5.1 Inleiding
Het besturingssysteem voor de Commodore-64 computer wordt geleverd met de computer in Read Only Memory (ROM). Het aantal geheugenbytelocaties voor de Commodore-64 varieert van $0000 tot $FFFF (dat wil zeggen 000016 tot FFFF16, wat 010 tot 65.53510 is). Het besturingssysteem is van $E000 tot $FFFF (d.w.z. 57,34410 tot 65,53610).
Waarom het Commodore-64 besturingssysteem bestuderen
Waarom zou je vandaag de dag het Commodore-64 besturingssysteem bestuderen, terwijl het een besturingssysteem was van een computer die in 1982 werd uitgebracht? Welnu, de Commodore-64 computer gebruikt de Central Processing Unit 6510, wat een upgrade is (hoewel geen grote upgrade) van de 6502 µP.
De 6502 µP wordt nog steeds in grote aantallen geproduceerd; het is niet langer voor thuis- of kantoorcomputers, maar voor elektrische en elektronische apparaten (apparaten). De 6502 µP is ook eenvoudig te begrijpen en te bedienen in vergelijking met de andere microprocessors van zijn tijd. Als gevolg hiervan is het een van de beste (zo niet de beste) microprocessor die kan worden gebruikt om de assembleertaal te onderwijzen.
De 65C02 µP, nog steeds van de microprocessorklasse 6502, heeft 66 instructies in de assembleertaal, die zelfs allemaal uit het hoofd kunnen worden geleerd. Moderne microprocessors hebben veel assembleertaalinstructies en kunnen niet uit het hoofd worden geleerd. Elke µP heeft zijn eigen assembleertaal. Elk besturingssysteem, of het nu nieuw of oud is, is van assembleertaal. Daarmee is de 6502 assembleertaal goed te gebruiken om het besturingssysteem aan beginners te leren. Na het leren van een besturingssysteem, zoals dat voor de Commodore-64, kan gemakkelijk een modern besturingssysteem worden geleerd met dat als basis.
Dit is niet alleen de mening van de auteur (ikzelf). Het is een groeiende trend in de wereld. Er worden steeds meer artikelen op internet geschreven voor een verbeterd Commodore-64 besturingssysteem, zodat het op een modern besturingssysteem lijkt. Moderne besturingssystemen worden uitgelegd in het hoofdstuk na het volgende.
Opmerking : Het Commodore-64 OS (Kernal) werkt nog steeds goed met moderne invoer- en uitvoerapparaten (niet allemaal).
Acht-bits computer
In een 8-bits microcomputer zoals de Commodore 64 wordt de informatie opgeslagen, overgedragen en gemanipuleerd in de vorm van 8-bits binaire codes.
Geheugen kaart
Een geheugenkaart is een schaal die het volledige geheugenbereik verdeelt in kleinere bereiken van verschillende grootte en laat zien wat (subroutine en/of variabele) tot welk bereik behoort. Een variabele is een label dat overeenkomt met een bepaald geheugenadres dat een waarde heeft. Labels worden ook gebruikt om het begin van subroutines te identificeren. Maar in dit geval staan ze bekend als de namen van de subroutines. Een subroutine kan eenvoudigweg een routine worden genoemd.
De geheugenkaart (lay-out) in het vorige hoofdstuk is niet gedetailleerd genoeg. Het is heel eenvoudig. De geheugenkaart van de Commodore-64 computer kan worden weergegeven met drie detailniveaus. Wanneer weergegeven op het tussenniveau, heeft de Commodore-64 computer verschillende geheugenkaarten. De standaard geheugenkaart van de Commodore-64 computer op het tussenliggende niveau is:

Fig. 5.11 Commodore-64 geheugenkaart
In die tijd was er een populaire computertaal genaamd BASIC. Veel computergebruikers moesten een aantal minimale BASIC-taalopdrachten kennen, zoals het laden van een programma van de diskette (schijf) naar het geheugen, het uitvoeren (uitvoeren) van een programma in het geheugen en het afsluiten (sluiten) van een programma. Wanneer het BASIC-programma draait, moet de gebruiker de gegevens regel voor regel invoeren. Het is niet zoals tegenwoordig wanneer een applicatie (een aantal programma's vormen een applicatie) is geschreven in een taal op hoog niveau met vensters en de gebruiker alleen maar de verschillende gegevens op gespecialiseerde plaatsen in een venster hoeft in te passen. In sommige gevallen gebruiken we een muis om de vooraf bestelde gegevens te selecteren. BASIC was destijds een taal op hoog niveau, maar ligt vrij dicht bij de assembleertaal.
Merk op dat het grootste deel van het geheugen in beslag wordt genomen door BASIC in de standaardgeheugenkaart. BASIC beschikt over commando's (instructies) die worden uitgevoerd door de zogenaamde BASIC Interpreter. In feite bevindt de BASIC-interpreter zich in ROM van de $A000-locatie tot $BFFF (inclusief), wat vermoedelijk een RAM-gebied is. Dit is 8 Kbytes, wat voor die tijd behoorlijk groot is! Het bevindt zich eigenlijk in ROM op die plaats van het hele geheugen. Het heeft dezelfde grootte als het besturingssysteem, van $E000 tot $FFFF (inclusief). De programma's die in BASIC zijn geschreven, worden ook in het bereik van $0200 tot $BFFF geplaatst.
Het RAM-geheugen voor het assembleertaalprogramma voor de gebruiker varieert van $C000 tot $CFFF, slechts 4 Kbytes van de 64 Kbytes. Dus waarom gebruiken of leren we de assembleertaal? De nieuwe en oude besturingssystemen zijn van assembleertalen. Het besturingssysteem van de Commodore-64 is in ROM, van $E000 tot $FFFF. Het is geschreven in de assembleertaal 65C02 µP (6510 µP). Het bestaat uit subroutines. Het gebruikersprogramma in assembleertaal moet deze subroutines oproepen om te kunnen communiceren met randapparatuur (invoer- en uitvoerapparaten). Door het Commodore-64 besturingssysteem in assembleertaal te begrijpen, kan de student de besturingssystemen snel en op een veel minder vervelende manier begrijpen. Nogmaals, in die tijd werden veel gebruikersprogramma's voor Commodore-64 geschreven in BASIC en niet in assembleertaal. De assembleertalen werden in die tijd meer door programmeurs zelf gebruikt voor technische doeleinden.
De Kernal, gespeld als K-e-r-n-a-l, is het besturingssysteem van de Commodore-64. Het wordt geleverd met de Commodore-64 computer in ROM en niet op een schijf (of diskette). De Kernal bestaat uit subroutines. Om toegang te krijgen tot de randapparatuur moet het gebruikersprogramma in assembleertaal (machinetaal) deze subroutines gebruiken. De Kernal moet niet worden verward met de kernel die wordt gespeld als K-e-r-n-e-l van de moderne besturingssystemen, hoewel ze bijna hetzelfde zijn.
Het geheugengebied van $C000 (49,15210) tot $CFFF (6324810) van 4 Kbytes10 van het geheugen is RAM of ROM. Als het RAM is, wordt het gebruikt om toegang te krijgen tot de randapparatuur. Als het ROM is, wordt het gebruikt om de tekens op het scherm (monitor) af te drukken. Dit betekent dat de tekens op het scherm worden afgedrukt of dat de randapparatuur wordt benaderd via dit gedeelte van het geheugen. Er is een bank met ROM (karakter-ROM) in de systeemeenheid (moederbord) die in en uit de hele geheugenruimte wordt geschakeld om dat te bereiken. Het kan zijn dat de gebruiker de schakeling niet opmerkt.
Het geheugengebied vanaf $0100 (256 10 ) tot $01FF (511 10 ) is de stapel. Het wordt gebruikt door zowel het besturingssysteem als de gebruikersprogramma's. De rol van de stapel werd uitgelegd in het vorige hoofdstuk van deze online carrièrecursus. Het gebied van het geheugen vanaf $0000 (0 10 ) tot $00FF (255 10 ) wordt gebruikt door het besturingssysteem. Daar worden veel aanwijzingen gegeven.
Kernal Jump-tabel
Kernal heeft routines die door het gebruikersprogramma worden aangeroepen. Toen er nieuwe versies van het besturingssysteem uitkwamen, veranderden de adressen van deze routines. Dit betekent dat de gebruikersprogramma's niet meer konden werken met de nieuwe OS-versies. Dit gebeurde niet omdat Commodore-64 een springtabel voorzag. De springtabel is een lijst met 39 vermeldingen. Elke vermelding in de tabel heeft drie adressen (behalve de laatste 6 bytes) die nooit zijn veranderd, zelfs niet bij de versiewijziging van het besturingssysteem.
Het eerste adres van een vermelding heeft een JSR-instructie. De volgende twee adressen bestaan uit een pointer van twee bytes. Deze pointer van twee bytes is het adres (of nieuw adres) van een daadwerkelijke routine die zich nog in het OS-ROM bevindt. De inhoud van de pointer zou kunnen veranderen met de nieuwe OS-versies, maar de drie adressen voor elke springtabelinvoer veranderen nooit. Neem bijvoorbeeld de adressen $FF81, $FF82 en $FF83. Deze drie adressen zijn bedoeld voor de routine om de scherm- en toetsenbordcircuits (registers) van het moederbord te initialiseren. Het $FF81-adres heeft altijd de op-code (één byte) van JSR. De $FF82- en $FF83-adressen hebben het oude of nieuwe adres van de subroutine (nog steeds in OS ROM) om de initialisatie uit te voeren. Ooit hadden de $FF82- en $FF83-adressen de inhoud (adres) van $FF5B, die kon veranderen met de volgende OS-versie. De adressen $FF81, $FF82 en $FF83 van de springtabel veranderen echter nooit.
Voor elke invoer van drie adressen krijgt het eerste adres met JSR een label (naam). Het label voor $FF81 is PCINT. PCINT verandert nooit. Dus om de scherm- en toetsenbordregisters te initialiseren, kan de programmeur eenvoudigweg “JSR PCINT” typen, wat werkt voor alle versies van het Commodore-64 OS. De locatie (startadres) van de daadwerkelijke subroutine, bijvoorbeeld $FF5B, kan in de loop van de tijd veranderen met verschillende besturingssystemen. Ja, er zijn ten minste twee JSR-instructies betrokken bij het gebruikersprogramma dat gebruikmaakt van het ROM OS. In het gebruikersprogramma is er een JSR-instructie die naar een item in de springtabel springt. Met uitzondering van de laatste zes adressen in de sprongtabel heeft het eerste adres van een item in de sprongtabel een JSR-instructie. In de Kernal kunnen sommige subroutines de andere subroutines oproepen.
De Kernal-sprongtabel begint vanaf $FF81 (inclusief) en gaat omhoog in groepen van drie, behalve de laatste zes bytes die drie pointers zijn met lagere byte-adressen: $FFFA, $FFFC en $FFFE. Alle ROM OS-routines zijn herbruikbare codes. De gebruiker hoeft ze dus niet te herschrijven.
