Verzameling maken
Voordat we indexen gebruiken, moeten we een nieuwe verzameling in onze MongoDB maken. We hebben er al één gemaakt en 10 documenten ingevoegd, genaamd “Dummy”. De find() MongoDB-functie geeft alle records uit de 'Dummy' -verzameling weer op het onderstaande MongoDB-shellscherm.
test> db.Dummy.find() 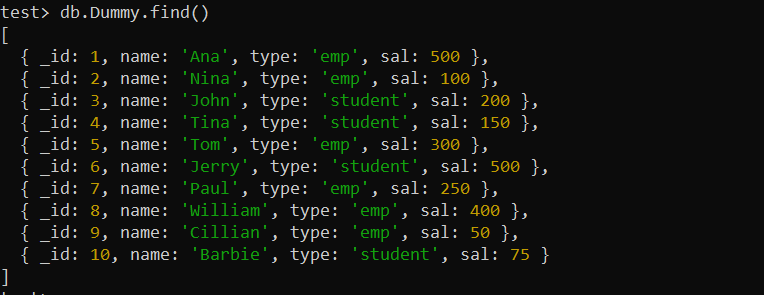
Kies Indexeringstype
Voordat u een index instelt, moet u eerst de kolommen bepalen die gewoonlijk in querycriteria worden gebruikt. Indexen presteren goed op kolommen die vaak worden gefilterd, gesorteerd of doorzocht. Velden met een grote kardinaliteit (veel verschillende waarden) zijn vaak uitstekende indexeringsmogelijkheden. Hier volgen enkele codevoorbeelden voor verschillende indextypen.
Voorbeeld 01: Index van één veld
Het is waarschijnlijk het meest fundamentele type index, dat een enkele kolom indexeert om de querysnelheid op die kolom te verbeteren. Dit type index wordt gebruikt voor query's waarbij u één sleutelveld gebruikt om de collectierecords te doorzoeken. Stel dat u het veld “type” gebruikt om de records van de collectie “Dummy” te doorzoeken binnen de zoekfunctie, zoals hieronder. Met deze opdracht wordt de hele verzameling doorzocht, wat lang kan duren voordat grote verzamelingen zijn verwerkt. Daarom moeten we de prestaties van deze query optimaliseren.
test> db.Dummy.find({type: 'emp' })
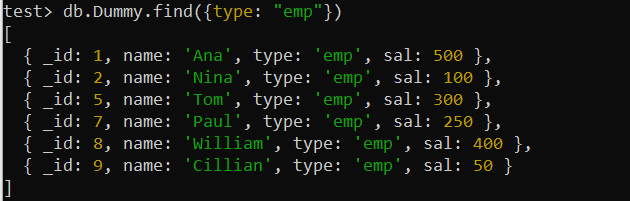
De records van de Dummy-verzameling hierboven zijn gevonden met behulp van het veld 'type', dat wil zeggen dat ze een voorwaarde bevatten. Daarom kan hier de single-key index worden gebruikt om de zoekopdracht te optimaliseren. We zullen dus de createIndex() functie van MongoDB gebruiken om een index te maken op het “type” veld van de “Dummy” collectie. De illustratie van het gebruik van deze query toont de succesvolle creatie van een index met één sleutel met de naam “type_1” op de shell.
test> db.Dummy.createIndex({ type: 1 })Laten we de find()-query gebruiken zodra deze het gebruik van het veld 'type' wint. De bewerking zal nu aanzienlijk sneller zijn dan de eerder gebruikte find()-functie, aangezien de index aanwezig is, omdat MongoDB de index kan gebruiken om snel de records met de gevraagde functietitel op te halen.
test> db.Dummy.find({type: 'emp' })
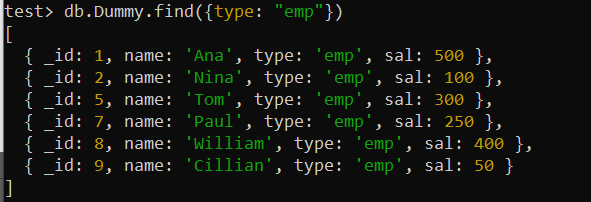
Voorbeeld 02: Samengestelde index
Het kan zijn dat we in bepaalde omstandigheden naar artikelen willen zoeken op basis van verschillende criteria. Het implementeren van een samengestelde index voor deze velden kan de prestaties van query's helpen verbeteren. Laten we zeggen dat u deze keer wilt zoeken in de verzameling 'Dummy' met behulp van meerdere velden met verschillende zoekvoorwaarden terwijl de zoekopdracht wordt weergegeven. Met deze zoekopdracht is gezocht naar records uit de collectie waarbij het veld 'type' is ingesteld op 'emp' en het veld 'sal' groter is dan 350.
