'De 'Panda's' is een geweldige taal voor het uitvoeren van de analyse van gegevens vanwege het geweldige ecosysteem van gegevensgerichte python-pakketten. Dat maakt het analyseren en importeren van beide factoren eenvoudiger. De standaarddeviatie is een 'typische' afwijking afgeleid van het gemiddelde. Het wordt veel gebruikt, omdat het de oorspronkelijke maateenheden van het dataframe retourneert. De panda's gebruikten std() voor de berekening van de standaarddeviatie. De standaarddeviatie kan worden berekend uit de gegeven waarden die in het dataframe kunnen staan in de vorm van een rij of kolom. We zullen alle mogelijke manieren implementeren waarop de standaarddeviatie van panda's wordt gebruikt. Voor de implementatie van de code zullen we de tool 'spyder' gebruiken zoals deze is geschreven in een python-vriendelijke omgeving.'
Syntaxis
“df.std ( ) ”
De volgende syntaxis wordt gebruikt voor het berekenen van de standaarddeviatie in het dataframe. De “df” in het dataframe is de afkorting van het “dataframe”. Wat doet de standaarddeviatie? Het meet hoe uitgebreid de benodigde gegevens zijn. Hoe meer uitgebreide hoge waarden, hoe hoger de standaarddeviatie zou moeten voorkomen.
Opbrengst
De standaarddeviatie van panda's retourneert het dataframe als het niveau is opgegeven op basis van de vereiste.
Merk op dat de functie 'std()' automatisch de 'NaN' -waarden in de 'df' negeert tijdens het berekenen van de standaarddeviatie van de panda's. 'NaN' kan worden uitgelegd als 'geen getal', wat betekent dat er geen waarde is toegewezen aan een bepaald.
Hieronder volgen de methoden die zullen worden uitgevoerd met voorbeelden van de standaarddeviatie van de panda's:
-
- Panda's standaarddeviatieberekening in een enkele kolom.
- Panda's standaarddeviatieberekening in meerdere kolommen.
- Panda's standaarddeviatieberekening van alle numerieke kolommen.
- panda's standaarddeviatie met behulp van de as = 1.
- panda's standaarddeviatie met behulp van de as = 0.
Het dataframe maken voor de berekening van de standaarddeviatie in panda's
Open eerst de 'spyder' -software. Importeer nu de panda-bibliotheek als pd. We zullen een dataframe maken dat bestaat uit een scorebord met termen als 'x', 'y' en 'z' met hun punten als '22', '10', '11', '16', '12', '45 ”, “36” en “40”. We hebben hun assists-waarden als '8', '9', '13', '7', '22', '24', '4' en '6', met de waarde van rebounds als '17', ' 14”, “3”, 5”, “9”, “8”, “7” en “4”.
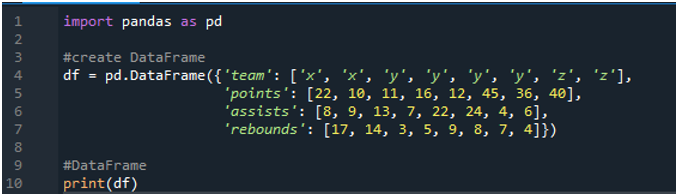
De displays tonen het gecreëerde dataframe volgens de waarden die in de code zijn toegewezen:

Voorbeeld # 01: Berekening van de standaarddeviatie van panda's in een enkele kolom
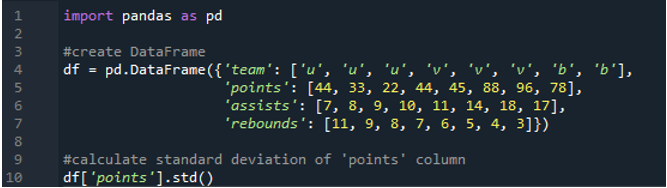
In dit voorbeeld berekenen we de standaarddeviatie van een enkele kolom in het panda-dataframe. Het dataframe heeft de waarden van het team als 'u', 'v' en 'b' met hun punten als '44', '33', '22', '44', '45', '88', '96 ” en “78”. De waarden van assists zijn als '7', '8', '9', '10', '11', '14', '18' en '17' en hebben ook de waarden van rebounds als '11', ' 9”, “8”, “7”, “6”, “5”, “4” en “3”. De kolom 'punten' wordt geselecteerd uit het dataframe om de standaarddeviatie van één kolom te berekenen.
De uitvoer toont de berekende standaarddeviatie van de kolom 'punten':

Voorbeeld # 02: Berekening van de standaarddeviatie van panda's in meerdere kolommen
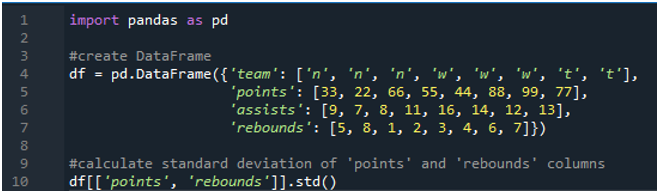
In dit voorbeeld zullen we de standaarddeviatieberekeningen van de panda's in meerdere kolommen uitvoeren. In dit dataframe zijn de gegevens opnieuw van het sportscorebord met de waarden van het team als 'n', 'w' en 't' met de score als '33', '22', '66', '55', “44”, “88”, “99” en “77”. De assists als '9', '7', '8', '11', '16', '14', '12' en '13' en rebounds als '5', '8', '1', ' 2”, “3”, “4”, “6” en “7”. Hier zullen we de standaarddeviatie van de twee kolommen 'punten' en 'rebounds' berekenen met behulp van de functie std() toegepast op het dataframe.