Blokdiagram van de Commodore-64 systeemeenheid
Het volgende diagram is gedetailleerder dan dat in het vorige hoofdstuk:
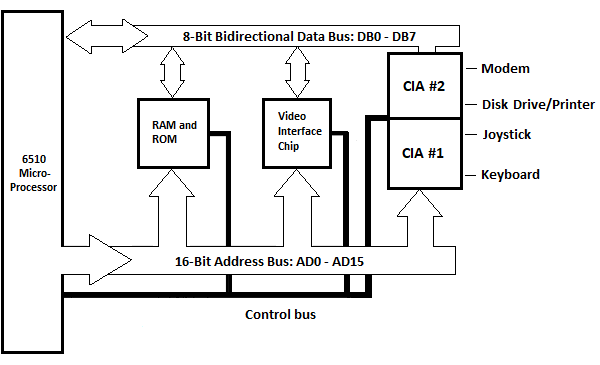
Fig. 5.12 Blokdiagram van de Commodore_64 systeemeenheid
ROM en RAM worden hier als één blok weergegeven. De Video Interface Chip (IC) voor het verwerken van de informatie op het scherm, die niet in het vorige hoofdstuk werd getoond, wordt hier getoond. Het enkele blok voor invoer-/uitvoerapparaten, dat in het vorige hoofdstuk is weergegeven, wordt hier weergegeven als twee blokken: CIA #1 en CIA #2. CIA staat voor Complexe Interface Adapter. Elke poort heeft twee parallelle 8-bit-poorten (niet te verwarren met externe poorten op een verticaal oppervlak van de systeemeenheid), genaamd poort A en poort B. De CIA's zijn in deze situatie verbonden met vijf externe apparaten. De apparaten zijn het toetsenbord, de joystick, de schijf/printer en een modem. De printer is aangesloten aan de achterkant van de schijf. Er zijn ook een geluidsinterfaceapparaatcircuit en een programmeerbaar logisch arraycircuit die niet worden weergegeven.
Toch is er een Character ROM die met beide CIA's kan worden uitgewisseld wanneer een personage naar het scherm wordt gestuurd en dit niet in het blokdiagram wordt weergegeven.
De RAM-adressen van $D000 tot $DFFF voor invoer-/uitvoercircuits bij afwezigheid van karakter-ROM hebben de volgende gedetailleerde geheugenkaart:
| Tabel 5.11 Gedetailleerde geheugenkaart van $D000 tot $DFFF |
||
|---|---|---|
| Subadresbereik | Circuit | Grootte (bytes) |
| D000 – D3FF | VIC (video-interfacecontroller (chip)) | 1K |
| D400 – D7FF | SID (geluidscircuit) | 1K |
| D800 – DBFF | Kleur RAM | 1K knabbels |
| DC00 – DCFF | CIA #1 (toetsenbord, joystick) | 256 |
| DD00 – DDFF | CIA #2 (seriële bus, gebruikerspoort/RS-232) | 256 |
| DE00 – DEF | Open I/O-sleuf #1 | 256 |
| DF00 – DFFF | Open I/O-sleuf #2 | 256 |
5.2 De twee complexe interface-adapters
Er zijn twee specifieke geïntegreerde circuits (IC's) in de Commodore-64 systeemeenheid, en elk daarvan wordt de Complex Interface Adapter genoemd. Deze twee chips worden gebruikt om het toetsenbord en andere randapparatuur met de microprocessor te verbinden. Met uitzondering van de VIC en het scherm passeren alle invoer-/uitvoersignalen tussen de microprocessor en de randapparatuur deze twee IC's. Met de Commodore-64 is er geen directe communicatie tussen het geheugen en randapparatuur. De communicatie tussen het geheugen en eventuele randapparatuur loopt via de microprocessoraccumulator, en een daarvan zijn de CIA-adapters (IC's). De IC's worden CIA #1 en CIA #2 genoemd. CIA staat voor Complexe Interface Adapter.
Elke CIA heeft 16 registers. Met uitzondering van de timer-/tellerregisters in de CIA is elk register 8 bit breed en heeft het een geheugenadres. De geheugenregisteradressen voor CIA #1 zijn van $DC00 (56320 10 ) naar $DC0F (56335 10 ). De geheugenregisteradressen voor CIA #2 zijn van $DD00 (56576 10 ) naar $DD0F (56591 10 ). Hoewel deze registers zich niet in het geheugen van de IC's bevinden, maken ze wel deel uit van het geheugen. In de tussengeheugenkaart omvat het I/O-gebied van $D000 tot $DFFF de CIA-adressen van $DC00 tot $DC0F en van $DD00 tot $DD0F. Het grootste deel van het RAM I/O-geheugengebied van $D000 tot $DFFF kan worden verwisseld met de geheugenbank van het teken-ROM voor schermtekens. Dat is de reden waarom de randapparatuur niet kan werken wanneer de personages naar het scherm worden gestuurd; hoewel de gebruiker dit misschien niet merkt, omdat het heen en weer wisselen snel gaat.
Er zijn twee registers in CIA #1 genaamd Poort A en Poort B. Hun adressen zijn respectievelijk $DC00 en $DC01. Er zijn ook twee registers in CIA #2 genaamd Poort A en Poort B. Uiteraard zijn hun adressen verschillend; ze zijn respectievelijk $DD00 en $DD01.
Poort A of poort B in beide CIA is een parallelle poort. Dit betekent dat het de gegevens in acht bits tegelijk naar het randapparaat kan sturen of de gegevens in acht bits tegelijk van de microprocessor kan ontvangen.
Geassocieerd met poort A of poort B is een Data Direction Register (DDR). Het datarichtingregister voor poort A van CIA #1 (DDRA1) bevindt zich op de geheugenbytelocatie $DC02. Het datarichtingregister voor poort B van CIA #1 (DDRB1) bevindt zich op de geheugenbytelocatie $DC03. Het datarichtingregister voor poort A van CIA #2 (DDRA2) bevindt zich op de geheugenbytelocatie $DD02. Het datarichtingregister voor poort B van CIA #2 (DDRB2) bevindt zich op de geheugenbytelocatie $DD03.
Nu kan elke bit voor poort A of poort B door het overeenkomstige datarichtingregister worden ingesteld als invoer of uitvoer. Invoer betekent dat de informatie via een CIA van het randapparaat naar de microprocessor gaat. Output betekent dat de informatie via een CIA van de microprocessor naar de randapparatuur gaat.
Als een cel van een poort (register) moet worden ingevoerd, is de corresponderende bit in het datarichtingregister 0. Als een cel van een poort (register) moet worden uitgevoerd, is de corresponderende bit in het datarichtingregister 1. In de meeste gevallen zijn alle 8-bits van een poort geprogrammeerd als invoer of uitvoer. Wanneer de computer wordt ingeschakeld, is poort A geprogrammeerd voor uitvoer en poort B voor invoer. De volgende code maakt CIA #1-poort A als uitvoer en CIA #1-poort B als invoer:
LDA#$FF
STA DDRA1; $DC00 wordt geregisseerd door $DC02
LDA#$00
STA DDRB1; $DC01 wordt geregisseerd door $DC03
DDRA1 is het label (variabelenaam) voor de geheugenbytelocatie van $DC02, en DDRB1 is het label (variabelenaam) voor de geheugenbytelocatie van $DC03. De eerste instructie laadt 11111111 naar de accumulator van de µP. De tweede instructie kopieert dit naar het datarichtingsregister van poort A van CIA nr. 1. De derde instructie laadt 00000000 naar de accumulator van de µP. De vierde instructie kopieert dit naar het datarichtingregister van poort B van CIA nr. 1. Deze code bevindt zich in een van de subroutines in het besturingssysteem die deze initialisatie uitvoert bij het opstarten van de computer.
Elke CIA heeft een interrupt-serviceverzoeklijn naar de microprocessor. Die van CIA #1 gaat naar de IRQ pin van de µP. Die van CIA #2 gaat naar de NMI pin van de µP. Onthoud dat NMI heeft een hogere prioriteit dan IRQ .
5.3 Programmeren van toetsenbord-assembleertaal
Er zijn slechts drie mogelijke interrupts voor de Commodore-64: IRQ , BRK, en NMI . De sprongtabelaanwijzer voor IRQ bevindt zich op de $FFFE- en $FFFF-adressen in ROM (besturingssysteem), wat overeenkomt met een subroutine die zich nog in het besturingssysteem (ROM) bevindt. De sprongtabelaanwijzer voor BRK bevindt zich op de $FFFC- en $FFFD-adressen in het besturingssysteem, wat overeenkomt met een subroutine die zich nog in het besturingssysteem (ROM) bevindt. De sprongtabelaanwijzer voor NMI bevindt zich op de $FFFA- en $FFFB-adressen in het besturingssysteem, wat overeenkomt met een subroutine die zich nog in het besturingssysteem (ROM) bevindt. Voor de IRQ , zijn er eigenlijk twee subroutines. De BRK-software-interrupt (instructie) heeft dus zijn eigen sprongtabelaanwijzer. De sprongtabelaanwijzer voor IRQ leidt tot de code die beslist of het de hardware-interrupt of de software-interrupt is die wordt geactiveerd. Als het de hardware-interrupt is, wordt de routine voor IRQ wordt genoemd. Als het de software-interrupt (BRK) is, wordt de routine voor BRK aangeroepen. In een van de OS-versies is de subroutine voor IRQ staat op $EA31 en de subroutine voor BRK staat op $FE66. Deze adressen liggen onder de $FF81, dus het zijn geen sprongtabelgegevens en ze kunnen veranderen met de versie van het besturingssysteem. Er zijn drie interessante routines in dit onderwerp: degene die controleert of het een ingedrukte toets is of een BRK, degene die op $FE43 staat, en degene die ook kan veranderen met de OS-versie.
De Commodore-64 computer lijkt qua uiterlijk op een enorme typemachine (naar boven gericht), zonder het afdrukgedeelte (kop en papier). Het toetsenbord is aangesloten op CIA #1. De CIA #1 scant het toetsenbord standaard elke 1/60 seconde zonder enige programmeerinterferentie. Dus elke 1/60 seconde stuurt CIA #1 een bericht IRQ naar de µP. Er is maar een IRQ pin op de µP die alleen afkomstig is van CIA #1. De enige ingangspin van NMI van de µP, die verschilt van IRQ , komt alleen van CIA #2 (zie de volgende illustratie). BRK is eigenlijk een assembleertaalinstructie die is gecodeerd in een gebruikersprogramma.
Dus elke 1/60 seconde wordt de IRQ routine waarnaar wordt verwezen door $FFFE en $FFFF wordt aangeroepen. De routine controleert of er een toets wordt ingedrukt of de BRK-instructie wordt aangetroffen. Als een toets wordt ingedrukt, wordt de routine voor het afhandelen van de toetsaanslag aangeroepen. Als het een BRK-instructie is, wordt de routine voor het afhandelen van BRK aangeroepen. Als dit geen van beide is, gebeurt er niets. Geen van beide kan gebeuren, maar CIA #1 zendt IRQ elke 1/60 seconde naar de µP.
De toetsenbordwachtrij, ook bekend als de toetsenbordbuffer, bestaat uit een reeks RAM-bytelocaties van $ 0277 tot $ 0280, inclusief; In totaal 1010 bytes. Dit is een First-IN-First-Out-buffer. Dat betekent dat het eerste personage dat komt, het eerste is dat vertrekt. Een West-Europees karakter neemt één byte in beslag.
Terwijl het programma dus geen enkel teken gebruikt wanneer een toets wordt ingedrukt, gaat de toetscode naar deze buffer (wachtrij). De buffer wordt steeds gevuld totdat er tien tekens zijn. Elk teken dat na het tiende teken wordt ingedrukt, wordt niet opgenomen. Het wordt genegeerd totdat ten minste één teken uit de wachtrij wordt gehaald (verbruikt). De springtabel bevat een invoer voor een subroutine die het eerste teken uit de wachtrij naar de microprocessor haalt. Dat betekent dat het het eerste teken dat in de wachtrij komt, in de accumulator van de µP plaatst. De sprongtabel-subroutine om dit te doen heet GETIN (voor Get-In). De eerste byte voor de drie-byte-invoer in de sprongtabel heeft het label GETIN (adres $FFE4). De volgende twee bytes zijn de pointer (adres) die verwijst naar de daadwerkelijke routine in ROM (OS). Het is de verantwoordelijkheid van de programmeur om deze routine aan te roepen. Anders blijft de toetsenbordbuffer vol en worden alle recentelijk ingedrukte toetsen genegeerd. De waarde die in de accumulator gaat, is de overeenkomstige sleutel-ASCII-waarde.