De logische operator $gte is gebruikt om de voorwaarde op het veld “sal” toe te passen. Na het doorzoeken van de gehele collectie, die uit 10 records bestaat, zijn in totaal twee records teruggekomen.
test> db.Dummy.find({type: 'emp' , sal: {$gte: 350 } }) 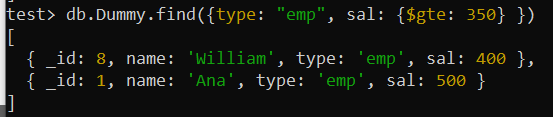
Laten we een samengestelde index maken voor de bovengenoemde zoekopdracht. Deze samengestelde index heeft de velden “type” en “sal”. De cijfers “1” en “-1” vertegenwoordigen respectievelijk de oplopende en aflopende volgorde voor de velden “type” en “sal”. De volgorde van de kolommen van de samengestelde index is belangrijk en moet overeenkomen met de zoekpatronen. De MongoDB heeft de naam “type_1_sal_-1” gegeven aan deze samengestelde index zoals weergegeven.
test> db.Dummy.createIndex({ type: 1 , zullen:- 1 }) 
Na het gebruiken van dezelfde find()-query om te zoeken naar records met de veldwaarde “type” als “emp” en de waarde van het veld “sal” groter dan gelijk aan 350, hebben we dezelfde uitvoer verkregen met een kleine verandering in de volgorde vergeleken met het vorige zoekresultaat. Het record met de grotere waarde voor het veld “sal” staat nu op de eerste plaats, terwijl de kleinste op de laagste plaats staat volgens de “-1” die is ingesteld voor het veld “sal” in de samengestelde index hierboven.
test> db.Dummy.find({type: 'emp' , sal: {$gte: 350 } }) 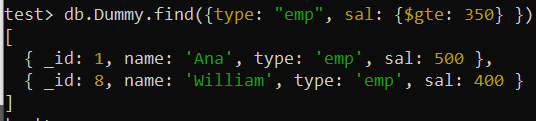
Voorbeeld 03: Tekstindex
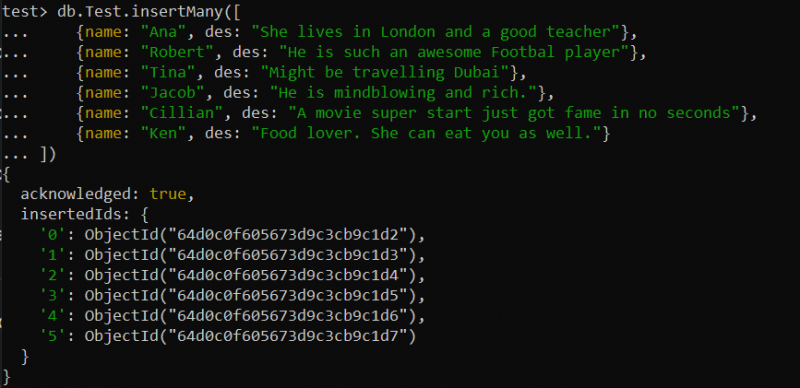
Soms kunt u een situatie tegenkomen waarin u te maken krijgt met een grote dataset, zoals grote beschrijvingen van producten, ingrediënten, enz. Een tekstindex kan handig zijn voor zoekopdrachten in de volledige tekst van een groot tekstveld. We hebben bijvoorbeeld een nieuwe verzameling gemaakt met de naam “Test” binnen onze testdatabase. Er zijn in totaal zes records in deze verzameling ingevoegd met behulp van de functie insertMany() volgens de onderstaande find()-query.
