'Pandas' is een krachtige tool voor de python-omgeving. Het is een 'open' broncode voor de analyse van gegevens. De pandas join en de pandas merge-methode worden gebruikt om de twee dataframes samen te voegen tot een enkel dataframe. In beide methoden van panda's is het verschil dat de functie 'meedoen' van panda's zich bij het dataframe voegt met behulp van een index. Terwijl de panda's 'merge' -functie zich bij het dataframe voegt met behulp van de index en de kolommethode waarin we zelf de gewenste kolom kunnen selecteren. De samenvoegmethode van panda's wordt meestal gebruikt in vergelijking met de samenvoegmethode van panda's. De software die we zullen gebruiken voor de implementatie is de 'spyder' -software, die zich in de python-omgeving bevindt die ons voordelen zal bieden voor de code-implementatie van de pandas join-methode() en de pandas merge()-methodefunctie.
Syntaxis van de Pandas Join()-methode
“df1. meedoen ( df2 ) ”De 'df' in de bovenstaande syntaxis is de afkorting van het 'dataframe'. Er zijn twee dataframes in de syntaxis met de 'dot join' -functie, die is voor het aanroepen van de methode. Het is de panda-methode om twee dataframes samen te voegen. Het werkt door de index te gebruiken om de dataframes in één te combineren.
Syntaxis van Panda's Merge()-methode
“df1. samenvoegen ( df2 , Aan = 'kolomnaam' ) ”De syntaxis van de samenvoegmethode van panda's heeft twee dataframes als 'df1' en 'df2'. De 'dot merge' -functie roept de methode op om beide dataframes samen te voegen met het uiterlijk van omgekeerde kolommen.
We zullen de volgende manieren behandelen om twee dataframes te combineren om de methoden van panda merge en pandas join te gebruiken:
- Panda's Join-methode overlapt.
- Panda's sluiten zich aan bij de methode met behulp van een indexreset.
- Panda's merge-methode (kolom 'links en rechts').
- Panda's merge-methode expliciet.
De dataframes maken voor de implementatie van de Pandas Merge en Pandas Join-methode
Eerst moeten we een dataframe maken. Daarvoor gebruiken we de tool 'spyder'. Nadat u het hebt geopend, begint u met het schrijven van de code. Importeer panda's als 'pd' voor de panda-bibliotheekvereniging. We hebben de dataframe-variabelen als 'x', 'y', 'p' en 'q dienovereenkomstig en 'a' met waarden '1' en 'b' met de waarde toegewezen als '2'.

De uitvoer is een 'df' gemaakt met de toegewezen waarden. We kunnen het zo groot maken als de data is.
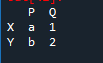
Een ander dataframe maken
We moeten een ander dataframe maken om de methoden van het samenvoegen van panda's en het samenvoegen van panda's duidelijk te begrijpen. Hier hebben we 'df' hetzelfde gemaakt als de bovenstaande 'df', alleen de waarden waaraan variabelen zijn toegewezen, zijn anders. We hebben 'h', 'j', 's' en 'd', terwijl we waarden 'b' toewijzen met de waarde '8' en 'Y' met de waarde '3'.

De uitvoer toont een eenvoudige 'df' die is gemaakt.