Hoe komen de sleutelcodes überhaupt in de wachtrij? Er is een sprongtabelroutine genaamd SCNKEY (voor scansleutel). Deze routine kan zowel door software als door hardware worden aangeroepen. In dit geval wordt het door een elektronisch (natuurkundig) circuit in de microprocessor opgeroepen wanneer het elektrische signaal wordt afgegeven IRQ is laag. Hoe dat precies gebeurt, wordt in deze online loopbaancursus niet behandeld.
De code om de eerste sleutelcode van de toetsenbordbuffer naar de accumulator A te krijgen, bestaat uit slechts één regel:
STAP IN
Als de toetsenbordbuffer leeg is, wordt $00 in de accumulator geplaatst. Houd er rekening mee dat de ASCII-code voor nul niet $00 is; Het kost $30. $00 betekent Nul. In een programma kan er een punt zijn waarop het programma moet wachten op een toetsaanslag. De code hiervoor is:
WACHT JSR KRIJG
CMP #$00
KIKKER WACHT
In de eerste regel is 'WAIT' een label dat het RAM-adres identificeert waar de JSR-instructie wordt ingevoerd (getypt). GETIN is ook een adres. Het is het adres van de eerste van de overeenkomstige drie bytes in de springtabel. Het GETIN-item, evenals alle items in de springtabel (behalve de laatste drie), bestaat uit drie bytes. De eerste byte van de invoer is de JSR-instructie. De volgende twee bytes zijn het adres van de hoofdtekst van de daadwerkelijke GETIN-subroutine die zich nog steeds in ROM (OS) bevindt, maar onder de springtabel. Er staat dus dat je naar de GETIN-subroutine moet springen. Als de toetsenbordwachtrij niet leeg is, plaatst GETIN de ASCII-sleutelcode van de First-In-First-Out-wachtrij in de accumulator. Als de wachtrij leeg is, wordt Null ($00) in de accumulator geplaatst.
De tweede instructie vergelijkt de accumulatorwaarde met $00. Als het $00 is, betekent dit dat de toetsenbordwachtrij leeg is en dat de CMP-instructie een 1 naar de Z-vlag van het processorstatusregister (eenvoudigweg statusregister genoemd) stuurt. Als de waarde in A niet $00 is, verzendt de CMP-instructie 0 naar de Z-vlag van het statusregister.
De derde instructie, 'BEQ WAIT', stuurt het programma terug naar de eerste instructie als de Z-vlag van het statusregister 1 is. De eerste, tweede en derde instructies worden herhaaldelijk in volgorde uitgevoerd totdat een toets op het toetsenbord wordt ingedrukt . Als er nooit een toets wordt ingedrukt, herhaalt de cyclus zich voor onbepaalde tijd. Een codesegment als dit wordt normaal gesproken geschreven met een timingcodesegment dat de lus na enige tijd verlaat als er nooit een toets wordt ingedrukt (zie de volgende bespreking).
Opmerking : Het toetsenbord is het standaardinvoerapparaat en het scherm is het standaarduitvoerapparaat.
5.4 Kanaal, apparaatnummer en logisch bestandsnummer
De randapparatuur die in dit hoofdstuk wordt gebruikt om het Commodore-64 besturingssysteem uit te leggen zijn het toetsenbord, het scherm (monitor), de diskdrive met diskette, de printer en de modem die verbinding maakt via de RS-232C interface. Om de communicatie tussen deze apparaten en de systeemeenheid (microprocessor en geheugen) te laten plaatsvinden, moet een kanaal tot stand worden gebracht.
Een kanaal bestaat uit een buffer, apparaatnummer, een logisch bestandsnummer en optioneel een secundair adres. De uitleg van deze termen is als volgt:
Een buffer
Merk op uit de vorige sectie dat wanneer een toets wordt ingedrukt, de code ervan naar een bytelocatie in het RAM van een reeks van tien opeenvolgende locaties moet gaan. Deze reeks van tien locaties is de toetsenbordbuffer. Elk invoer- of uitvoerapparaat (randapparaat) heeft een reeks opeenvolgende locaties in het RAM, een zogenaamde buffer.
Apparaatnummer
Bij de Commodore-64 wordt elk randapparaat voorzien van een apparaatnummer. De volgende tabel toont de verschillende apparaten en hun nummers:
| Tabel 5.41 Commodore 64 apparaatnummers en hun apparaten |
|
|---|---|
| Nummer | Apparaat |
| 0 | Toetsenbord |
| 1 | Tapedrive |
| 2 | RS 232C-interface naar b.v. een modem |
| 3 | Scherm |
| 4 | Printer nr. 1 |
| 5 | Printer nr. 2 |
| 6 | Plotter #1 |
| 7 | Plotter #2 |
| 8 | Schijfstation |
| 9 ¦ ¦ ¦ 30 |
Van 8 (inclusief) tot 22 extra opslagapparaten |
Er zijn twee soorten poorten voor een computer. Eén type bevindt zich extern, op het verticale oppervlak van de systeemeenheid. Het andere type is intern. Deze interne poort is een register. Commodore-64 heeft vier interne poorten: poort A en poort B voor CIA 1 en poort A en poort B voor CIA 2. Er is één externe poort voor de Commodore-64 die de seriële poort wordt genoemd. De apparaten met het nummer 3 naar boven zijn aangesloten op de seriële poort. Ze zijn in serie verbonden (de een is achter de ander aangesloten), en elk is herkenbaar aan het apparaatnummer. De apparaten met het nummer 8 naar boven zijn over het algemeen de opslagapparaten.
Opmerking : Het standaardinvoerapparaat is het toetsenbord met apparaatnummer 0. Het standaarduitvoerapparaat is het scherm met apparaatnummer 3.
Logisch bestandsnummer
Een logisch bestandsnummer is een nummer dat wordt gegeven aan een apparaat (randapparaat) in de volgorde waarin deze worden geopend voor toegang. Ze variëren van 010 tot 255 10 .
Secundair adres
Stel je voor dat er twee bestanden (of meer dan één bestand) op de schijf worden geopend. Om onderscheid te maken tussen deze twee bestanden, worden de secundaire adressen gebruikt. Secundaire adressen zijn getallen die van apparaat tot apparaat variëren. De betekenis van 3 als secundair adres voor een printer is anders dan de betekenis van 3 als secundair adres voor een schijfstation. De betekenis hangt af van kenmerken zoals wanneer een bestand wordt geopend om te lezen of wanneer een bestand wordt geopend om te schrijven. De mogelijke secundaire nummers zijn vanaf 0 10 tot 15 10 voor elk apparaat. Voor veel apparaten wordt het nummer 15 gebruikt voor het verzenden van opdrachten.
Opmerking : Het apparaatnummer wordt ook wel apparaatadres genoemd en het secundaire nummer wordt ook wel secundair adres genoemd.
Een perifeer doel identificeren
Voor de standaard Commodore geheugentoewijzing worden de geheugenadressen van $0200 tot $02FF (pagina 2) uitsluitend gebruikt door het besturingssysteem in ROM (Kernal) en niet door het besturingssysteem plus de BASIC-taal. Hoewel BASIC de locaties nog steeds kan gebruiken via het ROM OS.
De modem en de printer zijn twee verschillende randdoelen. Als er twee bestanden vanaf de schijf worden geopend, zijn dit twee verschillende doelen. Met de standaardgeheugenkaart zijn er drie opeenvolgende tabellen (lijsten) die als één grote tabel kunnen worden gezien. Deze drie tabellen bevatten de relatie tussen de logische bestandsnummers, apparaatnummers en secundaire adressen. Daarmee wordt een specifiek kanaal of input/output-doel identificeerbaar. De drie tabellen worden bestandstabellen genoemd. De RAM-adressen en wat ze hebben zijn:
$0259 — $0262: Tabel met label, LAT, van maximaal tien actieve logische bestandsnummers.
$0263 — $026C: Tabel met label, FAT, van maximaal tien corresponderende apparaatnummers.
$026D — $0276: Tabel met label, SAT, van tien overeenkomstige secundaire adressen.
Hier betekent “—“ “naar”, en een getal neemt één byte in beslag.
De lezer vraagt zich misschien af: “Waarom wordt de buffer voor elk apparaat niet meegenomen bij het identificeren van een kanaal?” Welnu, het antwoord is dat bij de Commodore-64 elk extern apparaat (randapparaat) een vaste reeks bytes in RAM (geheugenkaart) heeft. Zonder dat er een kanaal geopend is, zijn hun posities nog steeds aanwezig in het geheugen. De buffer voor het toetsenbord is bijvoorbeeld vastgesteld van $0277 tot $0280 (inclusief) voor de standaardgeheugenkaart.
De Kernal SETLFS- en SETNAM-subroutines
SETLFS en SETNAM zijn Kernal-routines. Een kanaal kun je zien als een logisch bestand. Om een kanaal te kunnen openen, moeten het logische bestandsnummer, het apparaatnummer en een optioneel secundair adres worden aangemaakt. Mogelijk is ook een optionele bestandsnaam (tekst) nodig. De SETLFS-routine stelt het logische bestandsnummer, het apparaatnummer en een optioneel secundair adres in. Deze cijfers worden in hun respectievelijke tabellen geplaatst. De SETNAM-routine stelt een stringnaam in voor het bestand, die verplicht kan zijn voor het ene kanaal en optioneel voor een ander kanaal. Deze bestaat uit een pointer (adres van twee bytes) in het geheugen. De aanwijzer wijst naar het begin van de string (naam), die zich mogelijk op een andere plaats in het geheugen bevindt. De stringnaam begint met een byte die de lengte van de string heeft, gevolgd door de tekst (naam). De naam is maximaal zestien bytes (lang).
Om de SETLFS-routine aan te roepen, moet het gebruikersprogramma springen (JSR) naar het $FFBA-adres van de springtabel van het besturingssysteem in ROM voor de standaardgeheugenkaart. Houd er rekening mee dat, met uitzondering van de laatste zes bytes van de springtabel, elke invoer uit drie bytes bestaat. De eerste byte is de JSR-instructie, die vervolgens naar de subroutine springt en begint op het adres in de volgende twee bytes. Om de SETNAM-routine aan te roepen, moet het gebruikersprogramma springen (JSR) naar het $FFBD-adres van de springtabel van het besturingssysteem in ROM. Het gebruik van deze twee routines wordt getoond in de volgende bespreking.
5.5 Een kanaal openen, een logisch bestand openen, een logisch bestand sluiten en alle I/O-kanalen sluiten
Een kanaal bestaat uit een geheugenbuffer, een logisch bestandsnummer, apparaatnummer (apparaatadres) en een optioneel secundair adres (een nummer). Een logisch bestand (een abstractie) dat wordt geïdentificeerd door een logisch bestandsnummer kan verwijzen naar een randapparaat zoals een printer, een modem, een schijfstation, enz. Elk van deze verschillende apparaten moet verschillende logische bestandsnummers hebben. Er staan veel bestanden op de schijf. Een logisch bestand kan ook verwijzen naar een bepaald bestand op de schijf. Dat specifieke bestand heeft bovendien een logisch bestandsnummer dat verschilt van dat van de randapparatuur zoals de printer of modem. Het logische bestandsnummer wordt gegeven door de programmeur. Dit kan elk getal zijn van 010 ($00) tot 25510 ($FF).
