Dit bericht behandelt de PostgreSQL-partitionering. We bespreken de verschillende partitieopties die u kunt gebruiken en geven voorbeelden van hoe u deze kunt gebruiken voor een beter begrip.
Hoe de PostgreSQL-partities te maken
Elke database kan talloze tabellen met meerdere vermeldingen bevatten. Voor eenvoudig beheer moet u de tabellen partitioneren, wat een geweldige en aanbevolen datawarehouse-routine is voor database-optimalisatie en om de betrouwbaarheid te vergroten. U kunt verschillende partities maken, waaronder de lijst, het bereik en de hash. Laten we ze allemaal in detail bespreken.
1. Lijst met partities
Voordat we een partitie overwegen, moeten we de tabel maken die we voor de partities gaan gebruiken. Volg bij het maken van de tabel de gegeven syntaxis voor alle partities:
MAAK TABEL tabelnaam (kolom1 datatype, kolom2 datatype) PARTITIE DOOR
De “tabelnaam” is de naam voor uw tabel, naast de verschillende kolommen die de tabel zal hebben en hun gegevenstypen. Voor de “partition_key” is dit de kolom waarmee de partitionering zal plaatsvinden. De volgende afbeelding laat bijvoorbeeld zien dat we de tabel ‘cursussen’ met drie kolommen hebben gemaakt. Bovendien is ons partitietype LIST en selecteren we de faculteitskolom als onze partitiesleutel:

Nadat de tabel is gemaakt, moeten we de verschillende partities maken die we nodig hebben. Ga daarvoor verder met de volgende syntaxis:
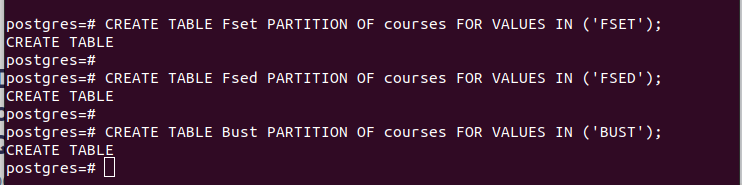
MAAK TABEL partitie_tabel PARTITIE VAN hoofd_tabel VOOR WAARDEN IN (VALUE);Het eerste voorbeeld in de volgende afbeelding laat bijvoorbeeld zien dat we een partitietabel hebben gemaakt met de naam “Fset” die alle waarden bevat in de kolom “faculteit” die we hebben geselecteerd als onze partitiesleutel waarvan de waarde “FSET” is. We hebben een vergelijkbare logica gebruikt voor de andere twee partities die we hebben gemaakt.
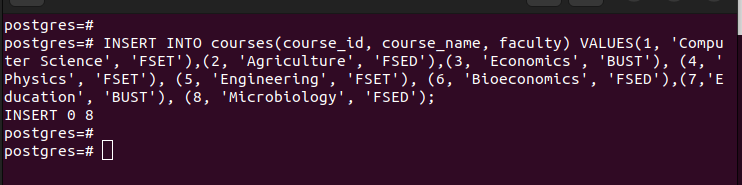
Zodra u de partities heeft, kunt u de waarden invoegen in de hoofdtabel die we hebben gemaakt. Elke waarde die u invoegt, wordt gekoppeld aan de respectieve partitie op basis van de waarden in de partitiesleutel die u hebt geselecteerd.
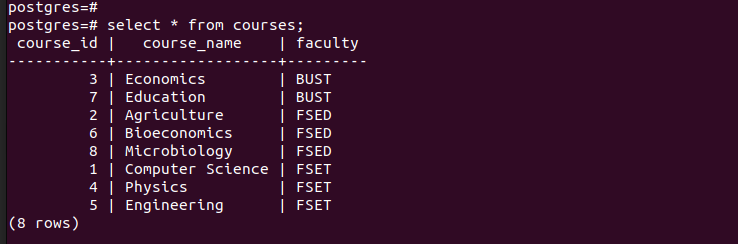
Als we alle vermeldingen in de hoofdtabel vermelden, kunnen we zien dat deze alle vermeldingen bevat die we hebben ingevoegd.
