Schaalbaarheid
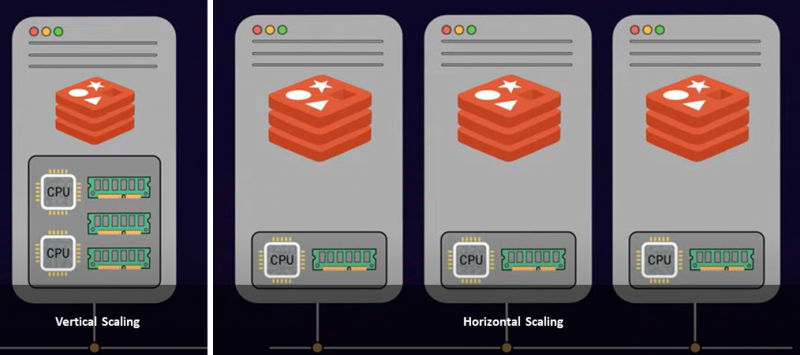
Er zijn twee algemene benaderingen voor het schalen van een server: verticaal schalen en horizontaal schalen. Verticaal schalen of opschalen is waar u meer kracht en bronnen aan uw server toevoegt, zoals meer CPU's, geheugen en opslag, wat kostbaar is. Aan de andere kant is horizontaal schalen het toevoegen van meerdere knooppunten aan uw bestaande resourcepool. Dit heet uitschalen. Dus, op basis van uw beperkingen en vereisten, is het aan u om één grotere serverinstantie te hebben of meerdere serverknooppunten te implementeren.
Stel dat u 100 GB RAM hebt en 200 GB aan gegevens moet bewaren. In dit geval heeft u twee keuzes:
- Schaal op door meer RAM aan het systeem toe te voegen
- Schaal uit door nog een serverinstantie toe te voegen met 100 GB RAM
Als je de maximale RAM-limiet binnen je infrastructuur hebt bereikt, dan is scalen out de ideale aanpak. Bovendien zal uitschaling de doorvoer van de database met een enorme marge verhogen.
Redis Sharding
Het is een bekend feit dat Redis op een enkele thread werkt. Redis is dus niet in staat om meerdere kernen van de CPU van uw server te gebruiken om opdrachten te verwerken. Daarom geeft het toevoegen van meer CPU-kernen u niet veel doorvoer of prestaties met Redis. Dit is niet het geval bij het splitsen van uw gegevens over meerdere serverinstanties. Door meerdere servers toe te voegen en de dataset daaronder te verdelen, kunnen clientverzoeken parallel worden verwerkt, wat de doorvoer verhoogt. Bovendien kunnen de algehele prestaties bijna lineair toenemen.
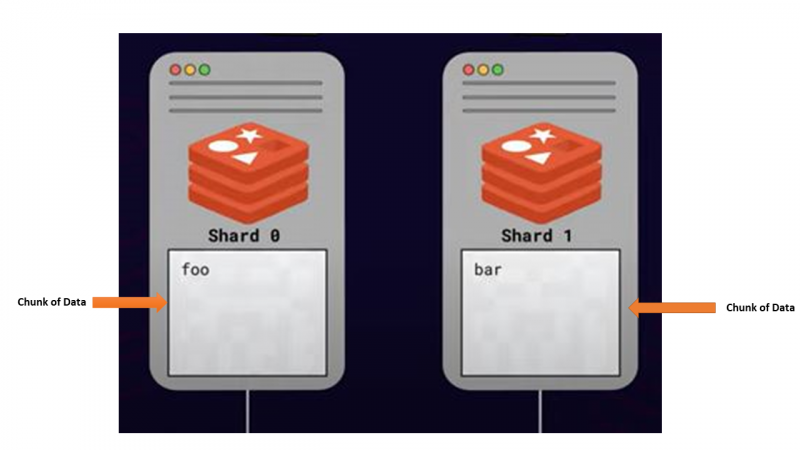
Deze benadering van het splitsen of distribueren van gegevens over meerdere servers met het oog op schaalvergroting wordt genoemd scherven . Alle servers die delen van gegevens opslaan, worden aangeroepen scherven .