Voorbeeld # 01: Panda's Join-methode (overlappend)
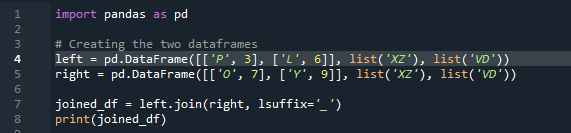
Nu zullen we zien hoe we twee dataframes kunnen samenvoegen met de panda's join-methode. Voor deze methode kunnen we de kolom van uw keuze kiezen waaraan we willen werken vanuit het dataframe. We hebben het voorbeeld genomen met de overlappende kolom 'links' van de 'df', dus we kunnen dit oplossen met het 'achtervoegsel' om de overlapping van gegevens te verhelpen. Hier zijn de gebruikte variabelen 'x', 'z', 'v', 'd'. “p”, “o”, “l” en “y” met de waarden toegewezen als “3”, “6”, “7” en “9”. De '.join' roept de methode aan, met de uitlijning ingesteld op left join met het rechter 'df'-achtervoegsel. ”. Het 'achtervoegsel' dat in de code wordt gebruikt, is omdat er in het dataframe twee kolommen zijn met dezelfde naam die 'sleutel' is en die de gegevens niet zullen overlappen.
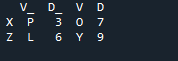
De uitvoer geeft geen overlappende gegevens weer met de methode om twee 'df' samen te voegen met behulp van de panda's join-methode.
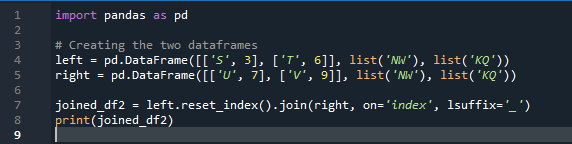
Voorbeeld # 02: Panda's join-methode met behulp van een indexreset
In dit voorbeeld zullen we afzonderlijk de kolom specificeren met de parameter 'on' om te gebruiken als de 'sleutel' in de methode join die helpt bij het samenvoegen van de twee dataframes. het gecombineerde ding wordt gedaan met deze parameter. Ook moet de index van een van de twee 'df' vergelijkbaar zijn om ze samen te voegen. Vergelijkbare soorten gegevens of gegevens die voor hetzelfde doel worden gebruikt, kunnen samen worden verwerkt. Dit zal de index nog steeds gebruiken, vanaf de rechterkant. De variabelen zijn de 's', 't', 'u', 'v', 'n', 'w', 'k' en 'q'. De toegewezen waarden zijn “3”, “6”, “7” en “9”. De 'reset dot index' is een methode van panda's om de index van de 'df' te resetten. De reset-index stelt alle gehele getallen van uw dataframe-lijst in van 0 totdat de dataframe-gegevens daar zijn verlengd.
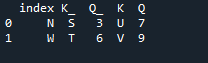
Hier is de uitvoer die wordt weergegeven met de index 'sleutel' join-methode van panda's.
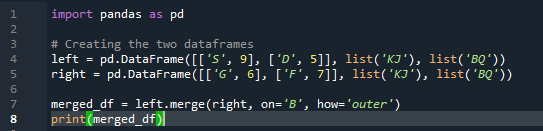
Voorbeeld # 03: Samenvoegmethode voor panda's (kolom 'links en rechts')
De samenvoegmethode voert een vergelijkbare bewerking uit als de panda's join-methode. Beide methoden zijn voor het combineren van gegevens op een vergelijkbaar dataframe. De samenvoegmethode is veelzijdiger en vereist het specificeren van de sleutel. We kunnen het ook specificeren in de linker- en rechterkolom, afhankelijk van het werk van uw dataframe. De variabelen in de code zijn 's', 'd', 'g', 'f', 'k', 'j', 'b' en 'q'. de toegewezen waarden zijn “9”, “5”, “6” en “7”. De buitenste 'join'-implementatie wordt gedaan op beide 'df' door de parameter 'how' van de panda's merge-methodefunctie te gebruiken.
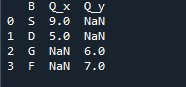
De uitvoer die we zien, toont de samengevoegde gegevens van de twee dataframes. De 'NaN' staat voor 'geen nummer', wat betekent dat als er geen nummer is toegewezen in de gegevens, de 'NaN' daar wordt weergegeven.
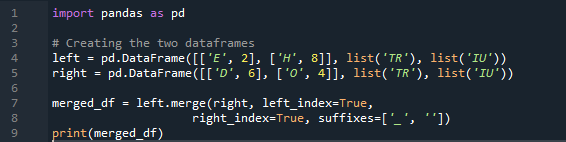
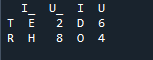
Voorbeeld # 04: De samenvoegmethode expliciet
Hier, in dit voorbeeld, is de samenvoegmethode de vernietiging van de index en wordt de indexwaarde niet aangenomen op het dataframe. We zullen deze methode doen op basis van het werk dat moet worden gedaan, waarbij de expliciete specificatie moet worden opgevolgd. Het zal de gegevens samenvoegen op basis van een linkerindex of rechterindex met de parameter. De variabelen in dit dataframe zijn 't', 'r', 'I', 'u', 'h', 'o', 'e' en 'e'. De toegewezen waarden zijn '2', '4', '6' en '4'. Het bovenstaande voorbeeld van de samenvoegmethode voor panda's met de kolomselectie volgens de behoefte is de meest representatieve en waardevolle methode om de twee dataframes samen te voegen. Aan het einde van de coderegel controleren of de samenvoegsleutel uniek is in de dataset.
In de onderstaande uitvoer wordt de index niet weergegeven zonder de index, maar wordt de functie uitgevoerd op basis van de rechter- en linkerindex.
Conclusie
De methoden merge() en join() zijn beide methoden die erg handig en effectief zijn. Beide functies worden gebruikt voor het samenvoegen van de twee afzonderlijke dataframes op hetzelfde dataframe, maar hebben een verschillend gebruik, afhankelijk van het geval. In dit artikel hebben we de belangrijkste verschillen geleerd tussen de samenvoeg- en samenvoegmethode voor panda's. Na het doen van de voorbeelden en het begrijpen van de panda's join-methode, zullen we het afsluiten met de wetenschap dat, als we meer flexibele en database-achtige joins willen, het de voorkeur verdient om de panda's merge-methode te gebruiken. Aan de andere kant, als we het dataframe uitgebreid willen combineren met de index, kunnen we de functie pandas join() gebruiken.