De OS SETLFS-routine
De OS SETLFS-routine die toegankelijk is door te springen (JSR) naar de OS ROM-sprongtabel op $FFBA stelt het kanaal in. Het moet het logische bestandsnummer in de bestandstabel plaatsen, namelijk LAT ($0259 - $0262). Het moet het corresponderende apparaatnummer in de bestandstabel plaatsen, namelijk FAT ($0263 - $026C). Als de toegang tot het bestand (apparaat) een secundair nummer nodig heeft, moet het overeenkomstige secundaire adres (nummer) in de bestandstabel worden geplaatst, namelijk SAT ($026D - $0276).
Om te kunnen werken moet de SETLFS-subroutine het logische bestandsnummer verkrijgen van de µP-accumulator; het moet het apparaatnummer verkrijgen uit het µP X-register. Indien het kanaal dit nodig heeft, moet het het secundaire adres uit het µP Y-register verkrijgen.
Het logische bestandsnummer wordt bepaald door de programmeur. De logische bestandsnummers die naar verschillende apparaten verwijzen, zijn verschillend. Voordat de SETLFS-routine wordt aangeroepen, moet de programmeur nu het nummer van het logische bestand in de µP-accumulator plaatsen. Het apparaatnummer wordt uit een tabel (document) gelezen, zoals in Tabel 5.41. De programmeur zou ook het apparaatnummer in het µP X-register moeten invoeren. De leverancier van een apparaat zoals een printer, schijfstation etc. levert de mogelijke secundaire adressen en hun betekenis voor het apparaat. Als het kanaal een secundair adres nodig heeft, moet de programmeur dit verkrijgen uit het document dat bij het apparaat wordt geleverd (randapparaat). Als het secundaire adres (nummer) nodig is, moet de programmeur dit in het µP Y-register plaatsen voordat de SETLFS-subroutine wordt aangeroepen. Als er geen behoefte is aan een secundair adres, moet de programmeur het $FF-nummer in het µP Y-register plaatsen voordat de SETLFS-subroutine wordt aangeroepen.
De SETLFS-subroutine wordt zonder enig argument aangeroepen. De argumenten bevinden zich al in de drie registers van de 6502 µP. Nadat de juiste nummers in de registers zijn ingevoerd, wordt de routine eenvoudigweg in het programma aangeroepen met het volgende op een aparte regel:
JSR SETLFS
De routine plaatst de verschillende getallen op de juiste manier in hun bestandstabellen.
De OS SETNAM-routine
De OS SETNAM-routine is toegankelijk door te springen (JSR) naar de OS ROM-sprongtabel op $FFBD. Niet alle bestemmingen hebben bestandsnamen. Voor degenen die bestemmingen hebben (zoals de bestanden op de schijf), moet de bestandsnaam worden ingesteld. Stel dat de bestandsnaam “mydocum” is, die uit 7 bytes bestaat zonder de aanhalingstekens. Stel dat deze naam zich op de locaties $C101 tot en met $C107 bevindt en dat de lengte van $07 zich op de locatie $C100 bevindt. Het startadres van de tekenreeks is $C101. De onderste byte van het startadres is $01 en de hogere byte is $C1.
Voordat de SETNAM-routine wordt aangeroepen, moet de programmeur het getal $07 (lengte van de string) in de µP-accumulator invoeren. De onderste byte van het startadres van de string $01 wordt in het µP X-register geplaatst. De hogere byte van het startadres van de string $C1 wordt in het µP Y-register geplaatst. De subroutine wordt eenvoudigweg als volgt aangeroepen:
JSR SETNAM
De SETNAM-routine associeert de waarden uit de drie registers met het kanaal. De waarden hoeven daarna niet meer in de registers te blijven staan. Als het kanaal geen bestandsnaam nodig heeft, moet de programmeur $00 in de µP-accumulator plaatsen. In dit geval worden de waarden in de X- en Y-registers genegeerd.
De OS OPEN-routine
De OS OPEN-routine is toegankelijk door (JSR) naar de OS ROM-sprongtabel op $FFC0 te springen. Deze routine gebruikt het logische bestandsnummer, het apparaatnummer (en de buffer), een mogelijk secundair adres en een mogelijke bestandsnaam om een verbinding tot stand te brengen tussen de commodore computer en het bestand op het externe apparaat of het externe apparaat zelf.
Deze routine heeft, net als alle andere Commodore OS ROM-routines, geen enkel argument. Hoewel het gebruik maakt van de µP-registers, hoefden geen van de registers vooraf te worden geladen met argumenten (waarden). Om het te coderen, typt u gewoon het volgende nadat de SETLFS en SETNAM zijn aangeroepen:
JSR OPEN
Er kunnen fouten optreden met de OPEN-routine. Het bestand kan bijvoorbeeld niet worden gevonden om te lezen. Wanneer er een fout optreedt, mislukt de routine en wordt het overeenkomstige foutnummer in de µP-accumulator geplaatst, en wordt de carry-vlag (op 1) van het µP-statusregister ingesteld. De volgende tabel bevat de foutnummers en hun betekenis:
| Tabel 5.51 Kernal-foutnummers en hun betekenis voor OS ROM OPEN Routine |
||
|---|---|---|
| Foutnummer | Beschrijving | Voorbeeld |
| 1 | TE VEEL BESTANDEN | OPEN wanneer er al tien bestanden geopend zijn |
| 2 | BESTAND GEOPEND | OPEN 1,3: OPEN 1,4 |
| 3 | BESTAND NIET GEOPEND | PRINT#5 zonder OPEN |
| 4 | BESTAND NIET GEVONDEN | LAAD “NIET BESTAANDE”, 8 |
| 5 | APPARAAT NIET AANWEZIG | OPEN 11,11: AFDRUKKEN#11 |
| 6 | GEEN BESTAND INVOEREN | OPEN “SEQ,S,W”: KRIJG#8,X$ |
| 7 | GEEN UITVOERBESTAND | OPEN 1,0: AFDRUKKEN#1 |
| 8 | ONTBREKENDE BESTANDSNAAM | LAAD “”,8 |
| 9 | ILLEGAAL APPARAATNR. | LAAD “PROGRAMMA”,3 |
Deze tabel wordt gepresenteerd op een manier die de lezer waarschijnlijk op veel andere plaatsen zal zien.
De OS CHKIN-routine
De OS CHKIN-routine is toegankelijk door (JSR) naar de OS ROM-sprongtabel op $FFC6 te springen. Na het openen van een bestand (logisch bestand) moet worden besloten of de opening voor invoer of uitvoer is. De CHKIN-routine maakt van de opening een ingangskanaal. Deze routine moet het logische bestandsnummer uit het µP X-register lezen. De programmeur moet dus het logische bestandsnummer in het X-register plaatsen voordat deze routine wordt aangeroepen. Het wordt eenvoudigweg genoemd als:
JSR CHKIN
De OS CHKOUT-routine
De OS CHKOUT-routine is toegankelijk door (JSR) naar de OS ROM-sprongtabel op $FFC9 te springen. Na het openen van een bestand (logisch bestand) moet worden besloten of de opening voor invoer of uitvoer is. De CHKOUT-routine maakt van de opening een uitgangskanaal. Deze routine moet het logische bestandsnummer uit het µP X-register lezen. De programmeur moet dus het logische bestandsnummer in het X-register plaatsen voordat deze routine wordt aangeroepen. Het wordt eenvoudigweg genoemd als:
JSR CHKOUT
De OS CLOSE-routine
De OS CLOSE-routine is toegankelijk door (JSR) naar de OS ROM-sprongtabel op $FFC3 te springen. Nadat een logisch bestand is geopend en de bytes zijn verzonden, moet het logische bestand worden gesloten. Door het sluiten van het logische bestand wordt de buffer in de systeemeenheid vrijgemaakt, zodat deze kan worden gebruikt door een ander logisch bestand dat nog moet worden geopend. De overeenkomstige parameters in de drie bestandstabellen worden eveneens verwijderd. De RAM-locatie voor het aantal geopende bestanden wordt met 1 verlaagd.
Wanneer de stroom van de computer wordt ingeschakeld, vindt er een hardware-reset plaats voor de microprocessor en andere hoofdchips (geïntegreerde schakelingen) op het moederbord. Dit wordt gevolgd door de initialisatie van enkele RAM-geheugenlocaties en enkele registers in sommige chips op het moederbord. Tijdens het initialisatieproces wordt de bytegeheugenlocatie van het $0098-adres op pagina nul aangegeven met het NFILES- of LDTND-label, afhankelijk van de versie van het besturingssysteem. Terwijl de computer in werking is, bevat deze locatie van één byte van 8 bits het aantal logische bestanden dat is geopend, en de startadresindex van de opeenvolgende drie bestandstabellen. Met andere woorden, deze byte heeft het aantal geopende bestanden dat met 1 wordt verlaagd wanneer het logische bestand wordt gesloten. Wanneer het logische bestand wordt gesloten, is toegang tot het terminalapparaat (bestemmingsapparaat) of het daadwerkelijke bestand op schijf niet langer mogelijk.
Om een logisch bestand te sluiten, moet de programmeur het logische bestandsnummer in de µP-accumulator plaatsen. Dit is hetzelfde logische bestandsnummer dat wordt gebruikt bij het openen van het bestand. De CLOSE-routine heeft dit nodig om dat specifieke bestand te sluiten. Net als andere OS ROM-routines accepteert de CLOSE-routine geen argument, hoewel de waarde die uit de accumulator wordt gebruikt, enigszins een argument is. De instructieregel in de assembleertaal is eenvoudigweg:
JSR DICHT
De aangepaste of vooraf gedefinieerde 6502-subroutines (routines) van de assembleertaal accepteren geen argumenten. De argumenten komen echter informeel door de waarden die de subroutine zal gebruiken in de microprocessorregisters te zetten.
De CLRCHN-routine
De OS CLRCHN-routine is toegankelijk door te springen (JSR) naar de OS ROM-sprongtabel op $FFCC. CLRCHN staat voor CLeaR CHanneL. Wanneer een logisch bestand wordt gesloten, worden de parameters ervan, het logische bestandsnummer, het apparaatnummer en het mogelijke secundaire adres, verwijderd. Het kanaal voor het logische bestand wordt dus gewist.
De handleiding zegt dat de OS CLRCHN-routine alle geopende kanalen wist en de standaard apparaatnummers en andere standaardinstellingen herstelt. Betekent dit dat het apparaatnummer van een randapparaat kan worden gewijzigd? Nou ja, niet helemaal. Tijdens de initialisatie van het besturingssysteem wordt de bytelocatie van het $0099-adres opgegeven met het DFLTI-label om het huidige invoerapparaatnummer vast te houden wanneer de computer in werking is. De Commodore-64 heeft slechts toegang tot één randapparaat tegelijk. Tijdens de initialisatie van het besturingssysteem wordt de bytelocatie van het $009A-adres opgegeven met het DFLTO-label om het huidige uitvoerapparaatnummer vast te houden wanneer de computer in werking is.
Wanneer de CLRCHN-subroutine wordt aangeroepen, wordt de DFLTI-variabele ingesteld op 0 ($00), wat het standaardinvoerapparaatnummer (toetsenbord) is. Het stelt de DFLTO-variabele in op 3 ($03), wat het standaarduitvoerapparaatnummer (scherm) is. Andere variabelen van het apparaatnummer worden op dezelfde manier gereset. Dat is de betekenis van het resetten (of herstellen) van de invoer-/uitvoerapparaten naar normaal (standaardwaarden).
De Commodore-64 handleiding zegt dat nadat de CLRCHN routine is aangeroepen, de geopende logische bestanden open blijven en nog steeds de bytes (data) kunnen verzenden. Dit betekent dat de CLRCHN-routine de overeenkomstige vermeldingen in de bestandstabellen niet verwijdert. De naam CLRCHN is nogal dubbelzinnig wat betreft de betekenis ervan.