Hoe Sharding wordt gedaan - Algoritmische Sharding
Een van de grootste zorgen bij sharding was hoe een bepaalde sleutel tussen meerdere Redis-knooppunten kon worden gevonden. Omdat een bepaalde sleutel in alle beschikbare shards kan worden opgeslagen, is het niet de beste optie om alle shards te doorzoeken om een specifieke sleutel te vinden. Er zou dus een manier moeten zijn om elke sleutel aan een specifieke shard toe te wijzen, en Redis gebruikt een algoritmische shardingstrategie.
De meest gebruikelijke benadering is het berekenen van een hash-waarde met behulp van de Redis-sleutelnaam en modulo. Deel het vervolgens door de beschikbare Redis-scherven in het systeem.
HASH_SLOT = CRC16(sleutel) mod 16384Het is best een goede oplossing zolang het totale aantal scherven constant is. Telkens wanneer u een nieuwe Reids-serverinstantie toevoegt, kan de resulterende waarde voor een bepaalde sleutel veranderen omdat het totale aantal shards is toegenomen. Het zal uiteindelijk de verkeerde Redis-scherf opvragen. Daarom moet u het reshardingproces volgen door de nieuwe shard voor elke sleutel te berekenen en gegevens over te dragen naar de juiste server, wat omslachtig is en geen triviale taak als uw totale aantal shards van tijd tot tijd toeneemt.
Redis gebruikt een nieuwe logische entiteit genaamd a hash-slot om dit probleem te voorkomen. Er zijn verschillende hash-slots beschikbaar voor een bepaalde shard en een enkele hash-slot kan meerdere Redis-sleutels bevatten. Er zijn 16384 hash-slots in een Redis-databasecluster die ongewijzigd blijft. De modulo-verdeling wordt gedaan met het aantal hash-slots in plaats van het aantal shards. Het biedt de juiste positie van de hash-sleuf voor de opgegeven sleutel, zelfs wanneer het aantal scherven is toegenomen. Het vereenvoudigt het resharding-proces door de hash-slots van de ene shard naar de nieuwe te verplaatsen die de gegevens over de verschillende Redis-instanties verdeelt volgens de vereiste.
Voordelen van Redis Sharding
Redis-sharding biedt verschillende voordelen voor uw databasesysteem met minimale wijzigingen.
Hoge doorvoer
Aangezien Redis single-threaded is, kan het verwerken van meerdere clientverzoeken niet parallel worden verwerkt met behulp van meerdere CPU-kernen. Het toevoegen van nieuwe shards of serverinstanties garandeert dus dat u Redis-bewerkingen parallel kunt uitvoeren. Het verhoogt de bewerkingen per seconde in uw Redis-database, wat u uiteindelijk een hoge doorvoer geeft.
Hoge beschikbaarheid
Met de sharding-benadering kan het Redis-cluster een master-replica-architectuur opzetten die een hoge beschikbaarheid en duurzaamheid garandeert.
Replica's lezen
Met sharding kunt u een exacte kopie van uw gegevens bewaren en leesbewerkingen uitvoeren via afzonderlijke Redis-instanties, waardoor de uitvoering van uw leesquery's verbetert.
Afgezien van deze voordelen kan sharding split-brain-situaties veroorzaken wanneer je een even aantal shards in het Redis-cluster hebt. Het wordt dus aanbevolen om een oneven aantal scherven in uw Redis-cluster te houden.
Conclusie
Samengevat: Redis-sharding is het splitsen van gegevens over meerdere servers, wat schaalvergroting en een hoge doorvoer voor uw database mogelijk maakt. Zoals besproken, gebruikt Redis een algoritmische shardingstrategie om clientverzoeken naar de juiste shard te verwijzen. Dit heeft enkele nadelen wanneer het totale aantal scherven toeneemt. Dus in plaats van het totale aantal shards, gebruikt Redis het aantal hash-slots om de juiste shard te berekenen. Met de introductie van sharding bieden Redis-databases hoge beschikbaarheid, hoge doorvoer en hoge prestaties.