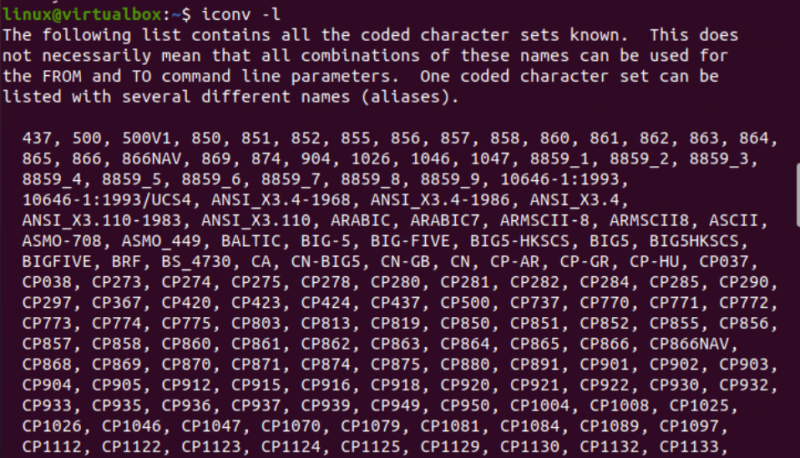
Laten we nu eens kijken naar het iconv-hulpprogramma van Linux in de terminalconsole. We hebben dus de instructie 'iconv' uitgevoerd met de vlag '-l' om alle bekende en meest gebruikte gecodeerde tekensets op ons terminalscherm weer te geven. Het toont de gecodeerde tekensets samen met hun aliassen. U kunt een lange lijst met gecodeerde tekensets zien nadat u een beetje naar beneden hebt gescrold.
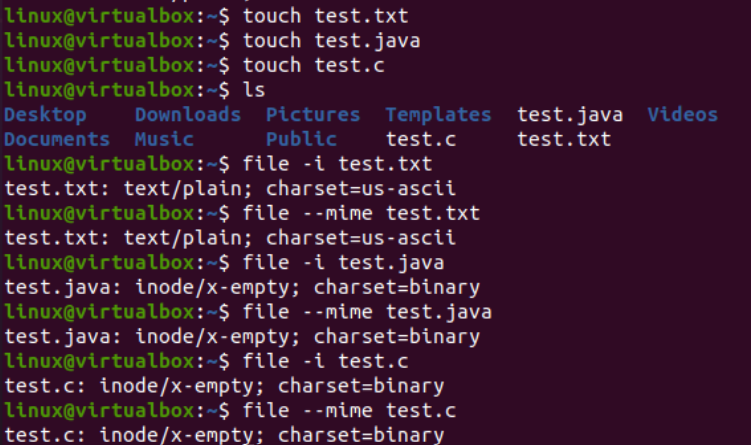
Nu is het tijd om aan de slag te gaan met de implementatie van de iconv-opdracht in Linux. Ten eerste hebben we verschillende soorten bestanden in ons systeem nodig om het ene type bestand naar een ander type te converteren. Daarom gebruiken we de 'touch'-query op de consoleterminal om drie verschillende bestanden te maken, namelijk Java-type, C-type en teksttype. Door de huidige directory-inhoud op te sommen, vindt u de nieuw gegenereerde bestanden erin.
Hierna zullen we het type van elk bestand afzonderlijk bekijken met behulp van de 'bestand' -query samen met de naam van elk bestand. Deze query heeft de optie '-I' nodig om het type coderingstekenset voor elk bestand afzonderlijk weer te geven. Als u bent vergeten de optie '-I' te gebruiken, gebruikt u in plaats daarvan de vlag '-mime'. Zowel de vlaggen '-I' als '-mime' werken hetzelfde.
Nu, na het uitvoeren van de 'file' -instructie voor het 'txt' -typebestand, kregen we de 'US-ASCII' -tekentypecodering. Terwijl dezelfde instructie wordt gebruikt voor de Java- en C-bestanden, laat het zien dat beide bestanden 'BINARY' tekentypecodering bevatten. Daarnaast laat deze instructie zien dat al deze drie bestanden leeg zijn.
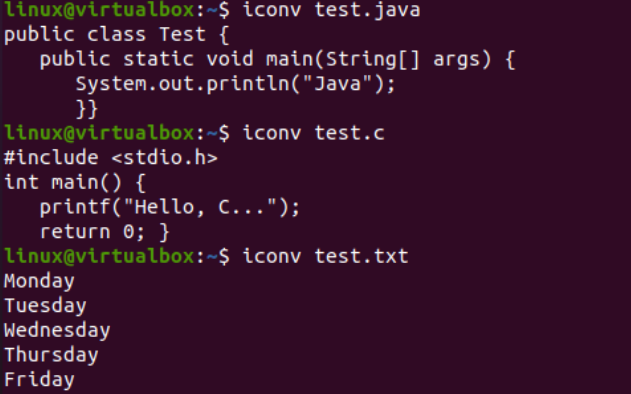
Nu zullen we het gebruik van iconv-instructies op de console illustreren om een specifiek tekensetcoderingsbestand te converteren naar een andere tekensetcodering. Daarvoor moeten we wat code of gegevens aan onze bestanden toevoegen. Daarom hebben we de Java-code toegevoegd aan het bestand 'text.java', C-code aan het bestand 'text.c', en tekstgegevens toegevoegd aan het bestand 'test.txt'. De cat-query werd hier gebruikt om de inhoud van alle drie de bestanden weer te geven, zoals hieronder weergegeven:
Nu we de gegevens met succes hebben toegevoegd, zullen we de tekensetcodering van deze bestanden opnieuw zien. We hebben dus dezelfde bestandsinstructie in de shell geprobeerd met de vlag '-I' en de bestandsnamen, d.w.z. test.txt, test.java en test.c. Als u deze drie instructies afzonderlijk uitvoert voor alle drie de bestanden, ziet u dat de tekensetcodering is bijgewerkt voor de Java- en C-bestanden, terwijl deze hetzelfde is gebleven voor het tekstbestand, d.w.z. US-ASCII. De codering van Java- en C-bestanden was voorheen 'binair'; nu is het 'US-ASCII'. Het laat ook zien dat het tekstbestand platte tekstgegevens bevat, terwijl de andere twee codebestanden de scripts als inhoud bevatten.