5.6 Het personage naar het scherm sturen
Het belangrijkste geïntegreerde circuit (IC) dat de weergave van karakters en afbeeldingen op het scherm afhandelt, wordt de Video Interface Controller (chip) genoemd, die in de Commodore-64 wordt afgekort als VIC (eigenlijk VIC II voor VIC versie 2). Om informatie (waarden) naar het scherm te laten gaan, moet deze door VIC II gaan voordat deze op het scherm wordt bereikt.
Het scherm bestaat uit 25 rijen en 40 kolommen met karaktercellen. Dit maakt 40 x 25 = 1000 tekens die op het scherm kunnen worden weergegeven. De VIC II leest de overeenkomstige 1000 geheugen-RAM opeenvolgende bytelocaties voor karakters. Deze 1000 locaties samen staan bekend als schermgeheugen. Wat in deze 1000 locaties past, zijn de karaktercodes. Voor de Commodore-64 zijn de karaktercodes verschillend van de ASCII-codes.
Een tekencode is geen tekenpatroon. Er is ook een zogenaamde karakter-ROM. De karakter-ROM bestaat uit allerlei karakterpatronen, waarvan sommige overeenkomen met de karakterpatronen op het toetsenbord. Het karakter-ROM verschilt van het schermgeheugen. Wanneer een teken op het scherm moet worden weergegeven, wordt de tekencode naar een positie tussen de 1000 posities van het schermgeheugen gestuurd. Van daaruit wordt het corresponderende patroon geselecteerd uit de karakter-ROM die op het scherm moet worden weergegeven. Het kiezen van het juiste patroon in de karakter-ROM uit een karaktercode wordt gedaan door VIC II (hardware).
Veel geheugenlocaties tussen $D000 en $DFFF hebben twee doelen: ze worden gebruikt om de invoer/uitvoerbewerkingen anders dan het scherm af te handelen, of ze worden gebruikt als teken-ROM voor het scherm. Het gaat om twee geheugenblokken. De ene is RAM en de andere is ROM voor karakter-ROM. Het verwisselen van de banken om ofwel de invoer/uitvoer of de karakterpatronen (karakter-ROM) te verwerken, wordt gedaan door software (routine van het besturingssysteem in ROM van $F000 tot $FFFF).
Opmerking : De VIC heeft registers die worden geadresseerd met adressen van de geheugenruimte binnen het bereik van $D000 en $DFFF.
De CHROUT-routine
De OS CHROUT-routine is toegankelijk door te springen (JSR) naar de OS ROM-sprongtabel op $FFD2. Wanneer deze routine wordt aangeroepen, neemt deze de byte die de programmeur in de µP-accumulator heeft geplaatst en drukt deze af op het scherm waar de cursor zich bevindt. Het codesegment om bijvoorbeeld het “E”-teken af te drukken is:
LDA#$05
CHROUT
De 0516 is niet de ASCII-code voor “E”. De Commodore-64 heeft zijn eigen tekencodes voor het scherm waarbij $05 “E” betekent. Het #$05-nummer wordt in het schermgeheugen geplaatst voordat VIC het naar het scherm verzendt. Deze twee coderingsregels moeten komen nadat het kanaal is ingesteld, het logische bestand is geopend en de CHKOUT-routine is aangeroepen voor de uitvoer. De volledige code is:
; Kanaal instellen
LDA#$40; logisch bestandsnummer
LDX#$03; apparaatnummer voor scherm is $03
LDY #$FF ; geen secundair adres
JSR SETLFS; kanaal correct instellen
; geen SETNAM omdat het scherm geen naam nodig heeft
;
; Logisch bestand openen
JSR OPEN
; Kanaal voor uitvoer instellen
LDX#$40; logisch bestandsnummer
JSR CHKOUT
;
; Voer tekens uit naar het scherm
LDA#$05
JSR CHROUT
; Sluit logisch bestand
LDA#$40
JSR DICHT
De opening moet worden gesloten voordat een ander programma wordt uitgevoerd. Stel dat de computergebruiker op het verwachte tijdstip een teken op het toetsenbord typt. Het volgende programma drukt een teken van het toetsenbord naar het scherm:
; Kanaal instellen
LDA#$40; logisch bestandsnummer
LDX#$03; apparaatnummer voor scherm is $03
LDY #$FF ; geen secundair adres
JSR SETLFS; kanaal correct instellen
; geen SETNAM omdat het scherm geen naam nodig heeft
;
; Logisch bestand openen
JSR OPEN
; Kanaal voor uitvoer instellen
LDX#$40; logisch bestandsnummer
JSR CHKOUT
;
; Voer tekens in vanaf het toetsenbord
WACHT JSR KRIJG ; plaatst $00 in A als de toetsenbordwachtrij leeg is
CMP #$00; Als $00 naar A gaat, dan is Z in de vergelijking 1
BEQ WACHTEN; KRIJG opnieuw uit de wachtrij als 0 naar de accumulator gaat
BNE PRNSCRN; ga naar PRNSCRN als Z 0 is, omdat A niet langer $00 heeft
; Voer tekens uit naar het scherm
PRNSCRN JSR CHROUT; stuur de char in A naar het scherm
; Sluit logisch bestand
LDA#$40
JSR DICHT
Opmerking : WAIT en PRNSCRN zijn de labels die de adressen identificeren. De byte van het toetsenbord die in de µP-accumulator binnenkomt, is een ASCII-code. De corresponderende code die door Commodore-64 naar het scherm moet worden verzonden, moet anders zijn. Voor de eenvoud is daar in het vorige programma geen rekening mee gehouden.
5.7 Bytes voor schijf verzenden en ontvangen
Er zijn twee complexe interface-adapters in de systeemeenheid (moederbord) van Commodore-64 genaamd VIA #1 en CIA #2. Elke CIA heeft twee parallelle poorten die poort A en poort B worden genoemd. Er is een externe poort op het verticale oppervlak aan de achterkant van de Commodore-64 systeemeenheid die de seriële poort wordt genoemd. Deze poort heeft 6 pinnen, waarvan er één voor data is. De gegevens komen in serie de systeemeenheid binnen of verlaten deze, bit voor bit.
Acht parallelle bits van de interne poort A van CIA #2 kunnen bijvoorbeeld de systeemeenheid verlaten via de externe seriële poort nadat ze door een schuifregister in de CIA zijn omgezet in seriële gegevens. Acht-bits seriële gegevens van de externe seriële poort kunnen naar de interne poort A van CIA #2 gaan nadat ze door een schuifregister in de CIA zijn omgezet in parallelle gegevens.
De Commodore-64 systeemeenheid (basiseenheid) gebruikt een externe schijf met een diskette. Op deze schijf kan een printer in serie worden aangesloten (door apparaten in serie als een string aan te sluiten). De datakabel voor de diskdrive wordt aangesloten op de externe seriële poort van de Commodore-64 systeemeenheid. Dit betekent dat een in serie geschakelde printer ook op dezelfde seriële poort is aangesloten. Deze twee apparaten worden geïdentificeerd door twee verschillende apparaatnummers (meestal respectievelijk 8 en 4).
Het verzenden of ontvangen van de data voor de diskdrive volgt dezelfde procedure als eerder beschreven. Dat is:
- Het instellen van de naam van het logische bestand (nummer) die dezelfde is als die van het daadwerkelijke schijfbestand met behulp van de SETNAM-routine.
- Het logische bestand openen met behulp van de OPEN-routine.
- Beslissen of het invoer of uitvoer is met behulp van de CHKOUT- of CHKIN-routine.
- Het verzenden of ontvangen van de gegevens met behulp van de STA- en/of LDA-instructie.
- Sluiten van het logische bestand met behulp van de CLOSE-routine.
Het logische bestand moet worden gesloten. Als u het logische bestand sluit, wordt dat specifieke kanaal effectief gesloten. Bij het instellen van het kanaal voor de diskdrive wordt het logische bestandsnummer bepaald door de programmeur. Het is een getal tussen $00 en $FF (inclusief). Het mag geen nummer zijn dat al voor een ander apparaat (of daadwerkelijk bestand) is gekozen. Het apparaatnummer is 8 als er slechts één schijfstation is. Het secundaire adres (nummer) vindt u in de handleiding van de schijf. Het volgende programma gebruikt 2. Het programma schrijft de letter “E” (ASCII) naar een bestand op de schijf met de naam “mydoc.doc”. Er wordt aangenomen dat deze naam begint met het geheugenadres $C101. De lagere byte van $01 moet dus in het X-register staan en de hogere byte van $C1 moet in het Y-register staan voordat de SETNAM-routine wordt aangeroepen. Het A-register moet ook het $09-nummer hebben voordat de SETNAM-routine wordt aangeroepen.
; Kanaal instellen
LDA#$40; logisch bestandsnummer
LDX#$08; apparaatnummer voor eerste schijf
LDY #$02; secundair adres
JSR SETLFS; kanaal correct instellen
;
; Bestand op schijf heeft een naam nodig (al in het geheugen)
LDA#$09
LDX#$01
LDY#$C1
JSR SETNAM
; Logisch bestand openen
JSR OPEN
; Kanaal voor uitvoer instellen
LDX#$40; logisch bestandsnummer
JSR CHKOUT; voor schrijven
;
; Voer char uit naar schijf
LDA#$45
JSR CHROUT
; Sluit logisch bestand
LDA#$40
JSR DICHT
Om een byte van de schijf in het µP Y-register te lezen, herhaalt u het vorige programma met de volgende wijzigingen: In plaats van “JSR CHKOUT ; voor schrijven gebruikt u “JSR CHKIN; voor lezen'. Vervang het codesegment door “; Voer char naar schijf uit” met het volgende:
; Voer tekens in vanaf schijf
JSR CHRIS
De OS CHRIN-routine is toegankelijk door te springen (JSR) naar de OS ROM-sprongtabel op $FFCF. Wanneer deze routine wordt aangeroepen, krijgt deze een byte van een kanaal dat al is ingesteld als ingangskanaal en plaatst deze in het µP A-register. De GETIN ROM OS-routine kan ook worden gebruikt in plaats van CHRIN.
Een byte naar de printer verzenden
Het verzenden van een byte naar de printer gebeurt op dezelfde manier als het verzenden van een byte naar een bestand op de schijf.
5.8 De OS SAVE-routine
De OS SAVE-routine is toegankelijk door (JSR) naar de OS ROM-sprongtabel op $FFD8 te springen. De OS SAVE-routine in ROM slaat een gedeelte van het geheugen op de schijf op (dumpt) als een bestand (met een naam). Het startadres van de sectie in het geheugen moet bekend zijn. Ook het eindadres van de sectie moet bekend zijn. De onderste byte van het startadres wordt op pagina nul in het RAM geplaatst op het adres $002B. De hogere byte van het startadres wordt in de volgende bytegeheugenlocatie op het $002C-adres geplaatst. Op pagina nul verwijst het TXTTAB-label naar deze twee adressen, hoewel TXTTAB eigenlijk het $002B-adres betekent. De onderste byte van het eindadres wordt in het µP X-register geplaatst. De hogere byte van het eindadres plus 1 wordt in het µP Y-register geplaatst. Het µP A-register neemt de waarde van $2B aan voor TXTTAB ($002B). Daarmee kan de SAVE-routine als volgt worden aangeroepen:
JSR OPSLAAN
Het gedeelte van het geheugen dat moet worden opgeslagen, kan een assembleertaalprogramma of een document zijn. Een voorbeeld van een document kan een brief of een essay zijn. Om de opslagroutine te gebruiken, moet de volgende procedure worden gevolgd:
- Stel het kanaal in met behulp van de SETLFS-routine.
- Stel de naam in van het logische bestand (nummer) die dezelfde is als die van het daadwerkelijke schijfbestand met behulp van de SETNAM-routine.
