Hoe gebruik je de Panda's Case Statement?
Case-statements kunnen op verschillende manieren worden gemaakt. De functie NumPy where(), die de volgende fundamentele syntaxis gebruikt, is de eenvoudigste manier om een case-statement te construeren in een Pandas DataFrame:
df [ 'kolomnaam' ] = np.waar ( voorwaarde 1 , ‘waarde1’,np.waar ( voorwaarde twee , ‘waarde2’,
np.waar ( voorwaarde 3 , ‘waarde3’, ‘waarde4’ ) ) )
De bovenstaande instructie controleert elke voorwaarde voor de waarde en, als aan de voorwaarde wordt voldaan, genereert de uitvoer of retourneert de waarde tegen de voorwaarde.
Voorbeeld # 1: Panda's Case Statement met de functie where()
Laten we eerst een dataframe maken, zodat we onze case-statement kunnen gebruiken. Om het dataframe te maken, zullen we eerst de numpy- en panda's-modules importeren, zodat we hun functionaliteiten kunnen gebruiken. Het pd.Dataframe() wordt gebruikt om ons dataframe te maken.

We hebben het ‘df’ dataframe gemaakt. Een Python-woordenboek wordt doorgegeven binnen de pd.DataFrame()-functies als een argument met sleutels en waarden. We zullen de functie print() gebruiken om ons dataframe te zien.
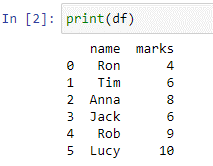
In het 'df' dataframe hebben we twee kolommen “name” en “marks” met waarden ['Ron', 'Tim', 'Anna', 'Jack', 'Rob', 'Lucy'] en [4, 6 , 8, 6, 9,10] respectievelijk. Stel dat die naam de kolommen zijn die de namen van studenten bevatten en de kolom 'cijfers' de score van een recente test. Nu zullen we een case-statement schrijven dat een nieuwe kolom met de naam 'opmerkingen' toevoegt waarvan de waarden zijn gebaseerd op de waarden die door ons zijn opgegeven, voor elke voorwaarde.

De methode 'numpy.where()' levert de elementindexen uit een invoerarray, kolom of lijst die voldoen aan de opgegeven voorwaarde. In het bovenstaande schakelgeval controleert de functie np.where() elk element in de kolommen 'markeringen'. Als de waarde gelijk is aan of kleiner is dan 5, wordt als uitvoer 'mislukt' geretourneerd. Als de waarde kleiner is dan of gelijk is aan 7, wordt bevredigend geretourneerd, en als de waarde kleiner is dan of gelijk is aan 9, wordt 'geweldig' geretourneerd. Als er geen zijn, is het resultaat uitstekend.
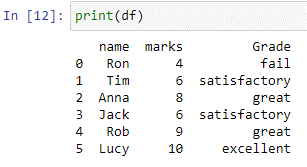
Zoals kan worden opgemerkt, wordt de nieuwe kolom 'opmerkingen' gemaakt in ons 'df'-gegevensframe, waarin de waarden worden opgeslagen die worden geretourneerd door de bovenstaande casusverklaring.
Voorbeeld #2:
Laten we de bovenstaande casus opnieuw proberen met een ander dataframe. Stel dat we spelers moeten beoordelen op basis van hun totale doelpunten in het vorige voetbaltoernooi. Laten we dus een dataframe maken om voetbalspelerrecords op te slaan.
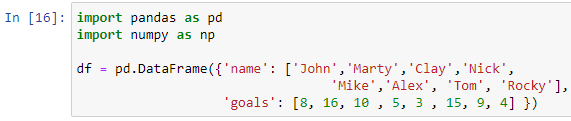
We hebben een woordenboek doorgegeven met de toetsen 'naam' en 'doelen' in de functie pd.DataFrame() om ons dataframe te maken. Om ons dataframe af te drukken, gebruiken we de printfunctie.
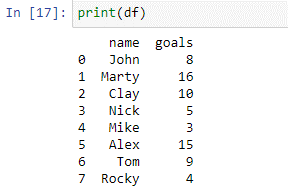
Zoals te zien is in het bovenstaande gegevensframe, hebben we twee kolommen: 'naam' en 'doelen'. In de kolomnaam hebben we de namen van spelers [‘John’, ‘Marty’, ‘Clay’, ‘Nick’, ‘Mike’, ‘Alex’, ‘Tom’, ‘Rocky’]. In de 'kolom' doelen hebben we het totale aantal doelpunten van elke speler in het vorige toernooi. We zullen nu onze case-statement gebruiken om deze spelers te beoordelen op basis van de doelpunten die ze hebben gescoord.