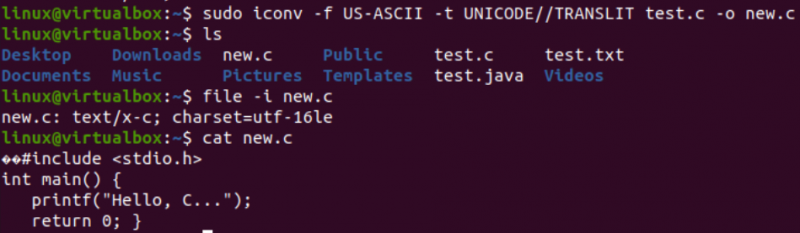
Het is tijd om de eigenlijke taak uit te voeren die nodig is voor dit artikel, d.w.z. de ene codering naar de andere converteren met behulp van de iconv-opdracht in de shell. We hebben dus de 'iconv' -instructie in de shell-terminal gebruikt met de 'sudo' -rechten. Deze opdracht neemt de '-f' optie staat voor 'from', en de '-t' optie staat voor 'to', d.w.z. van de ene codering naar de andere.
Na de optie '-f' moet u de codering specificeren die uw bestand al heeft, d.w.z. US-ASCII. Terwijl u na de '-t' -optie de codering moet specificeren die u wilt vervangen door de oude codering, d.w.z. UNICODE. U moet de naam opgeven van een bestand dat als bron wordt gebruikt met de optie –o om de objectafbeelding te maken. De objectafbeelding zou een ander bestand zijn, d.w.z. 'new.c', van hetzelfde type maar met de nieuwe codering en dezelfde gegevens.
Na het uitvoeren van de volgende instructie, krijgt u een nieuw bestand in dezelfde map, d.w.z. volgens de 'ls'-query. Nu zullen we controleren op de tekensetcodering van een nieuw bestand dat is gegenereerd met behulp van de iconv-instructie. We zullen opnieuw de instructie 'bestand' gebruiken met de optie '-I' en de nieuwe bestandsnaam, d.w.z. new.c.
U zult zien dat de tekenset voor dit nieuwe bestand verschilt van de tekenset van een oud bestand, d.w.z. de UTF-16LE-tekenset. Dit komt omdat we de US-ASCII-codering hebben vertaald naar de UNICODE-codering met behulp van de iconv-instructie voor ons nieuwe.c-bestand. De 'cat'-query toonde dezelfde C-code in het bestand, maar begon met enkele Unicode-tekens, zoals al gepresenteerd.
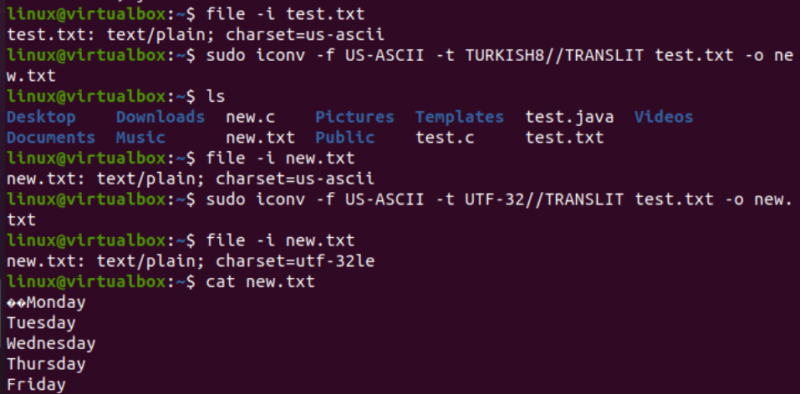
Op een vergelijkbare manier zullen we de codering van het test.txt-tekstbestand wijzigen. De bestandsinstructie laat zien dat het een US-ASCII-tekensetcodering heeft. Het iconv-commando is met precies hetzelfde formaat gebruikt om de codering van het test.txt-bestand van US-ASCII naar TURKISH8 te converteren. Je zult zien dat het de US-ASCII niet verandert in Turks.
Hierna gebruikten we dezelfde opdracht om US-ASCII naar UTF-32 tekensetcodering voor hetzelfde bestand te dekken. Deze keer werkt het. Dit komt omdat er soms een probleem kan zijn bij het converteren van de ene coderingsset naar een andere, of omdat de andere codering dit mogelijk niet ondersteunt.
Conclusie
In dit artikel wordt besproken hoe u de iconv Linux-instructies kunt gebruiken om de ene codeertekenset naar een andere te converteren met behulp van hun aliassen. Op deze manier moesten we een aantal bestanden van verschillende typen maken.