Als databasebeheerders moeten we geobsedeerd zijn door de tools en methoden om de databaseprestaties te verbeteren.
In PostgreSQL hebben we toegang tot de opdracht EXPLAIN ANALYZE waarmee we het uitvoeringsplan en de prestaties van een bepaalde databasequery kunnen analyseren. De opdracht retourneert gedetailleerde informatie over hoe de database-engine de query verwerkt. Dit omvat de volgorde van uitgevoerde bewerkingen, geschatte querykosten, uitvoeringstijdstip en meer.
We kunnen deze informatie vervolgens gebruiken om de databasequery's te identificeren en om de potentiële prestatieknelpunten te identificeren en op te lossen.
In deze zelfstudie wordt besproken hoe u de opdracht EXPLAIN ANALYZE in PostgreSQL kunt gebruiken om de queryprestaties te bekijken en te optimaliseren.
PostgreSQL UITLEG ANALYSE
De opdracht is vrij eenvoudig. Eerst moeten we het EXPLAIN ANALYZE-commando toevoegen aan het begin van de query die we willen analyseren.
De opdrachtsyntaxis is als volgt:
UITLEG ANALYSENadat u de opdracht hebt uitgevoerd, retourneert PostgreSQL een gedetailleerde uitvoer over de opgegeven query.
Inzicht in de EXPLAIN ANALYZE Query-uitvoer
Zoals vermeld, genereert PostgreSQL, zodra we de opdracht EXPLAIN ANALYZE uitvoeren, een gedetailleerd rapport van het queryplan en de uitvoeringsstatistieken.
De uitvoer bestaat uit een reeks kolommen die nuttige informatie bevatten. De resulterende kolommen zijn zoals weergegeven met hun respectieve betekenis:
VRAAG PLAN – In deze kolom wordt het uitvoeringsplan van de opgegeven query weergegeven. Het uitvoeringsplan verwijst naar een reeks bewerkingen die de database-engine uitvoert om de query met succes te voltooien.
PLAN – De tweede kolom is de PLAN-kolom. Deze bevat een tekstuele weergave van elke handeling of stap in het uitvoeringsplan. Nogmaals, elke bewerking is ingesprongen om de hiërarchie van bewerkingen aan te geven.
TOTALE PRIJS – De kolom met de totale kosten vertegenwoordigt de geschatte totale kosten van de zoekopdracht. De kosten verwijzen naar een relatieve maatstaf die de databasequeryplanner gebruikt om het optimale uitvoeringsplan te bepalen.
WERKELIJKE RIJEN – Deze kolom toont het exacte aantal rijen dat wordt verwerkt bij elke stap in de uitvoering van de query.
WERKELIJKE TIJD – Deze kolom toont de werkelijke tijd die elke bewerking in beslag heeft genomen, inclusief zowel de uitvoeringstijd van de bewerking als de tijd die aan resources is besteed.
PLANNING TIJD – Deze kolom toont de tijd die de queryplanner nodig heeft om een uitvoeringsplan te genereren. Dit omvat de totale tijd van de query-optimalisatie en het genereren van het plan.
UITVOERTIJD – Deze kolom toont de totale tijd om de query uit te voeren. Dit omvat ook de tijd die is besteed aan planning en uitvoering van query's.
PostgreSQL UITLEG ANALYSE Voorbeeld
Laten we eens kijken naar enkele basisvoorbeelden van het gebruik van de instructie EXPLAIN ANALYZE.
Voorbeeld 1: Selecteer Afschrift
Laten we de instructie EXPLAIN ANALYZE gebruiken om de uitvoering van een eenvoudige select-instructie in PostgreSQL weer te geven.
Nadat we de vorige instructie hebben uitgevoerd, zouden we de volgende uitvoer moeten krijgen:
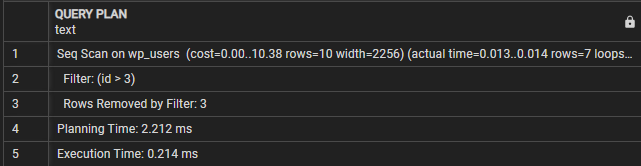
VRAAG PLAN-------------------------------------------------- ------------------
Seq Scan op wp_users (kosten=0.00..10.38 rijen=10 breedte=2256) (werkelijke tijd=0.009..0.010 rijen=7 lussen=1)
Filteren: (id > 3)
Rijen verwijderd door filter: 3
Planningstijd: 0,995 ms
Uitvoeringstijd: 0,021 ms
(5 rijen)
In dit geval kunnen we zien dat de sectie Queryplan aangeeft dat de query een sequentiële scan uitvoert op de wp_users-tabel. De filterregel geeft de voorwaarde aan die wordt gebruikt om de resulterende rijen te filteren.
