{ naam: 'Alexa-rekening' , cijfer: 'A' , cursus: 'Python' },
{ naam: 'Jane Marks' , cijfer: 'B' , cursus: 'Java' },
{ naam: 'Paul Ken' , cijfer: 'C' , cursus: 'C#' },
{ naam: 'Emily Jeo' , cijfer: 'D' , cursus: 'php' }
]);
We kunnen ook een uniek indexveld maken als de collectie aanwezig is met daarin enkele documenten. Hiervoor voegen we het document in de nieuwe collectie in, namelijk 'kandidaten', waarvan de vraag voor invoeging als volgt wordt gegeven:
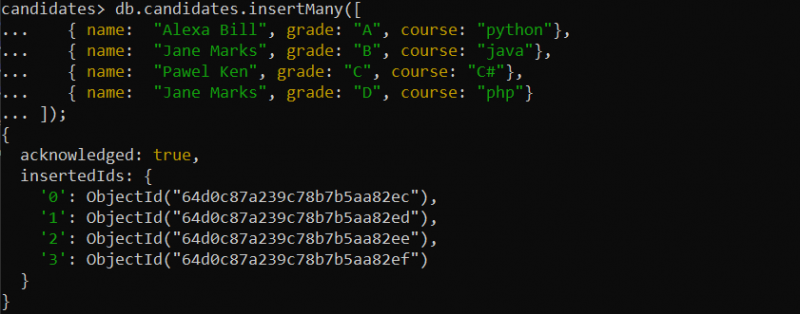
Voorbeeld 1: Maak een unieke index van een enkel veld
We kunnen de index maken met behulp van de createIndex() -methode en we kunnen dat veld uniek maken door de unieke optie op te geven met de Booleaanse waarde 'true'.
db.candidates.createIndex( { cijfer: 1 }, { uniek: waar } )
Hier starten we de createIndex() -methode voor de 'candidates' -collectie om een unieke index van een specifiek veld te maken. Vervolgens geven we het veld “grade” de waarde “1” voor de indexspecificatie. De waarde van “1” vertegenwoordigt hier de oplopende index van de verzameling. Vervolgens specificeren we de “unieke” optie met de “true” waarde om de uniciteit van het veld “grade” af te dwingen.
De uitvoer geeft aan dat de unieke index in het veld “cijfer” is gemaakt voor de verzameling “kandidaten”:

Voorbeeld 2: Maak een unieke index van meer dan één veld
In het vorige voorbeeld wordt slechts één veld aangemaakt als unieke index. Maar we kunnen ook tegelijkertijd twee velden als een unieke index maken met behulp van de createIndex() -methode.
db.candidates.createIndex( { cijfer: 1 , cursus: 1 }, { uniek: waar } )
Hier roepen we de createIndex() -methode aan voor dezelfde 'kandidaten' -verzameling. We specificeren twee velden voor de methode createIndex() – “grade” en “course” – met de waarde “1” als de eerste expressie. Vervolgens stellen we de unieke optie in met de waarde ‘true’ om deze twee unieke velden te maken.
De uitvoer vertegenwoordigt twee unieke indexen, “grade_1” en “course_1”, voor de volgende verzameling “kandidaten”:

Voorbeeld 3: Maak een samengestelde unieke index van de velden
We kunnen echter ook tegelijkertijd een unieke samengestelde index binnen dezelfde collectie creëren. Dit bereiken we via de volgende vraag:
db.candidates.createIndex({ naam: 1 , cijfer: 1 , cursus: 1 }, { uniek: waar }We gebruiken opnieuw de methode createIndex() om de samengestelde unieke index voor de verzameling “kandidaten” te maken. Deze keer passeren we drie velden – ‘cijfer’, ‘naam’ en ‘cursus’ – die fungeren als oplopende indexvelden voor de verzameling ‘kandidaten’. Vervolgens noemen we de optie ‘uniek’ om het veld uniek te maken, aangezien ‘waar’ aan die optie is toegewezen.
De uitvoer geeft de resultaten weer die aantonen dat alle drie de velden nu de unieke index van de opgegeven verzameling zijn:

Voorbeeld 4: Maak een unieke index van dubbele veldwaarden
Nu proberen we de unieke index te maken voor de dubbele veldwaarde, wat een fout veroorzaakt om de uniciteitsbeperking te behouden.
db.candidates.createIndex({naam: 1 },{uniek:waar})Hier passen we de unieke indexcriteria toe voor het veld dat vergelijkbare waarden bevat. Binnen de createIndex() -methode noemen we het veld 'naam' met de waarde '1' om er een unieke index van te maken en de unieke optie te definiëren met de waarde 'true'. Omdat de twee documenten het veld ‘naam’ hebben met identieke waarden, kunnen we van dit veld geen unieke index van de ‘kandidaten’-collectie maken. De dubbele sleutelfout wordt geactiveerd bij het uitvoeren van de query.
Zoals verwacht genereert de uitvoer de resultaten omdat het naamveld dezelfde waarden heeft voor twee verschillende documenten:

We werken dus de verzameling ‘kandidaten’ bij door een unieke waarde te geven aan elk ‘naam’-veld in het document en maken vervolgens het veld ‘naam’ als de unieke index. Als u die query uitvoert, wordt doorgaans het veld 'naam' aangemaakt als de unieke index, zoals hieronder weergegeven:

Voorbeeld 5: Maak een unieke index van een ontbrekend veld
Als alternatief passen we de methode createIndex() toe op het veld dat in geen van de documenten van de collectie voorkomt. Als gevolg hiervan slaat de index een nulwaarde op voor dat veld en mislukt de bewerking vanwege een overtreding van de waarde van het veld.
db.candidates.createIndex({ e-mail: 1 }, { uniek: waar } )Hier gebruiken we de methode createIndex() waarbij het veld “e-mail” de waarde “1” krijgt. Het veld “e-mail” bestaat niet in de verzameling “kandidaten” en we proberen er een unieke index van te maken voor de verzameling “kandidaten” door de unieke optie in te stellen op “true”.
Wanneer de query hiervoor wordt uitgevoerd, krijgen we de foutmelding in de uitvoer omdat het veld “e-mail” ontbreekt in de verzameling “kandidaten”:

Voorbeeld 6: Maak een unieke index van een veld met een beperkte optie
Vervolgens kan de unieke index ook worden aangemaakt met de sparse optie. De functionaliteit van een sparse index is dat deze alleen documenten bevat die het geïndexeerde veld hebben, met uitzondering van de documenten die het geïndexeerde veld niet hebben. We hebben de volgende structuur geboden om de sparse-optie in te stellen:
db.candidates.createIndex( { cursus : 1 },{ naam: 'unieke_sparse_cursus_index' , uniek: waar, schaars: waar } )
Hier bieden we de methode createIndex() waarbij het veld “cursus” is ingesteld op de waarde “1”. Daarna specificeren we de extra optie om een uniek indexveld in te stellen, namelijk “cursus”. De opties omvatten de 'naam' die de index 'unique_sparse_course_index' instelt. Dan hebben we de “unieke” optie die is gespecificeerd met de “true” waarde en de “sparse” optie is ook ingesteld op “true”.
De uitvoer creëert een unieke en beperkte index in het veld “cursus”, zoals hieronder weergegeven:

Voorbeeld 7: Toon de gemaakte unieke index met behulp van de GetIndexes()-methode
In het vorige voorbeeld werd alleen een unieke index gemaakt voor de opgegeven collectie. Om de informatie over de unieke indexen voor de “kandidaten”-collectie te bekijken en te verkrijgen, gebruiken we de volgende getIndexes() -methode:
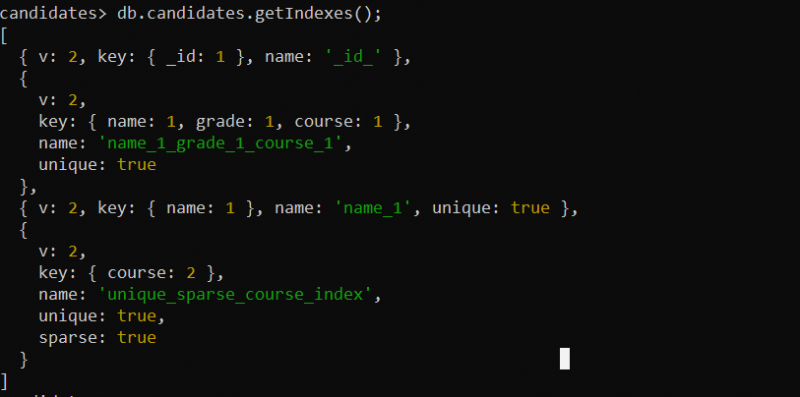
db.candidates.getIndexes();Hier roepen we de functie getIndexes() aan voor de verzameling 'kandidaten'. De functie getIndexes() retourneert alle indexvelden voor de verzameling “kandidaten” die we in de vorige voorbeelden hebben gemaakt.
In de uitvoer wordt de unieke index weergegeven die we voor de verzameling hebben gemaakt: een unieke index, een samengestelde index of de unieke sparse index:
Conclusie
We hebben geprobeerd een unieke index te maken voor de specifieke velden van de collectie. We hebben de verschillende manieren onderzocht om een unieke index te maken voor een enkel veld en meerdere velden. We hebben ook geprobeerd een unieke index te maken waarbij de bewerking mislukt vanwege een schending van de unieke beperking.