test> db.Test.insertMany([{naam: 'Ana' , van de: 'Ze woont in Londen en is een goede lerares' },
{naam: 'Robert' , van de: 'Hij is zo'n geweldige voetballer' },
{naam: 'van' , van de: 'Misschien op reis naar Dubai' },
{naam: 'Jakob' , van de: 'Hij is verbluffend en rijk.' },
{naam: 'Cillian' , van de: 'Een superstart van een film kreeg binnen enkele seconden bekendheid' },
{naam: 'Ken' , van de: 'Etenliefhebber. Zij kan jou ook opeten.' }
])
Nu gaan we een tekstindex maken in het veld “Des” van deze verzameling, waarbij we de functie createIndex() van MongoDB gebruiken. Het trefwoord “tekst” in de veldwaarde geeft het type index weer, namelijk een “tekst”-index. De indexnaam, des_text, is automatisch gegenereerd.
test> db.Test.createIndex({ des: 'tekst' })Nu is de functie find() gebruikt om de “text-search” op de collectie uit te voeren via de index “des_text”. De operator $search werd gebruikt om in de collectierecords naar het woord ‘voedsel’ te zoeken en dat specifieke record weer te geven.
test> db.Test.find({ $text: { $search: 'voedsel' }}); 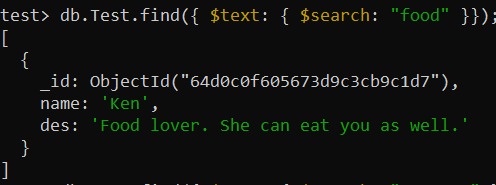
Indexen verifiëren:
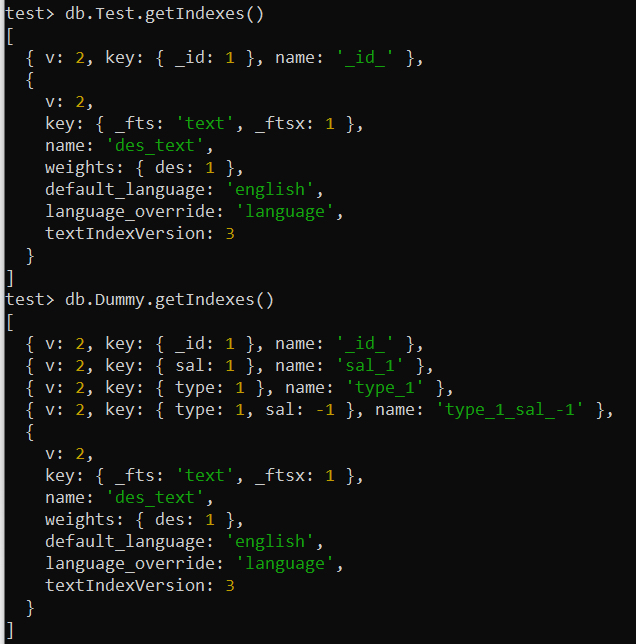
U kunt alle toegepaste indexen van verschillende collecties in uw MongoDB controleren en weergeven. Gebruik hiervoor de methode getIndexes() samen met de naam van een verzameling in uw MongoDB-shellscherm. We hebben deze opdracht afzonderlijk gebruikt voor de verzamelingen 'Test' en 'Dummy'. Hierdoor wordt alle benodigde informatie over de ingebouwde en door de gebruiker gedefinieerde indexen op uw scherm weergegeven.
test> db.Test.getIndexes()test> db.Dummy.getIndexes()
Dalingsindexen:
Het is tijd om de indexen te verwijderen die eerder voor de collectie zijn gemaakt met behulp van de dropIndex() functie, samen met dezelfde veldnaam waarop de index was toegepast. Uit de onderstaande query blijkt dat de enkele index is verwijderd.
test> db.Dummy.dropIndex({type: 1 }) 
Op dezelfde manier kan de samengestelde index worden geschrapt.
test> db.Dummy.drop index({type: 1 , zullen: 1 }) 
Conclusie
Door het ophalen van gegevens uit MongoDB te versnellen, is indexering essentieel voor het verbeteren van de efficiëntie van zoekopdrachten. Bij gebrek aan indexen moet MongoDB de hele collectie doorzoeken op overeenkomende records, wat minder effectief wordt naarmate de set groter wordt. Het vermogen van MongoDB om snel de juiste records te ontdekken met behulp van de indexdatabasestructuur versnelt de verwerking van zoekopdrachten wanneer geschikte indexering wordt gebruikt.