Panda's Set_Option-methode
Vandaag zullen we bekijken hoe u de functie 'pd.set_option()' kunt gebruiken om alle kolommen in het Pandas-dataframe weer te geven wanneer u het in uw Spyder-tool presenteert. Om de 'pd.set_option()' te gebruiken, volgen we de gegeven syntaxis:

Laten we beginnen met het leren van het concept met behulp van de praktische implementatie van het Python-programma.
Voorbeeld: Panda's Set_Option-methode gebruiken om alle kolommen weer te geven
Deze demonstratie is een gids om alle kolommen in een DataFrame weer te geven door gebruik te maken van de Panda's 'set_option()'. We zullen de details van elke stap voor de implementatie van deze Python-methode duidelijk maken.
De eerste vereiste voor de praktische implementatie van het Python-script is om de beste tool te vinden waar u uw programma uitvoert. De tool die we voor onze illustratie hebben gebruikt, is de tool 'Spyder'. We lanceerden de tool en begonnen aan het Python-script te werken.
Beginnend met de code, moeten we in eerste instantie de vereiste bibliotheken importeren die we in dit programma nodig hebben. De eerste bibliotheek die we in ons Python-bestand hebben geladen, is de Pandas-bibliotheek, aangezien de functies die we hier gebruiken door Pandas worden geleverd. We hebben deze bibliotheek een alias gegeven als 'pd'. De tweede bibliotheek die we hebben geladen, is de NumPy-bibliotheek. NumPy (Numerieke Python) is een numeriek computerpakket dat is ontwikkeld via Python-programmering. Het gedeelte NumPy importeren van de code geeft Python de opdracht om de NumPy-module in uw huidige Python-bestand te integreren. Het 'as np'-gedeelte van het script instrueert Python vervolgens om de afkorting 'np' aan NumPy toe te wijzen. Hiermee kunt u de NumPy-methoden gebruiken door 'np.function_name' in te voeren in plaats van NumPy.
Nu beginnen we met de hoofdcode. De belangrijkste en fundamentele behoefte voor ons programma is het Pandas DataFrame. We geven dus alle kolommen weer die het bevat. Nu is het helemaal aan jou of je een DataFrame met gespecificeerde waarden wilt maken of dat je een CSV-bestand moet importeren. Wat we voor deze instantie hebben gekozen, is het maken van een DataFrame met NaN-waarden. We hebben de methode 'pd.DataFrame()' aangeroepen om een DataFrame te construeren. Hier hebben we twee parameters opgegeven: 'index' en 'kolommen'. Het argument 'index' verwijst naar de rijen, wat betekent dat we de rijen voor het DataFrame instellen.
We hebben de parameter 'index' en de NumPy-functie 'np.arange() met een waardetelling van '6' toegewezen. Het genereert zes rijen voor het DataFrame. Het vult alle vermeldingen met NaN-waarden omdat we het geen enkele waarde hebben gegeven. Het argument 'kolommen', zoals de naam aangeeft, wordt gebruikt om de kolommen voor het DataFrame in te stellen. Het krijgt ook de functie 'np.arange()' toegewezen met een '25'-waardetelling voor de kolommen. Het construeert dus 25 kolommen voor het DataFrame.
Als we de functie 'pd.DataFrame()' aanroepen, hebben we dus een DataFrame met 25 kolommen en 6 rijen gevuld met null-waarden. Om dit DataFrame te behouden, moeten we een DataFrame-object bouwen dat de inhoud ervan opslaat. Daarom hebben we een DataFrame-object 'willekeurig' gemaakt en het resultaat toegewezen dat we krijgen van de 'pd.DataFrame()'-methode. Nu wilt u zeker dat het DataFrame wordt gegenereerd. Python biedt ons een methode om de uitvoer op het scherm te bekijken, de functie 'print()'. We hebben deze methode aangeroepen door het DataFrame-object 'willekeurig' als parameter door te geven.
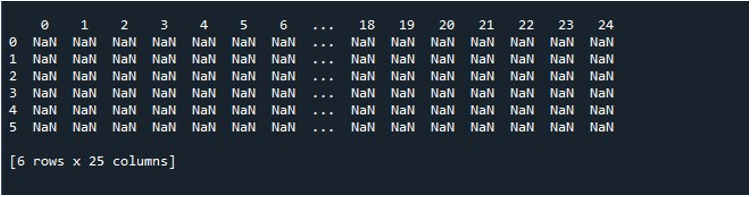
Wanneer we dit codefragment uitvoeren, krijgen we ons DataFrame met NaN-waarden weergegeven op de terminal. Hier kunnen we zien dat enkele van de eerste kolommen en slechts enkele van het einde zichtbaar zijn. Alle tussenliggende kolommen zijn afgekapt. Standaard verbergt het enkele rijen en kolommen om frustratie voor de gebruiker te voorkomen door enorme datasets weer te geven.
U kunt zelfs het totale aantal kolommen in een DataFrame controleren door de functie 'len()' van Panda's te gebruiken. Schrijf de functie 'len()' op de console van uw 'Spyder'-tool. Schrijf de naam van het DataFrame tussen de haakjes met de eigenschap '.columns'. Het geeft ons de totale lengte van kolommen in uw DataFrame.

