Snel overzicht
Dit bericht zal aantonen:
Hoe u de ReAct-logica met documentopslag in LangChain implementeert
- Kaders installeren
- Het verstrekken van OpenAI API-sleutel
- Bibliotheken importeren
- Wikipedia-verkenner gebruiken
- Het model testen
Hoe implementeer ik de ReAct-logica met documentopslag in LangChain?
De taalmodellen worden getraind op een enorme hoeveelheid gegevens die zijn geschreven in natuurlijke talen zoals Engels, enz. De gegevens worden beheerd en opgeslagen in de documentarchieven en de gebruiker kan eenvoudig de gegevens uit de opslag laden en het model trainen. De modeltraining kan meerdere iteraties duren, omdat elke iteratie het model effectiever en beter maakt.
Om het proces van het implementeren van ReAct-logica voor het werken met de documentopslag in LangChain te leren, volgt u eenvoudigweg deze eenvoudige handleiding:
Stap 1: Frameworks installeren
Ga eerst aan de slag met het implementeren van de ReAct-logica voor het werken met de documentopslag door het LangChain-framework te installeren. Door het LangChain-framework te installeren, worden alle vereiste afhankelijkheden verkregen om de bibliotheken op te halen of te importeren om het proces te voltooien:
pip installeer langchain
Installeer de Wikipedia-afhankelijkheden voor deze handleiding, omdat deze kunnen worden gebruikt om de documentarchieven te laten werken met de ReAct-logica:
pip installeer wikipedia 
Installeer de OpenAI-modules met behulp van de pip-opdracht om de bibliotheken op te halen en grote taalmodellen of LLM's te bouwen:
pip installeer openai 
Stap 2: OpenAI API-sleutel verstrekken
Na het installeren van alle benodigde modules, eenvoudig de omgeving opzetten met behulp van de API-sleutel van het OpenAI-account met behulp van de volgende code:
importeren Jijimporteren Krijg een pas
Jij . ongeveer [ 'OPENAI_API_KEY' ] = Krijg een pas . Krijg een pas ( 'OpenAI API-sleutel:' )
Stap 3: Bibliotheken importeren
Zodra de omgeving is ingesteld, importeert u de bibliotheken uit de LangChain die nodig zijn om de ReAct-logica te configureren voor het werken met de documentarchieven. LangChain-agents gebruiken om de DocstoreExplaorer en agenten met zijn typen op te halen om het taalmodel te configureren:
van langketen. llms importeren Open AIvan langketen. docstore importeren Wikipedia
van langketen. agenten importeren initialiseer_agent , Hulpmiddel
van langketen. agenten importeren Agenttype
van langketen. agenten . Reageer . baseren importeren DocstoreExplorer