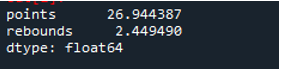
Zoals we zien, laat de uitvoer zien dat de standaarddeviatie respectievelijk 26,944387 in de puntenkolom en 2,449490 in de rebound-kolom was.
Voorbeeld # 03: Berekening van de standaarddeviatie van panda's van alle numerieke kolommen
Nu hebben we geleerd hoe we de standaarddeviatie van enkele en meerdere rijen kunnen berekenen. Wat als we niet alle kolomnamen in het dataframe willen specificeren en het hele dataframe willen berekenen? Dit is mogelijk met slechts een eenvoudige functie-implementatie van de standaarddeviatie van de panda's voor de berekening van het volledige dataframe in de resultaten. Het dataframe bestaat hier uit 'l', 'm' en 'o' met de scorewaarden '33', '36', '79', '78', '58', '55', en twee teams scoren hetzelfde dat is '25'. De assists zijn als '1', '2', '3', '4', '6', '9', '5' en '7' en hun rebounds als '14', '10', '2' , “5”, “8”, “3”, “6” en “9”. We kunnen alle standaard kolomafwijkingen door panda's in het dataframe berekenen met behulp van de panda's 'std()' -functie.
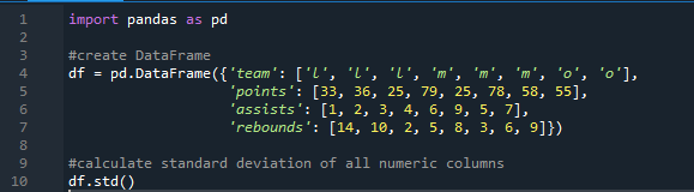
Het display heeft de berekende standaarddeviatie van de hele 'df' die hieronder wordt weergegeven; we kunnen ook opmerken dat de panda's de standaarddeviatie van de eerste kolom, die 'team' is, niet hebben berekend omdat het geen numerieke kolom is.
Voorbeeld # 04: Standaarddeviatie van panda's met behulp van de as = 0
In dit voorbeeld hebben de dataframes de teams van de sporten als 'g', 'h' en 'k' met verdere gegevens. Hier zullen we de standaarddeviatie berekenen door de as te gebruiken als '0', een parameter die wordt gebruikt in de standaarddeviatie van de panda's. Dit argument berekent kolomsgewijs de standaarddeviatie van het dataframe.
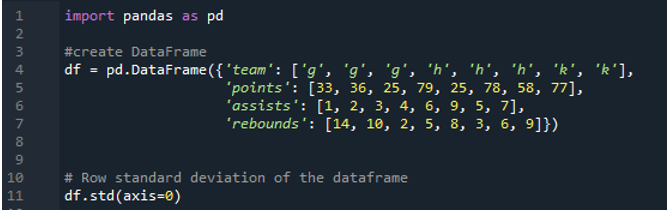
De volgende uitvoer toont de resultaten in kolommen van de berekende standaarddeviatie. De puntenkolom heeft de berekende standaarddeviatie als '24.0313062', de kolom Assists heeft de berekende standaarddeviatie als '2.669270' en de berekende standaarddeviatie van de reboundkolom wordt weergegeven als '3.943802'.
Voorbeeld # 05: Standaarddeviatie van panda's met behulp van de as = 1
Hier zullen we de asparameter gebruiken die is toegewezen als '1' om de standaarddeviatie in panda's te berekenen. Welk verschil kan as “1” maken? Het asargument '1' berekent de rijgewijze standaarddeviatie van de numerieke waarden in het dataframe. Het dataframe heeft de drie teams als 's', 'd' en 'e', met de toevoeging van gegevenskolommen die zijn gemaakt als punten van het team, assists van het team en rebounds van het team. Aanwijzingen zijn allemaal toegewezen met verschillende waarden in het dataframe. Deze asparameter is zo'n game-wisselaar dat we tegen de tijd moeten werken aan de gegevens waar we ze willen hebben in een kolom plus punt berekend op basis van uitgevoerde standaarddeviatie.
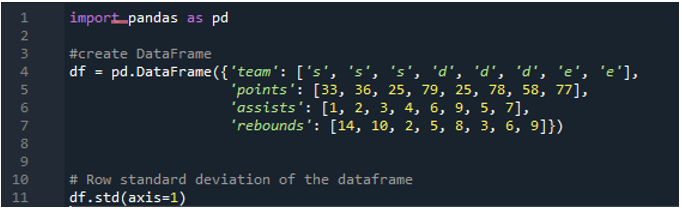
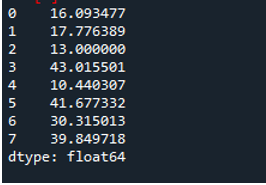
De volgende uitvoer geeft de standaarddeviatie weer die is berekend in een rij van het dataframe:
Conclusie
De standaarddeviatie van panda's is een zeer technische functie, wat een zeer nuttige functie is omdat het de standaarddeviatie vindt van het enthousiasmepact van panda's-dataframes. In dit hoofdartikel hebben we de methoden bestudeerd voor het berekenen van de standaarddeviatie bij panda's. We hebben berekeningen met één kolom gedaan van de standaarddeviatie en meerdere kolommen en hebben ook de standaarddeviatie van het hele dataframe samen berekend. Alle strategieën werken goed zolang ze consistent en met de gewenste resultaten worden gebruikt.