- Open het logische bestand met behulp van de OPEN-routine.
- Maak er een bestand van voor de uitvoer met behulp van CHKOUT.
- De code voor het opslaan van het bestand komt hier en eindigt met 'JSR SAVE'.
- Sluit het logische bestand met behulp van de CLOSE-routine.
Het volgende programma slaat een bestand op dat begint vanaf de geheugenlocaties $C101 tot $C200:
; Kanaal instellen
LDA#$40; logisch bestandsnummer
LDX#$08; apparaatnummer voor eerste schijf
LDY #$02; secundair adres
JSR SETLFS; kanaal correct instellen
;
; Naam voor bestand op schijf (reeds in het geheugen op $C301)
LDA#$09; lengte van de bestandsnaam
LDX#$01
LDY#$C3
JSR SETNAM
; Logisch bestand openen
JSR OPEN
; Kanaal voor uitvoer instellen
LDX#$40; logisch bestandsnummer
JSR CHKOUT; om te schrijven
;
; Uitvoerbestand naar schijf
LDA #$01
STA $ 2 miljard; TXTTAB
LDA#$C1
STA $2C
LDX#$00
LDY#$C2
LDA#$2 miljard
JSR OPSLAAN
; Sluit logisch bestand
LDA#$40
JSR DICHT
Merk op dat dit een programma is dat een ander gedeelte van het geheugen (niet het programmagedeelte) op schijf opslaat (diskette voor Commodore-64).
5.9 De OS LOAD-routine
De OS LOAD-routine is toegankelijk door (JSR) naar de OS ROM-sprongtabel op $FFD5 te springen. Wanneer een sectie (een groot gebied) van het geheugen op de schijf wordt opgeslagen, wordt deze opgeslagen met een header met het startadres van de sectie in het geheugen. De OS LOAD-subroutine laadt de bytes van een bestand in het geheugen. Bij deze LOAD-bewerking moet de waarde van de accumulator 010 ($00) zijn. Om ervoor te zorgen dat de LOAD-bewerking het beginadres in de bestandskop op de schijf leest en de bestandsbytes in het RAM plaatst, beginnend vanaf dat adres, moet het secundaire adres voor het kanaal 1 of 2 zijn (het volgende programma gebruikt 2). Deze routine retourneert het adres plus 1 van de hoogste RAM-locatie die is geladen. Dit betekent dat de lage byte van het laatste adres van het bestand in RAM plus 1 in het µP X-register wordt geplaatst, en de hoge byte van het laatste adres van het bestand in RAM plus 1 in het µP Y-register wordt geplaatst.
Als het laden niet lukt, bevat het µP A-register het foutnummer (mogelijk 4, 5, 8 of 9). De C-vlag van het microprocessorstatusregister wordt ook ingesteld (1 gemaakt). Als het laden succesvol is, is de laatste waarde van het A-register niet belangrijk.
In het vorige hoofdstuk van deze online carrièrecursus vindt de eerste instructie van het assembleertaalprogramma plaats op het adres in RAM waar het programma is gestart. Het hoeft niet zo te zijn. Dit betekent dat de eerste instructie van een programma niet aan het begin van het programma in RAM hoeft te staan. De startinstructie voor een programma kan overal in het bestand in het RAM staan. De programmeur wordt geadviseerd om de start van assembleertaalinstructie te labelen met START. Daarmee wordt het programma, nadat het is geladen, opnieuw uitgevoerd (uitgevoerd) met de volgende assembleertaalinstructie:
JSR BEGIN
“JSR START” bevindt zich in het assembleertaalprogramma dat het uit te voeren programma laadt. Een assembleertaal die een ander assembleertaalbestand laadt en het geladen bestand uitvoert, heeft de volgende codeprocedure:
- Stel het kanaal in met behulp van de SETLFS-routine.
- Stel de naam in van het logische bestand (nummer) die dezelfde is als die van het daadwerkelijke schijfbestand met behulp van de SETNAM-routine.
- Open het logische bestand met behulp van de OPEN-routine.
- Maak er het bestand voor invoer van met behulp van de CHKIN.
- De code voor het laden van het bestand komt hier en eindigt met “JSR LOAD”.
- Sluit het logische bestand met behulp van de CLOSE-routine.
Het volgende programma laadt een bestand van de schijf en voert het uit:
; Kanaal instellen
LDA#$40; logisch bestandsnummer
LDX#$08; apparaatnummer voor eerste schijf
LDY #$02; secundair adres
JSR SETLFS; kanaal correct instellen
;
; Naam voor bestand op schijf (reeds in het geheugen op $C301)
LDA#$09; lengte van de bestandsnaam
LDX#$01
LDY#$C3
JSR SETNAM
; Logisch bestand openen
JSR OPEN
; Kanaal voor invoer instellen
LDX#$40; logisch bestandsnummer
JSR CHKIN; voor lezen
;
; Invoerbestand vanaf schijf
LDA#$00
JSR-LAAD
; Sluit logisch bestand
LDA#$40
JSR DICHT
; Start het geladen programma
JSR BEGIN
5.10 De modem en RS-232 standaard
De modem is een apparaat (randapparaat) dat de bits van de computer omzet in de overeenkomstige elektrische audiosignalen die via de telefoonlijn kunnen worden verzonden. Aan de ontvangende kant bevindt zich een modem vóór een ontvangende computer. Dit tweede modem zet de elektrische audiosignalen om naar bits voor de ontvangende computer.
Een modem moet op een computer worden aangesloten via een externe poort (op het verticale oppervlak van de computer). De RS-232-standaard verwijst naar een bepaald type connector waarmee een modem (in het verleden) op de computer wordt aangesloten. Met andere woorden: veel computers in het verleden hadden een externe poort die een RS-232-connector of een RS-232-compatibele connector was.
De Commodore-64 Systeemeenheid (computer) heeft een externe poort aan de achterkant, die de gebruikerspoort wordt genoemd. Deze gebruikerspoort is RS-232-compatibel. Daar kan een modemapparaat op worden aangesloten. De Commodore-64 communiceert met een modem via deze gebruikerspoort. Het ROM-besturingssysteem voor de Commodore-64 heeft subroutines om te communiceren met een modem genaamd RS-232-routines. Deze routines hebben vermeldingen in de springtabel.
Baudsnelheid
De acht-bits byte van de computer wordt omgezet in een reeks van acht bits voordat deze naar de modem wordt verzonden. Het omgekeerde gebeurt van de modem naar de computer. Baudrate is het aantal bits dat per seconde in serie wordt verzonden.
Onderkant van het geheugen
De term “Bottom of Memory” verwijst niet naar de geheugenbytelocatie van het $0000-adres. Het verwijst naar de laagste RAM-locatie waar de gebruiker zijn/haar gegevens en programma's kan plaatsen. Standaard is dit $ 0800. Bedenk uit de vorige discussie dat veel van de locaties tussen $0800 en $BFFF worden gebruikt door de BASIC-computertaal en zijn programmeurs (gebruikers). Alleen de adreslocaties $C000 tot $CFFF blijven beschikbaar voor gebruik voor de assembleertaalprogramma's en gegevens; dit is 4 Kbytes van de 64 Kbytes geheugen.
Top van geheugen
In die tijd, toen de klanten de Commodore-64 computers kochten, waren sommige niet voorzien van alle geheugenlocaties. Dergelijke computers hadden een ROM met een besturingssysteem van $E000 tot $FFFF. Ze hadden RAM van $0000 tot een limiet, die niet $DFFF is, naast $E000. De limiet lag onder $DFFF en die limiet wordt “Top of Memory” genoemd. Top-of-memory verwijst dus niet naar de $FFFF-locatie.
Commodore-64-buffers voor RS-232-communicatie
Zendende buffer
De buffer voor RS-232-transmissie (uitvoer) neemt 256 bytes in beslag vanaf de bovenkant van het geheugen naar beneden. De aanwijzer voor deze zendbuffer wordt gelabeld als ROBUF. Deze aanwijzer bevindt zich op pagina nul met de $00F9-adressen gevolgd door $00FA. ROBUF identificeert feitelijk $00F9. Dus als het adres voor het begin van de buffer $BE00 is, bevindt de onderste byte van $BE00, die $00 is, zich op de $00F9-locatie en de hogere byte van $BE00, die $BE is, bevindt zich in de $00FA plaats.
Ontvangstbuffer
De buffer voor het ontvangen van de RS-232-bytes (invoer) neemt 256 bytes in beslag van de onderkant van de zendbuffer. De aanwijzer voor deze ontvangstbuffer wordt gelabeld als RIBUF. Deze aanwijzer bevindt zich op pagina nul met de $00F7-adressen gevolgd door $00F8. RIBUF identificeert feitelijk $00F7. Dus als het adres voor het begin van de buffer $BF00 is, bevindt de lagere byte van $BF00, die $00 is, zich op de $00F7-locatie en de hogere byte van $BF00, die $BF is, bevindt zich in de $00F8-locatie. plaats. Er worden dus 512 bytes uit het top-of-memory gebruikt als de totale RS-232 RAM-buffer.
RS-232-kanaal
Wanneer een modem op de (externe) gebruikerspoort wordt aangesloten, is de communicatie naar het modem uitsluitend RS-232-communicatie. De procedure om een compleet RS-232-kanaal te krijgen is vrijwel hetzelfde als in de vorige discussie, maar met één belangrijk verschil: de bestandsnaam is een code en geen string in het geheugen. De code $0610 is een goede keuze. Het betekent een baudsnelheid van 300 bits/sec en enkele andere technische parameters. Er is ook geen secundair adres. Houd er rekening mee dat het apparaatnummer 2 is. De procedure voor het instellen van een volledig RS-232-kanaal is:
- Het kanaal instellen met behulp van de SETLFS-routine.
- De naam van het logische bestand instellen, $0610.
- Het logische bestand openen met behulp van de OPEN-routine.
- Maak er een bestand van voor uitvoer met CHKOUT of een bestand voor invoer met CHKIN.
- Het verzenden van de afzonderlijke bytes met CHROUT of het ontvangen van de afzonderlijke bytes met GETIN.
- Sluiten van het logische bestand met behulp van de CLOSE-routine.
De OS GETIN-routine is toegankelijk door te springen (JSR) naar de OS ROM-sprongtabel op $FFE4. Deze routine neemt, wanneer hij wordt aangeroepen, de byte die naar de ontvangerbuffer wordt gestuurd en plaatst deze in de µP-accumulator (retourneert deze).
Het volgende programma verzendt de byte “E” (ASCII) naar de modem die is aangesloten op de RS-232-compatibele gebruikerspoort:
; Kanaal instellen
LDA#$40; logisch bestandsnummer
LDX#$02; apparaatnummer voor RS-232
LDY #$FF ; geen secundair adres
JSR SETLFS; kanaal correct instellen
;
; Naam voor RS-232 is een code, b.v. $ 0610
LDA#$02; De lengte van de code is 2 bytes
LDX#$10
LDY#$06
JSR SETNAM
;
; Logisch bestand openen
JSR OPEN
; Kanaal voor uitvoer instellen
LDX#$40; logisch bestandsnummer
JSR CHKOUT
;
; Uitvoerteken naar RS-232, b.v. modem
LDA#$45
JSR CHROUT
; Sluit logisch bestand
LDA#$40
JSR DICHT
Om een byte te ontvangen, lijkt de code sterk op elkaar, behalve dat “JSR CHKOUT” wordt vervangen door “JSR CHKIN” en:
LDA#$45
JSR CHROUT
wordt vervangen door “JSR GETIN”, waarbij het resultaat in het A-register wordt geplaatst.
Het continu verzenden of ontvangen van bytes wordt gedaan door een lus voor respectievelijk het verzenden of ontvangen van een codesegment.
