Kunstmatige intelligentie is een van de snelst groeiende technologieën die machine learning-algoritmen gebruiken om modellen te trainen en te testen met behulp van enorme hoeveelheden data. De gegevens kunnen in verschillende formaten worden opgeslagen, maar om grote taalmodellen te maken met LangChain is JSON het meest gebruikte type. De trainings- en testgegevens moeten duidelijk en volledig zijn, zonder enige dubbelzinnigheid, zodat het model effectief kan presteren.
Deze handleiding demonstreert het proces van het gebruik van de pydantische JSON-parser in LangChain.
Hoe gebruik je Pydantic (JSON) Parser in LangChain?
De JSON-gegevens bevatten het tekstuele formaat van gegevens die kunnen worden verzameld via webscraping en vele andere bronnen zoals logs, enz. Om de nauwkeurigheid van de gegevens te valideren, gebruikt LangChain de pydantic-bibliotheek van Python om het proces te vereenvoudigen. Om de pydantic JSON-parser in LangChain te gebruiken, volgt u eenvoudigweg deze handleiding:
Stap 1: Modules installeren
Om met het proces aan de slag te gaan, installeert u eenvoudigweg de LangChain-module om de bibliotheken te gebruiken voor het gebruik van de parser in LangChain:
Pip installeren langketen
Gebruik nu de “ pip installeren 'opdracht om het OpenAI-framework te verkrijgen en de bronnen ervan te gebruiken:
Pip installeren openai
Na het installeren van de modules maakt u eenvoudig verbinding met de OpenAI-omgeving door de API-sleutel op te geven met behulp van de “ Jij ' En ' Krijg een pas ” bibliotheken:
importeer onsgetpass importeren
os.omgeving [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API-sleutel:' )

Stap 2: Bibliotheken importeren
Gebruik de LangChain-module om de benodigde bibliotheken te importeren die kunnen worden gebruikt voor het maken van een sjabloon voor de prompt. Het sjabloon voor de prompt beschrijft de methode voor het stellen van vragen in natuurlijke taal, zodat het model de prompt effectief kan begrijpen. Importeer ook bibliotheken zoals OpenAI en ChatOpenAI om ketens te creëren met behulp van LLM's voor het bouwen van een chatbot:
van langchain.prompts importeren (Promptsjabloon,
ChatPrompt-sjabloon,
HumanMessagePrompt-sjabloon,
)
van langchain.llms importeer OpenAI
van langchain.chat_models importeer ChatOpenAI
Importeer daarna pydantic-bibliotheken zoals BaseModel, Field en validator om JSON-parser in LangChain te gebruiken:
van langchain.output_parsers importeer PydanticOutputParservan pydantic import BaseModel, Veld, validator
door importlijst te typen
Stap 3: Een model bouwen
Nadat u alle bibliotheken voor het gebruik van de pydantic JSON-parser heeft verkregen, kunt u eenvoudigweg het vooraf ontworpen geteste model met de OpenAI()-methode verkrijgen:
modelnaam = 'tekst-davinci-003'temperatuur = 0,0
model = OpenAI ( modelnaam =model_naam, temperatuur =temperatuur )
Stap 4: Configureer Actor BaseModel
Bouw een ander model om antwoorden te krijgen met betrekking tot acteurs, zoals hun namen en films, door te vragen naar de filmografie van de acteur:
klasse acteur ( Basismodel ) :naam: str = Veld ( beschrijving = 'Naam van de hoofdrolspeler' )
film_names: Lijst [ str ] = Veld ( beschrijving = 'Films waarin de acteur de hoofdrol speelde' )
acteur_query = 'Ik wil de filmografie van elke acteur zien'
parser = PydanticOutputParser ( pydantisch_object =Acteur )
prompt = Promptsjabloon (
sjabloon = 'Beantwoord de vraag van de gebruiker. \N {format_instructions} \N {vraag} \N ' ,
invoervariabelen = [ 'vraag' ] ,
gedeeltelijke_variabelen = { 'format_instructions' : parser.get_format_instructions ( ) } ,
)
Stap 5: Het basismodel testen
Haal eenvoudigweg de uitvoer op met behulp van de functie parse() met de uitvoervariabele die de resultaten bevat die voor de prompt zijn gegenereerd:
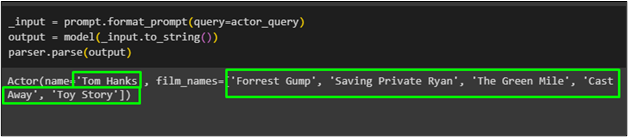
_input = prompt.format_prompt ( vraag =actor_query )uitvoer = model ( _invoer.naar_string ( ) )
parser.parse ( uitgang )
De acteur genaamd “ Tom Hanks ” met de lijst van zijn films is opgehaald met behulp van de pydantische functie uit het model:
Dat gaat allemaal over het gebruik van de pydantische JSON-parser in LangChain.
Conclusie
Om de pydantic JSON-parser in LangChain te gebruiken, installeert u eenvoudigweg LangChain- en OpenAI-modules om verbinding te maken met hun bronnen en bibliotheken. Importeer daarna bibliotheken zoals OpenAI en pydantic om een basismodel te bouwen en de gegevens in de vorm van JSON te verifiëren. Nadat u het basismodel hebt gebouwd, voert u de functie parse() uit, waarna de antwoorden voor de prompt worden geretourneerd. Dit bericht demonstreerde het proces van het gebruik van pydantic JSON-parser in LangChain.