We zien dan de 'Rijen verwijderd door filter' die het aantal rijen toont dat wordt geëlimineerd door de filtervoorwaarde.
Ten slotte toont de uitvoeringstijd de totale uitvoeringstijd van de query. In dit geval duurt de query 0,021 ms.
Voorbeeld 2: een join analyseren
Laten we een complexere query nemen waarbij een SQL-join betrokken is. Hiervoor gebruiken we de Pagila voorbeelddatabase. U kunt de voorbeelddatabase voor demonstratiedoeleinden downloaden en op uw machine installeren.
We kunnen een eenvoudige join uitvoeren, zoals hieronder wordt weergegeven:
uitleggen analyseren SELECT f.titel, c.naamVAN film f
WORD LID van film_category fc ON f.film_id = fc.film_id
DOE MEE categorie c ON fc.category_id = c.category_id;
Nadat we de gegeven query hebben uitgevoerd, zouden we de uitvoer als volgt moeten zien:
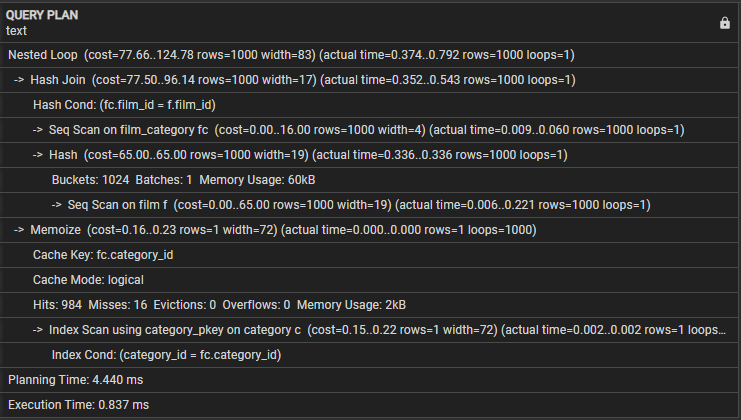
Laten we het volgende queryplan verkennen:
- Geneste lus – Dit geeft aan dat de join een strategie voor geneste lus gebruikt.
- Hash Join - Deze bewerking voegt zich bij de film_category en de filmtabellen met behulp van een Hash join-algoritme. Deze operatie heeft een kostprijs van 77,50 en naar schatting 1000 rijen. De werkelijke tijd die nodig is voor deze bewerking is echter 0,254 tot 0,439 milliseconden en er worden 1000 rijen opgehaald.
- Hash Cond – Dit geeft aan dat de join-voorwaarde een hash-join gebruikt om overeen te komen met de film_id-kolommen en de film_category-kolommen in de filmtabellen.
- Seq Scan on film_category – Deze bewerking voert een sequentiële scan uit op de tabel film_category met een kostprijs van 16,00 en naar schatting 1000 rijen. De werkelijke tijd die nodig is voor deze bewerking is 0,008 tot 0,056 milliseconden en er worden 1000 rijen opgehaald.
- Seq Scan op film: de query voert een sequentiële scan uit op de filmtafel met de resulterende geschatte en werkelijke kosten en rijen in deze bewerking.
- Onthouden - Deze bewerking slaat de resultaten op van de samenvoeging tussen film_category en filmtabellen voor later gebruik.
- Cachesleutel - Dit geeft aan dat de cachesleutel die wordt gebruikt voor memovorming is gebaseerd op de categorie_id-kolom van film_category.
- Cachemodus: dit geeft aan dat de query de logische cachemodus gebruikt.
- Hits, Misses, Evictions, Overflows – De drie regels geven statistieken over de cache, het aantal treffers, missers, uitzettingen en overflows tijdens de uitvoering. Dit blok omvat ook het geheugengebruik tijdens het uitvoeren van query's.
- Indexscan met category_pkey - Dit toont de bewerking die een indexscan uitvoert op de categorietabel met behulp van de primaire sleutelindex.
- Index Cond – Dit laat zien dat de indexscan is gebaseerd op de voorwaarde die overeenkomt met de categorie_id-kolom in de categorietabel.
- Planningstijd - Deze regel toont de tijd die nodig is voor queryplanning, namelijk 3,005 milliseconden.
- Uitvoeringstijd - Ten slotte toont deze regel de totale uitvoeringstijd van de query, die 0,745 milliseconden is.
Daar heb je het! Een gedetailleerde informatie over de uitvoering van een eenvoudige join in PostgreSQL.
Conclusie
Je ontdekte de kracht en het gebruik van de EXPLAIN ANALYZE-instructie in PostgreSQL. De instructie EXPLAIN ANALYZE is een krachtig hulpmiddel voor queryanalyse en -optimalisatie. Gebruik deze tool om efficiënte en minder resource-intensieve query's te bouwen.