Merk op dat de invoer en uitvoer met de Commodore in de meeste gevallen vergelijkbaar is, behalve voor het toetsenbord, waar sommige routines niet door de programmeur worden aangeroepen, maar door het besturingssysteem.
5.11 Tellen en timing
Beschouw de aftelvolgorde:
2, 1, 0
Dit is het aftellen van 2 naar 0. Bekijk nu de herhaalde aftelreeks:
2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0
Dit is het herhaaldelijk aftellen van dezelfde reeks. De reeks wordt vier keer herhaald. Vier keer betekent dat de timing 4 is. Binnen één reeks wordt geteld. Het herhalen van dezelfde reeks is timing.
Er zijn twee Complex Interface Adapters in de systeemeenheid van de Commodore-64. Elke CIA heeft twee teller-/timercircuits genaamd Timer A (TA) en Timer B (TB). Het telcircuit verschilt niet van het tijdcircuit. De teller of timer in de Commodore-64 verwijst naar hetzelfde. In feite verwijst elk van beide in wezen naar één 16-bits register dat altijd aftelt naar 0 bij de systeemklokpulsen. In het 16-bits register kunnen verschillende waarden worden ingesteld. Hoe groter de waarde, hoe langer het duurt om af te tellen naar nul. Elke keer dat een van de timers voorbij nul gaat, wordt de IRQ interruptsignaal wordt naar de microprocessor gestuurd. Wanneer de telling voorbij nul gaat, wordt dit onderstroom genoemd.
Afhankelijk van hoe het timercircuit is geprogrammeerd, kan een timer in eenmalige modus of in continue modus werken. In de vorige illustratie betekent de eenmalige modus “doe 2, 1, 0” en stop terwijl de klokpulsen doorgaan. De continue modus is als '2, 1, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0, enz.' die doorgaat met de klokpulsen. Dat betekent dat wanneer het voorbij nul gaat en er geen instructie wordt gegeven, de aftelprocedure wordt herhaald. Het grootste getal is meestal veel groter dan 2.
Timer A (TA) van CIA #1 genereert IRQ met regelmatige tussenpozen (duur) om het toetsenbord te onderhouden. In feite is dit standaard elke 1/60 seconde. IRQ wordt elke 1/60 seconde naar de microprocessor gestuurd. Het is alleen wanneer IRQ wordt verzonden dat een programma een sleutelwaarde uit de toetsenbordwachtrij (buffer) kan lezen. Houd er rekening mee dat de microprocessor slechts één pin heeft voor de IRQ signaal. De microprocessor heeft ook slechts één pin voor de NMI signaal. Het ¯NMI-signaal naar de microprocessor komt altijd van CIA #2.
Het 16-bits timerregister heeft twee geheugenadressen: één voor de lagere byte en één voor de hogere byte. Elke CIA heeft twee timercircuits. De twee CIA's zijn identiek. Voor CIA #1 zijn de adressen voor de twee timers: DC04 en DC05 voor TA en DC06 en DC07 voor TB. Voor CIA #2 zijn de adressen voor de twee timers: DD04 en DD05 voor TA en DD06 en DD07 voor TB.
Stel dat het nummer 25510 naar de TA-timer van CIA #2 moet worden gestuurd om af te tellen. 25510 = 00000000111111112 is in zestien bits. 00000000111111112 = $000FFF is in hexadecimaal formaat. In dit geval wordt $FF naar het register op het $DD04-adres gestuurd, en wordt $00 naar het register op het $DD05-adres gestuurd – weinig endianness. Het volgende codesegment stuurt het nummer naar de kassa:
LDA#$FF
STAAT $DD04
LDA#$00
STAAT $DD05
Hoewel de registers in een CIA RAM-adressen hebben, bevinden ze zich fysiek in de CIA en is de CIA een afzonderlijk IC van RAM of ROM.
Dat is niet alles! Wanneer de timer een nummer heeft gekregen voor het aftellen, zoals bij de vorige code, start het aftellen niet. Het aftellen begint wanneer een byte van acht bits naar het overeenkomstige besturingsregister voor de timer is verzonden. De eerste bit van deze byte voor het besturingsregister geeft aan of het aftellen wel of niet moet beginnen. Een waarde 0 voor dit eerste bit betekent dat het aftellen stopt, terwijl een waarde 1 betekent dat het aftellen begint. Ook moet de byte aangeven of het aftellen in one shot (eenmalige) modus of in free running modus (continue modus) plaatsvindt. De one-shot-modus telt af en stopt wanneer de waarde van het timerregister nul wordt. Bij de vrijloopmodus wordt het aftellen herhaald nadat 0 is bereikt. Het vierde (index 3) bit van de byte dat naar het besturingsregister wordt gestuurd, geeft de modus aan: 0 betekent vrijloopmodus en 1 betekent one-shot-modus.
Een geschikt getal om te beginnen met tellen in de one-shot-modus is 000010012 = $09 in hexadecimaal. Een geschikt getal om te beginnen met tellen in de vrije modus is 000000012 = $01 in hexadecimaal. Elk timerregister heeft zijn eigen besturingsregister. In CIA #1 heeft het besturingsregister voor timer A het RAM-adres DC0E16 en heeft het besturingsregister voor timer B het RAM-adres DC0F16. In CIA #2 heeft het controleregister voor timer A het RAM-adres DDOE16 en heeft het controleregister voor timer B het RAM-adres DDOF16. Gebruik de volgende code om te beginnen met het aftellen van het zestien-bits getal in TA van CIA #2, in one-shot-modus:
LDA#$09
STA $DD0E
Om te beginnen met het aftellen van het zestien-bits getal in TA van CIA #2, in de free running-modus, gebruikt u de volgende code:
LDA #$01
STA $DD0E
5.12 De IRQ En NMI Verzoeken
De 6502-microprocessor heeft de IRQ En NMI lijnen (pinnen). Zowel CIA #1 als CIA #2 hebben elk de IRQ pin voor de microprocessor. De IRQ pin van CIA #2 is verbonden met de NMI pin van de µP. De IRQ pin van CIA #1 is verbonden met de IRQ pin van de µP. Dit zijn de enige twee interruptlijnen die de microprocessor verbinden. Dus de IRQ pin van CIA #2 is de NMI bron en kan ook gezien worden als de ¯NMI-lijn.
CIA #1 heeft vijf mogelijke directe bronnen voor het genereren van de IRQ signaal voor de µP. CIA #2 heeft dezelfde structuur als CIA #1. Dus CIA #2 heeft deze keer dezelfde vijf mogelijke directe bronnen voor het genereren van het interruptsignaal, namelijk het NMI signaal. Onthoud dat wanneer de µP de NMI signaal, als het de IRQ verzoek, schort het dat op en handelt het af NMI verzoek. Wanneer het klaar is met het verwerken van de NMI verzoek, hervat het vervolgens de afhandeling van de IRQ verzoek.
CIA #1 wordt normaal gesproken extern aangesloten op het toetsenbord en een spelapparaat zoals een joystick. Het toetsenbord gebruikt meer van poort A van CIA #1 dan van poort B. Het gameapparaat gebruikt meer van CIA #1-poort B dan poort A. CIA #2 is normaal gesproken extern aangesloten op de schijf (daisy chained aan de printer) en het modem. De schijf gebruikt meer van poort A van CIA #2 (hoewel via de externe seriële poort) dan poort B. De modem (RS-232) gebruikt meer van CIA #2 poort B dan poort A.
Hoe weet de systeemeenheid nu wat de oorzaak is? IRQ of NMI onderbreken? CIA #1 en CIA #2 hebben vijf directe bronnen van onderbreking. Als het interruptsignaal naar de µP is NMI , de bron is een van de vijf directe bronnen van CIA #2. Als het interruptsignaal naar de µP is IRQ , de bron is een van de vijf directe bronnen van CIA #1.
De volgende vraag is: “Hoe maakt de systeemeenheid onderscheid tussen de vijf directe bronnen van elke CIA?” Elke CIA heeft een acht-bits register dat het Interrupt Control Register (ICR) wordt genoemd. De ICR bedient beide havens van de CIA. De volgende tabel toont de betekenis van de acht bits van het interruptcontroleregister, beginnend bij bit 0:
| Tabel 5.13 Controleregister onderbreken |
|
|---|---|
| Bit-index | Betekenis |
| 0 | Instellen (1 gemaakt) door onderstroom van timer A |
| 1 | Ingesteld door onderloop van timer B |
| 2 | Instellen wanneer de tijdklok gelijk is aan het alarm |
| 3 | Instellen wanneer de seriële poort vol is |
| 4 | Ingesteld door extern apparaat |
| 5 | Niet gebruikt (0 gemaakt) |
| 6 | Niet gebruikt (0 gemaakt) |
| 7 | Wordt ingesteld wanneer een van de eerste vijf bits is ingesteld |
Zoals uit de tabel blijkt, wordt elk van de directe bronnen weergegeven door een van de eerste vijf bits. Dus wanneer het interruptsignaal wordt ontvangen op de µP, moet de code worden uitgevoerd om de inhoud van het interruptcontroleregister te lezen om de exacte bron van de interrupt te kennen. Het RAM-adres voor de ICR van CIA #1 is DC0D16. Het RAM-adres voor de ICR van CIA #2 is DD0D16. Om de inhoud van de ICR van CIA #1 naar de µP-accumulator te lezen (terug te sturen) typt u de volgende instructie:
LDA$DC0D
Om de inhoud van de ICR van CIA #2 naar de µP-accumulator te lezen (terug te sturen) typt u de volgende instructie:
LDA$DD0D
5.13 Onderbrekend achtergrondprogramma
Normaal gesproken onderbreekt het toetsenbord de microprocessor elke 1/60 seconde. Stel je voor dat een programma actief is en een positie bereikt waar het moet wachten op een toets van het toetsenbord voordat het verder kan gaan met de onderstaande codesegmenten. Stel dat als er geen toets op het toetsenbord wordt ingedrukt, het programma slechts een kleine lus maakt, wachtend op een toets. Stel je voor dat het programma actief is en net een toets van het toetsenbord verwacht, net nadat de toetsenbordonderbreking is gegeven. Op dat moment stopt de hele computer indirect en doet niets anders dan het herhalen van de wachtlus. Stel je voor dat er een klaviertoets wordt ingedrukt vlak voor het volgende nummer van de volgende toetsenbordonderbreking. Dit betekent dat de computer ongeveer een zestigste van een seconde niets heeft gedaan! Dat is een lange tijd voor een computer om niets te doen, zelfs in de dagen van Commodore-64. Het kan zijn dat de computer in die tijd (duur) iets anders heeft gedaan. Er zijn veel van dergelijke duur in een programma.
Er kan een tweede programma worden geschreven dat op een dergelijke “inactieve” tijdsduur werkt. Van een dergelijk programma wordt gezegd dat het op de achtergrond van het hoofd- (of eerste) programma werkt. Een gemakkelijke manier om dit te doen is door gewoon een aangepaste BRK-interruptafhandeling af te dwingen wanneer er een toets van het toetsenbord wordt verwacht.
Aanwijzer voor BRK-instructie
Op de opeenvolgende RAM-locaties van de $0316- en $0317-adressen bevindt zich de pointer (vector) voor de feitelijke BRK-instructieroutine. De standaardaanwijzer wordt daar geplaatst wanneer de computer wordt ingeschakeld door het besturingssysteem in ROM. Deze standaardaanwijzer is een adres dat nog steeds verwijst naar de standaard BRK-instructiehandler in het OS-ROM. De pointer is een 16-bits adres. De onderste byte van de pointer wordt op de bytelocatie van het adres $0306 geplaatst, en de hogere byte van de pointer wordt op de bytelocatie $0317 geplaatst.