Het bovenstaande geval wordt gemaakt met behulp van de functie where(). In de case controleert de statement-functie elk element in de kolommen 'markeringen' aan de hand van de voorwaarden. Als de waarde in de kolom 'doelen' gelijk is aan of kleiner is dan 5, wordt 'C' geretourneerd. Als de waarde in de kolom 'doelen' gelijk is aan of kleiner is dan 9, wordt 'B' geretourneerd. Het retourneert een 'A' als de waarde in de kolom 'goals' gelijk is aan of groter is dan 10. De waarden die door het statement worden geretourneerd, worden opgeslagen in de nieuwe kolom 'rating'. Laten we de 'df' afdrukken om de resultaten te zien.
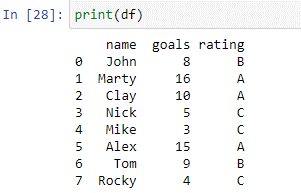
De nieuwe kolom 'beoordeling' is met succes gemaakt met behulp van het bovenstaande script.
Voorbeeld # 3: Panda's if-else-instructie met behulp van de functie Apply()
De rij- of kolomas van het dataframe wordt gebruikt door de methode apply() om een functie te implementeren. We kunnen onze eigen gedefinieerde functie maken en deze gebruiken in ons dataframe in panda's. Het zal if- else-voorwaarden bevatten. Laten we eerst ons dataframe maken, dan zullen we een functie maken waarin we een if-else-statement zullen gebruiken om het resultaat te genereren. Om ons dataframe te maken, importeren we eerst de module van de panda's, daarna geven we een woordenboek door in de pd.DataFrame()-methode.
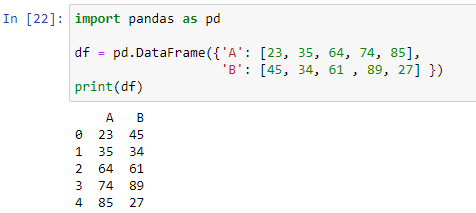
Zoals te zien is, bestaat ons dataframe uit twee kolommen 'A' met numerieke waarden [23, 35, 64, 74, 85] en 'B' met waarden [45, 34, 61, 89, 27]. Nu gaan we een functie maken die bepaalt welke waarde groter is tussen beide kolommen in elke rij van ons dataframe.
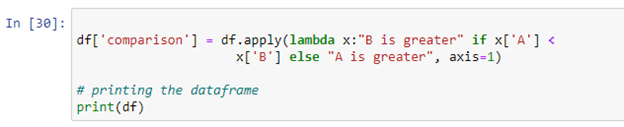
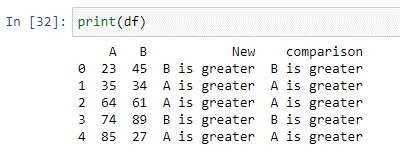
U kunt de Python lambda-functie 'panda's. DataFrame.apply()” om een expressie uit te voeren. In Python is een lambda-functie een compacte anonieme functie die een willekeurig aantal argumenten accepteert en een expressie uitvoert. In het bovenstaande script hebben we een voorwaarde-instructie gemaakt die de waarde van beide kolommen vergelijkt en het resultaat opslaat in de nieuwe kolom 'vergelijking'. Als de waarde van kolom 'A' kleiner is dan de waarde van kolom 'B', wordt 'B is groter' geretourneerd. Als niet aan de voorwaarde wordt voldaan, wordt 'A is groter' geretourneerd.
Voorbeeld #4:
Laten we een ander voorbeeld proberen met de if-else-instructie in de functie Apply() met een ander gegevensframe.
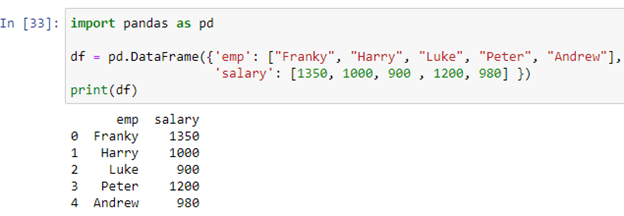
Stel dat ons dataframe gegevens van werknemers van een bedrijf opslaat. De kolom 'werknemer' slaat de namen op van werknemers [“Franky”, “Harry”, “Luke”, “Peter”, “Andrew”], terwijl de kolom “salaris” de salarissen van elke werknemer opslaat [1350, 1000, 900 , 1200, 980] in het 'df' dataframe. Nu zullen we onze if-else-instructie maken met behulp van de methode apply().

De bovenstaande voorwaarde controleert elke waarde in kolom 'salaris' en voegt 200 toe aan de salarissen van werknemers waarvan de salariswaarde kleiner is dan of gelijk is aan 1000. We hebben de waarden die zijn geretourneerd door de functie Apply() opgeslagen in de nieuwe kolom ' ophogen'. Laten we de resultaten van het bovenstaande script bekijken.
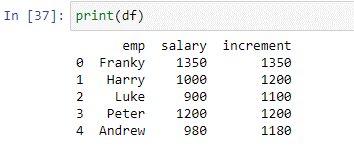
Zoals u kunt zien, heeft de functie met succes 200 toegevoegd aan de waarden die kleiner dan of gelijk aan 100 waren. De waarden die groter waren dan 1000 bleven ongewijzigd.
Conclusie:
In deze zelfstudie hebben we gezien dat wanneer aan de voorwaarde is voldaan, een instructie van dit type, een case-instructie genoemd, een waarde retourneert. We hebben gezien hoe u een case-statement kunt maken om een vereiste bewerking of taak uit te voeren. In deze zelfstudie hebben we de functie np.where() en de functie Apply() gebruikt om case-statements te maken. We hebben een paar voorbeelden geïmplementeerd om u te leren hoe u panda's case-statements gebruikt met de functie where() en hoe u de functie Apply() gebruikt om case-statements te maken.