Om te verifiëren dat we de partities met succes hebben gemaakt, controleren we de records in elk van de gemaakte partities.
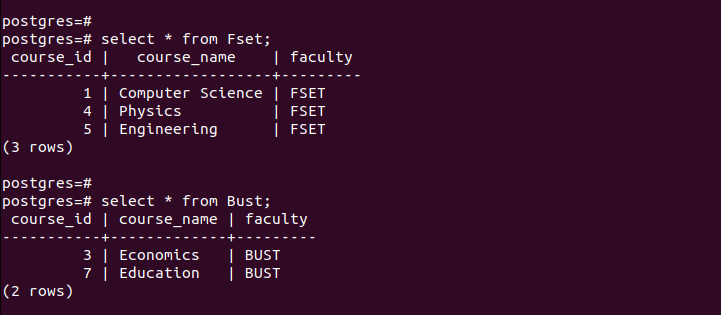
Merk op dat elke gepartitioneerde tabel alleen de gegevens bevat die overeenkomen met de criteria die zijn gedefinieerd bij het partitioneren. Dat is hoe het partitioneren op lijst werkt.
2. Bereikpartitionering
Een ander criterium voor het maken van partities is het gebruik van de optie RANGE. Hiervoor moeten we de begin- en eindwaarden opgeven die voor het bereik moeten worden gebruikt. Het gebruik van deze methode is ideaal bij het werken met datums.
De syntaxis voor het maken van de hoofdtabel is als volgt:
MAAK TABEL tabelnaam (kolom1 gegevenstype, kolom2 gegevenstype) PARTITIE OP BEREIK (partitiesleutel);We hebben de tabel “cust_orders” gemaakt en gespecificeerd om de datum als onze “partition_key” te gebruiken.

Gebruik de volgende syntaxis om de partities te maken:
MAAK TABEL partitie_tabel PARTITIE VAN hoofd_tabel VOOR WAARDEN VAN (startwaarde) TOT (eindwaarde);We hebben onze partities zo gedefinieerd dat ze elk kwartaal werken met behulp van de kolom 'datum'.
Nadat alle partities zijn aangemaakt en de gegevens zijn ingevoegd, ziet onze tabel er zo uit:
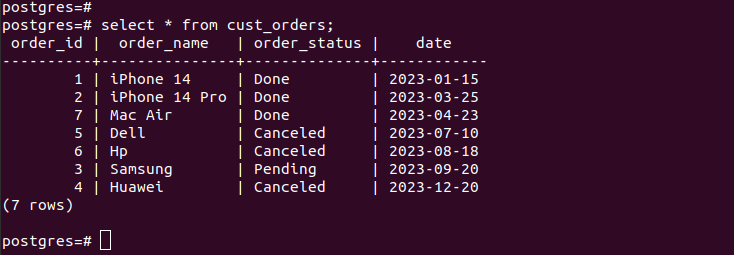
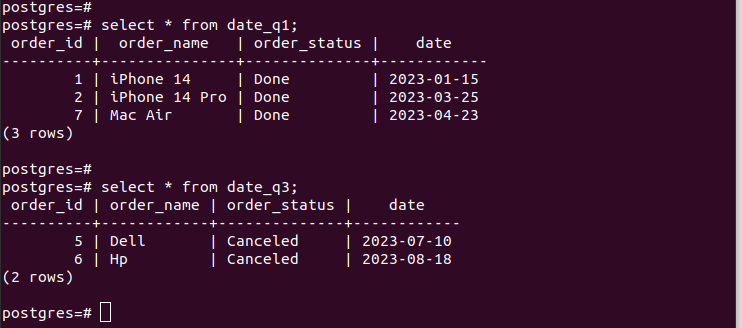
Als we de vermeldingen in de gemaakte partities controleren, verifiëren we dat onze partitie werkt en dat we alleen de juiste records hebben volgens de partitiecriteria die we hebben opgegeven. Alle nieuwe vermeldingen die u aan uw tabel toevoegt, worden automatisch aan de betreffende partitie toegevoegd.
