deze code laden we eerst het XML-bestand met de methode XDocument.Load(). Vervolgens gebruiken we LINQ to XML om de XML-gegevens op te vragen en de id-, naam-, afdelings- en salariselementen voor elk werknemerselement te selecteren. We slaan deze gegevens anoniem op en doorlopen vervolgens de resultaten om de werknemersinformatie naar de console af te drukken.

5: XPath gebruiken
XPath is een querytaal die wordt gebruikt om door een XML-document te navigeren om specifieke elementen, attributen en knooppunten te lokaliseren. Het is een effectief hulpmiddel voor het zoeken en filteren van informatie in een XML-document. In C# kunnen we de XPath-taal gebruiken om gegevens uit XML-bestanden te lezen en te extraheren.
systeem gebruiken;met behulp van System.Xml.XPath;
met behulp van System.Xml;
klasse programma
{
statische leegte Main ( snaar [ ] argumenten )
{
XmlDocument-document = nieuw XmlDocument ( ) ;
doc.Laden ( 'medewerkers.xml' ) ;
// Maak een XPathNavigator van het document
XPathNavigator nav = doc.CreateNavigator ( ) ;
// Compileer de XPath-expressie
XPathExpressie uitdr = nav.Compileer ( '/werknemers/werknemer/naam' ) ;
// Evalueer de uitdrukking en herhaal de resultaten
XPathNodeIterator iterator = nav.Select ( uitdr ) ;
terwijl ( iterator.MoveNext ( ) )
{
Console.WriteLine ( iterator.Huidige.waarde ) ;
}
}
}
Deze code laadt het bestand 'employees.xml' met behulp van een XmlDocument, maakt een XPathNavigator van het document en compileert een XPath-expressie om alle

Opmerking: het gebruik van XPath kan een krachtige en flexibele manier zijn om elementen en attributen uit een XML-document te selecteren, maar het kan ook complexer zijn dan sommige van de andere methoden die we hebben besproken.
Conclusie
Het gebruik van de XmlDocument-klasse biedt volledige DOM-manipulatiemogelijkheden, maar kan langzamer zijn en meer geheugenintensief dan de andere methoden. De XmlReader-klasse is een goede optie voor het lezen van grote XML-bestanden, omdat het een snelle, alleen-voorwaartse en niet-gecachete stream-gebaseerde aanpak biedt. De klasse XDocument biedt een eenvoudigere en beknoptere syntaxis, maar is mogelijk niet zo performant als de XmlReader. Bovendien bieden de methoden LINQ naar XML en XPath krachtige querymogelijkheden om specifieke gegevens uit een XML-bestand te extraheren.