Een tweede programma kan zo worden geschreven dat wanneer het systeem “inactief” is, sommige codes van het tweede programma door het systeem worden uitgevoerd. Dit betekent dat het tweede programma uit subroutines moet bestaan. Wanneer het systeem “inactief” is en wacht op een toets van het toetsenbord, wordt een volgende subroutine voor het tweede programma uitgevoerd. Menselijke interactie met de computer is traag in vergelijking met de werking van de systeemeenheid.
Dit probleem is eenvoudig op te lossen: elke keer dat de computer moet wachten op een toets van het toetsenbord, voegt u een BRK-instructie in de code in en vervangt u de aanwijzer op $0316 (en $0317) door de aanwijzer van de volgende subroutine van de tweede ( aangepast) programma. Op die manier zouden beide programma's een looptijd hebben die niet veel langer is dan die van het hoofdprogramma dat alleen draait.
5.14 Montage en compilatie
De assembler vervangt alle labels door adressen. Een assembleertaalprogramma wordt normaal gesproken geschreven om op een bepaald adres te starten. Het resultaat van de assembler (na het assembleren) wordt de “objectcode” genoemd, waarbij alles in binair getal is. Dat resultaat is het uitvoerbare bestand als het bestand een programma is en geen document. Een document is niet uitvoerbaar.
Een applicatie bestaat uit meer dan één (assembleertaal)programma. Er is meestal een hoofdprogramma. De situatie hier moet niet worden verward met de situatie voor de Interrupt Driven Achtergrondprogramma's. Alle programma's hier zijn voorgrondprogramma's, maar er is een eerste of hoofdprogramma.
Er is een compiler nodig in plaats van de assembler als er meer dan één voorgrondprogramma's zijn. De compiler stelt elk van de programma's samen tot een objectcode. Er zou echter een probleem zijn: sommige codesegmenten zullen elkaar overlappen omdat de programma's waarschijnlijk door verschillende mensen zijn geschreven. De oplossing van de compiler is om alle overlappende programma's, behalve de eerste, in de geheugenruimte te verplaatsen, zodat de programma's elkaar niet overlappen. Als het nu gaat om het opslaan van variabelen, overlappen sommige variabele-adressen elkaar nog steeds. De oplossing hier is om de overlappende adressen te vervangen door de nieuwe adressen (behalve het eerste programma) zodat ze niet langer overlappen. Op deze manier passen de verschillende programma's in de verschillende delen (gebieden) van het geheugen.
Met dit alles is het mogelijk dat één routine in het ene programma een routine in een ander programma aanroept. De compiler zorgt dus voor de koppeling. Koppelen verwijst naar het hebben van het startadres van een subroutine in het ene programma en het vervolgens aanroepen ervan in een ander programma; die beide deel uitmaken van de aanvraag. Hiervoor moeten beide programma's hetzelfde adres gebruiken. Het eindresultaat is één grote objectcode met alles in binair getal (bits).
5.15 Een programma opslaan, laden en uitvoeren
Een assembleertaal wordt normaal gesproken geschreven in een of ander editorprogramma (dat mogelijk bij het assembler-programma wordt geleverd). Het editorprogramma geeft aan waar het programma begint en eindigt in het geheugen (RAM). De Kernal SAVE routine van de OS ROM van de Commodore-64 kan een programma in het geheugen op schijf opslaan. Het dumpt alleen het gedeelte (blok) van het geheugen dat de instructieaanroep kan bevatten, naar de schijf. Het is raadzaam om de aanroepinstructie naar SAVE gescheiden te houden van het programma dat wordt opgeslagen, zodat wanneer het programma vanaf de schijf in het geheugen wordt geladen, het zichzelf niet opnieuw opslaat wanneer het wordt uitgevoerd. Het laden van een assembleertaalprogramma vanaf de schijf is een ander soort uitdaging, omdat een programma zichzelf niet kan laden.
Een programma kan zichzelf niet van de schijf laden naar de plaats waar het begint en eindigt in het RAM-geheugen. De Commodore-64 werd in die tijd normaal gesproken geleverd met een BASIC-tolk om de BASIC-taalprogramma's uit te voeren. Wanneer de machine (computer) wordt ingeschakeld, wordt deze afgehandeld met de opdrachtprompt: READY. Van daaruit kunnen de BASIC-commando's of instructies worden getypt door na het typen op de 'Enter'-toets te drukken. Het BASIC-commando (instructie) om een bestand te laden is:
LOAD “bestandsnaam”,8,1
Het commando begint met het BASIC gereserveerde woord LOAD. Dit wordt gevolgd door een spatie en vervolgens de bestandsnaam tussen dubbele aanhalingstekens. Daarna wordt het apparaatnummer 8 gevolgd, voorafgegaan door een komma. Het secundaire adres voor de schijf, namelijk 1, wordt gevolgd, voorafgegaan door een komma. Bij zo'n bestand staat het startadres van het assembleertaalprogramma in de header van het bestand op de schijf. Wanneer de BASIC klaar is met het laden van het programma, wordt het laatste RAM-adres plus 1 van het programma geretourneerd. Het woord “teruggegeven” betekent hier dat de lagere byte van het laatste adres plus 1 in het µP X-register wordt geplaatst, en de hogere byte van het laatste adres plus 1 in het µP Y-register wordt geplaatst.
Na het laden van het programma moet het worden uitgevoerd (uitgevoerd). De gebruiker van het programma moet het startadres voor uitvoering in het geheugen kennen. Ook hier is een ander BASIC-programma nodig. Het is het SYS-commando. Na het uitvoeren van de SYS-opdracht wordt het assembleertaalprogramma uitgevoerd (en gestopt). Als er tijdens het uitvoeren invoer via het toetsenbord nodig is, moet het assembleertaalprogramma dit aan de gebruiker doorgeven. Nadat de gebruiker de gegevens op het toetsenbord heeft ingevoerd en op de “Enter”-toets heeft gedrukt, blijft het assembleertaalprogramma draaien met behulp van de toetsenbordinvoer zonder tussenkomst van de BASIC-interpreter.
Ervan uitgaande dat het begin van het uitvoerende (lopende) RAM-adres voor het Assembleertaalprogramma C12316 is, wordt C123 geconverteerd naar basis tien voordat het wordt gebruikt met de SYS-opdracht. Het converteren van C12316 naar basis tien gaat als volgt:
Het BASIC SYS-commando is dus:
SYS 49443
5.16 Opstarten voor Commodore-64
Het opstarten van de Commodore-64 bestaat uit twee fasen: de hardware-resetfase en de initialisatiefase van het besturingssysteem. Het besturingssysteem is de Kernal in ROM (en niet op een schijf). Er is een resetlijn (eigenlijk RES ) die wordt aangesloten op een pin op de 6502 µP, en op dezelfde pinnaam in alle speciale schepen zoals de CIA 1, CIA 2 en VIC II. In de resetfase worden dankzij deze lijn alle registers in de µP en in speciale chips op 0 gezet (voor elke bit op nul gezet). Vervolgens worden door de hardware van de microprocessor de stapelwijzer en het processorstatusregister met hun initiële waarden in de microprocessor gegeven. De programmateller wordt dan gegeven met de waarde (adres) in de $FFFC- en $FFFD-locaties. Bedenk dat de programmateller het adres van de volgende instructie bevat. De inhoud (adres) die hier wordt bewaard, is voor de subroutine waarmee de software-initialisatie begint. Tot nu toe wordt alles gedaan door de hardware van de microprocessor. In deze fase wordt niet de hele herinnering aangeraakt. De volgende fase van initialisatie begint dan.
De initialisatie wordt gedaan door enkele routines in het ROM OS. Initialisatie betekent het geven van de initiële of standaardwaarden aan sommige registers in de speciale chips. Initialisatie begint door de initiële of standaardwaarden aan sommige registers in de speciale chips te geven. IRQ , moet bijvoorbeeld elke 1/60 seconde beginnen uit te geven. De corresponderende timer in CIA #1 moet dus op de standaardwaarde worden ingesteld.
Vervolgens voert de Kernal een RAM-test uit. Het test elke locatie door een byte naar de locatie te sturen en deze terug te lezen. Als er al een verschil is, is die locatie in ieder geval slecht. Kernal identificeert ook de bovenkant van het geheugen en de onderkant van het geheugen en stelt de overeenkomstige verwijzingen in op pagina 2. Als de bovenkant van het geheugen $DFFF is, wordt $FF op de locatie $0283 geplaatst en wordt $DF op de bytelocatie $0284 geplaatst. Zowel $0283 als $0284 hebben het HIRAM-label. Als de onderkant van het geheugen $0800 is, wordt $00 op de $0281-locatie geplaatst en $08 op de $0282-locatie. Zowel $0281 als $0282 hebben het LORAM-label. De RAM-test begint feitelijk vanaf $ 0300 tot de bovenkant van het geheugen (RAM).
Ten slotte worden de invoer-/uitvoervectoren (aanwijzers) ingesteld op hun standaardwaarden. De RAM-test begint feitelijk vanaf $ 0300 tot de bovenkant van het geheugen (RAM). Dit betekent dat pagina 0, pagina 1 en pagina 2 worden geïnitialiseerd. Vooral pagina 0 heeft veel OS ROM-aanwijzers en pagina 2 heeft veel BASIC-aanwijzers. Deze verwijzingen worden variabelen genoemd. Onthoud dat pagina 1 de stapel is. De pointers worden variabelen genoemd omdat ze namen (labels) hebben. In dit stadium wordt het schermgeheugen voor het scherm (monitor) gewist. Dit betekent dat de code van $20 voor ruimte (die toevallig hetzelfde is als ASCII $20) naar de 1000 RAM-schermlocaties wordt gestuurd. Ten slotte start de Kernal de BASIC-interpreter om de BASIC-opdrachtprompt weer te geven die READY bovenaan de monitor (scherm) staat.
5.17 Problemen
De lezer wordt geadviseerd alle problemen in een hoofdstuk op te lossen voordat hij naar het volgende hoofdstuk gaat.
- Schrijf een assembleertaalcode die alle bits van CIA #2-poort A als uitvoer en CIA #2-poort B als invoer maakt.
- Schrijf een 6502-assembly-taalcode die wacht op een klaviertoets totdat deze wordt ingedrukt.
- Schrijf een 6502-assembly taalprogramma dat het “E” karakter naar het Commodore-64 scherm stuurt.
- Schrijf een 6502-assembly taalprogramma dat een teken van het toetsenbord neemt en dit naar het Commodore-64 scherm stuurt, waarbij de sleutelcode en timing worden genegeerd.
- Schrijf een 6502-assembly taalprogramma dat een byte ontvangt van de Commodore-64 diskette.
- Schrijf een 6502-assembly taalprogramma dat een bestand opslaat op de Commodore-64 diskette.
- Schrijf een 6502-assembly taalprogramma dat een programmabestand van de Commodore-64 diskette laadt en start.
- Schrijf een 6502-assembly taalprogramma dat de byte “E” (ASCII) naar de modem stuurt die is aangesloten op de RS-232-compatibele gebruikerspoort van de Commodore-64.
- Leg uit hoe tellen en timing worden gedaan op de Commodore-64 computer.
- Leg uit hoe de Commodore-64 systeemeenheid 10 verschillende bronnen van onmiddellijke interruptverzoeken kan identificeren, inclusief de niet-maskeerbare interruptverzoeken.
- Leg uit hoe een achtergrondprogramma kan draaien met een voorgrondprogramma op de Commodore-64 computer.
- Leg kort uit hoe de assembleertaalprogramma's kunnen worden gecompileerd tot één applicatie voor de Commodore-64 computer.
- Leg in het kort het opstartproces van de Commodore-64 computer uit.