3. Hash-partitionering
Het laatste partitiecriterium dat we zullen bespreken is het gebruik van hash. Laten we snel de hoofdtabel maken met behulp van de volgende syntaxis:
MAAK TABEL tabelnaam (kolom1 datatype, kolom2 datatype) PARTITIE DOOR HASH (partitiesleutel); 
Bij het partitioneren met hash moet u de modulus en de rest opgeven, de rijen die moeten worden gedeeld door de hashwaarde van de door u opgegeven “partition_key”. Voor ons geval gebruiken we een modulus van 4.
Onze syntaxis is als volgt:
MAAK TABEL partitie_tabel PARTITIE VAN hoofd_tabel VOOR WAARDEN MET (MODULUS num1, REST num2);Onze partities zijn als volgt:
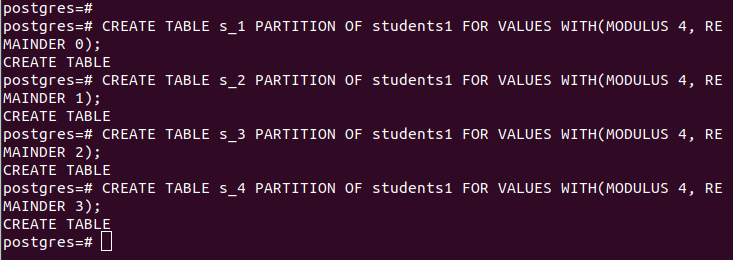
Voor de “main_table” bevat deze de vermeldingen die hieronder worden weergegeven:
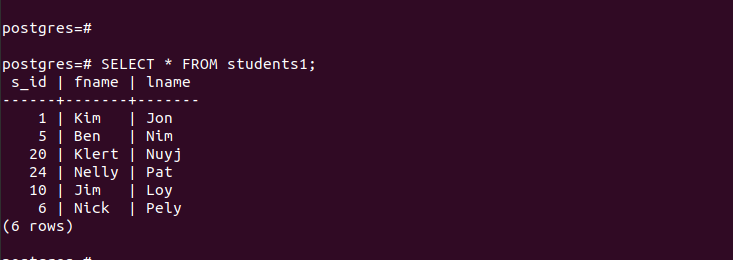
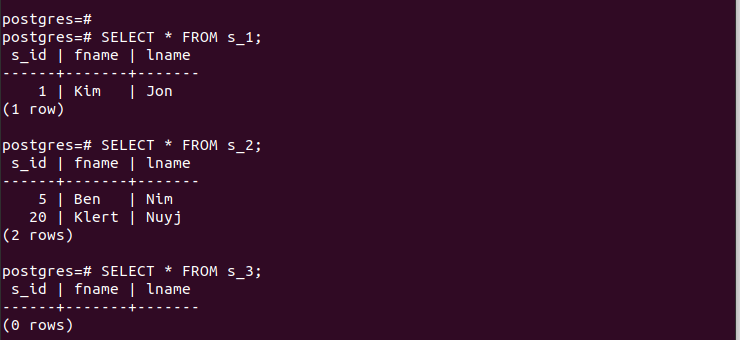
Voor de aangemaakte partities hebben we snel toegang tot hun invoer en kunnen we verifiëren dat onze partitie werkt.
Conclusie
PostgreSQL-partities zijn een handige manier om de database te optimaliseren om tijd te besparen en de betrouwbaarheid te vergroten. We hebben de indeling in detail besproken, inclusief de verschillende beschikbare opties. Bovendien hebben we voorbeelden gegeven van hoe u de partities kunt implementeren. Probeer ze uit!