Het retourneert de lengte van ons DataFrame die 25 is.
Nu is de volgende en kerntaak om de standaardoptie te wijzigen om de uitvoer weer te geven. Er kunnen omstandigheden zijn waarin u het volledige DataFrame op de terminal wilt bekijken. Vanwege de standaardwaarden worden veel items afgekapt, wat de gebruiker teleurstelt. U leert hier hoe u dit probleem kunt oplossen. Pandas biedt ons een 'pd.set_option()' -functie om de standaard weergave-instellingen te wijzigen. Direct na het weergeven van het DataFrame op de console, roepen we de methode 'pd.set_option()' op. We specificeren de parameter tussen de haakjes van deze functie die we moeten gebruiken om alle kolommen van het DataFrame weer te geven.
Hier hebben we de 'display.max_columns' gebruikt om de maximale kolommen in ons DataFrame weer te geven. We kunnen ook de waarde voor deze parameter definiëren, d.w.z. de maximale kolommen die u wilt weergeven. We stellen daarentegen de 'display.max_columns' in op 'None', die alle kolommen uit het DataFrame met maximale lengte weergeeft. Ten slotte hebben we de functie 'print()' gebruikt om het resulterende DataFrame weer te geven met alle kolommen zichtbaar op de terminal.
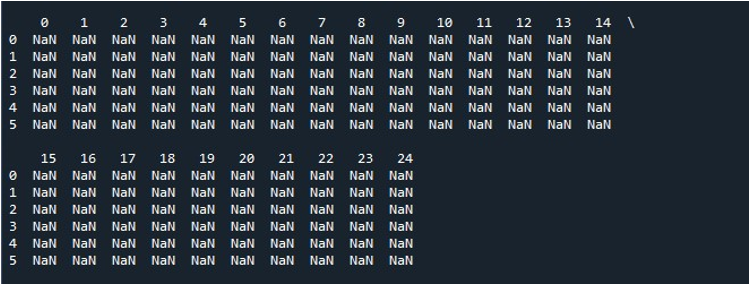
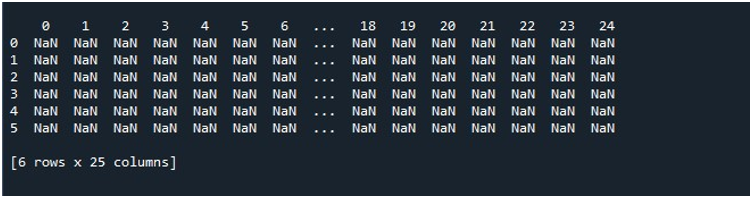
Wanneer we op de optie 'Bestand uitvoeren' in de tool 'Spyder' klikken, kunnen we een DataFrame zien dat wordt tentoongesteld. Dit DataFrame heeft zes rijen en het aantal kolommen is 25. Er zijn geen kolommen die worden afgekapt omdat de functie 'pd.set_option()' met maximale kolomlengte nu is ingeschakeld.
We kunnen zelfs de weergave-optie resetten, want zodra we de weergavelengte op het maximum hebben ingesteld, blijft het de DataFrames weergeven met alle kolommen in dat specifieke Python-bestand. Hiervoor gebruiken we de Panda's 'pd.reset_option()'. We roepen deze functie aan en geven de 'display.max_columns' als parameter van deze functie.

Dit geeft ons de initiële weergave-instellingen voor het geleverde DataFrame.
Conclusie
Het bekijken van de volledige output op de terminal met een enorme dataset brengt ons soms in de problemen wanneer de standaardinstellingen van de tool in strijd zijn met de behoeften van de gebruiker. Om deze tegenslag op te lossen, geeft Pandas ons de methode 'pd.set_option()'. In deze leergids hebben we u kennis laten maken met deze methode en de noodzaak om deze toe te passen. We hebben het onderwerp gedemonstreerd met de praktisch gecompileerde en uitgevoerde Python-voorbeeldcodes. We hebben de resultaten weergegeven van de illustratie die is uitgevoerd op 'Spyder'. We hebben uitgelegd hoe u alle kolommen van het DataFrame op de console kunt weergeven door de standaardinstellingen te wijzigen en alle instellingen terug te zetten naar de begininstelling. Door volledig gerichte aandacht te besteden aan de praktische implementatie van de module, kunt u deze gebruiken wanneer u dergelijke problemen ondervindt.