Stap 4: Wikipedia Explorer gebruiken
Configureer de “ docstore ”variabele met de DocstoreExplorer()-methode en roep de Wikipedia()-methode aan in zijn argument. Bouw het grote taalmodel met behulp van de OpenAI-methode met de “ tekst-davinci-002 ”-model na het instellen van de tools voor de agent:
docstore = DocstoreExplorer ( Wikipedia ( ) )hulpmiddelen = [
Hulpmiddel (
naam = 'Zoekopdracht' ,
func = docstore. zoekopdracht ,
beschrijving = 'Het wordt gebruikt voor het stellen van vragen/prompts bij het zoeken' ,
) ,
Hulpmiddel (
naam = 'Opzoeken' ,
func = docstore. opzoeken ,
beschrijving = 'Het wordt gebruikt voor het stellen van vragen/prompts met opzoeken' ,
) ,
]
llm = Open AI ( temperatuur = 0 , modelnaam = 'tekst-davinci-002' )
#definiëren van de variabele door het model met de agent te configureren
Reageer = initialiseer_agent ( hulpmiddelen , llm , tussenpersoon = Agenttype. REACT_DOCSTORE , uitgebreid = WAAR )
Stap 5: Het model testen
Zodra het model is gebouwd en geconfigureerd, stelt u de vraagtekenreeks in en voert u de methode uit met de vraagvariabele in het argument:
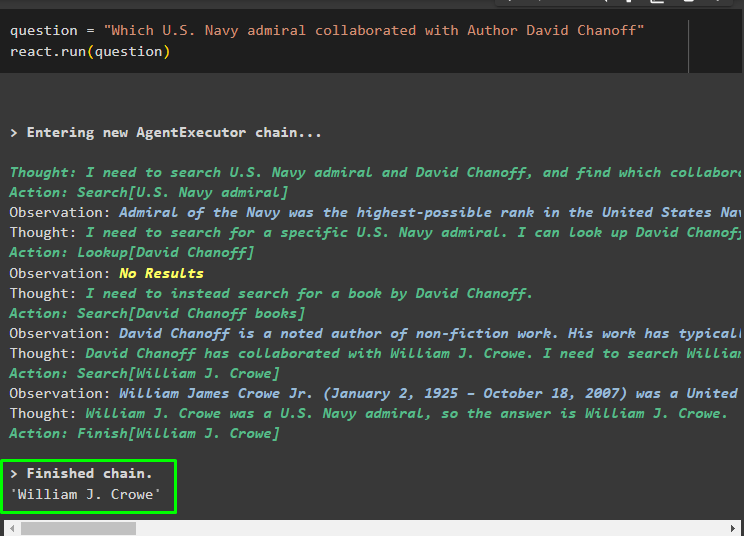
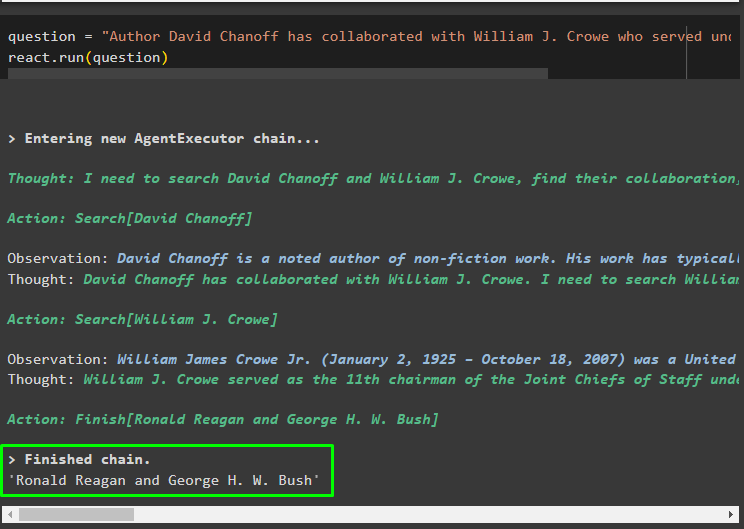
vraag = 'Welke admiraal van de Amerikaanse marine werkte samen met auteur David Chanoff'Reageer. loop ( vraag )
Zodra de vraagvariabele is uitgevoerd, heeft het model de vraag begrepen zonder enige externe promptsjabloon of training. Het model wordt automatisch getraind met behulp van het model dat in de vorige stap is geüpload en dienovereenkomstig tekst gegenereerd. De ReAct-logica werkt samen met de documentarchieven om informatie te extraheren op basis van de vraag:
Stel nog een vraag op basis van de gegevens die vanuit de documentopslag aan het model zijn verstrekt, en het model haalt het antwoord uit de opslag:
vraag = 'Auteur David Chanoff heeft samengewerkt met William J. Crowe, die onder welke president heeft gediend?'Reageer. loop ( vraag )
Dat draait allemaal om het implementeren van de ReAct-logica voor het werken met de documentopslag in LangChain.
Conclusie
Om de ReAct-logica te implementeren voor het werken met de documentopslag in LangChain, installeert u de modules of raamwerken voor het bouwen van het taalmodel. Stel daarna de omgeving in voor OpenAI om de LLM te configureren en het model uit het documentarchief te laden om de ReAct-logica te implementeren. In deze handleiding wordt dieper ingegaan op de implementatie van de ReAct-logica voor het werken met de documentopslag.