Panda's vullen NaN-waarden
Als een kolom in uw gegevensframe NaN- of Geen-waarden heeft, kunt u de functies 'fillna()' of 'replace()' gebruiken om ze met nul (0) te vullen.
vullen()
De NA/NaN-waarden worden gevuld met de verstrekte benadering met behulp van de functie 'fillna()'. Het kan worden gebruikt door rekening te houden met de volgende syntaxis:
Als u de NaN-waarden voor een enkele kolom wilt vullen, is de syntaxis als volgt:

Wanneer u de NaN-waarden voor het volledige DataFrame moet invullen, is de syntaxis als volgt:

Vervangen()
Om een enkele kolom met NaN-waarden te vervangen, is de geboden syntaxis als volgt:

Terwijl we, om de NaN-waarden van het hele DataFrame te vervangen, de volgende genoemde syntaxis moeten gebruiken:

In dit stuk zullen we nu de praktische implementatie van beide methoden onderzoeken en leren om de NaN-waarden in ons Pandas DataFrame te vullen.
Voorbeeld 1: Vul NaN-waarden in met behulp van de 'Fillna()'-methode van Panda
Deze illustratie toont de toepassing van Panda's 'DataFrame.fillna()'-functie om de NaN-waarden in het gegeven DataFrame met 0 te vullen. U kunt de ontbrekende waarden in een enkele kolom vullen of u kunt ze voor het hele DataFrame vullen. Hier zullen we beide technieken zien.
Om deze strategieën in praktijk te brengen, moeten we een geschikt platform krijgen voor de uitvoering van het programma. Dus hebben we besloten om de tool 'Spyder' te gebruiken. We begonnen onze Python-code door de 'panda's'-toolkit in het programma te importeren, omdat we de functie Panda's moeten gebruiken om het DataFrame te construeren en om de ontbrekende waarden in dat DataFrame te vullen. De 'pd' wordt in het hele programma gebruikt als de alias van 'panda's'.
Nu hebben we toegang tot Pandas-functies. We gebruiken eerst de functie 'pd.DataFrame()' om ons DataFrame te genereren. We hebben deze methode aangeroepen en geïnitialiseerd met drie kolommen. De titels van deze kolommen zijn 'M1', 'M2' en 'M3'. De waarden in de kolom 'M1' zijn '1', 'Geen', '5', '9' en '3'. De vermeldingen in 'M2' zijn 'Geen', '3', '8', '4' en '6'. Terwijl de 'M3' de gegevens opslaat als '1', '2', '3', '5' en 'Geen'. We hebben een DataFrame-object nodig waarin we dit DataFrame kunnen opslaan wanneer de methode 'pd.DataFrame()' wordt aangeroepen. We hebben een 'ontbrekend' DataFrame-object gemaakt en het toegewezen op basis van de uitkomst die we hebben gekregen van de functie 'pd.DataFrame()'. Vervolgens hebben we de Python-methode 'print()' gebruikt om het DataFrame op de Python-console weer te geven.
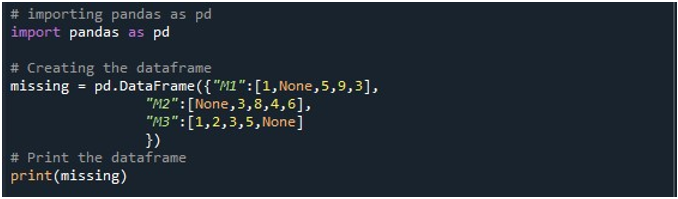
Wanneer we dit stuk code uitvoeren, kan een DataFrame met drie kolommen op de terminal worden bekeken. Hier kunnen we zien dat alle drie de kolommen de null-waarden bevatten.
We hebben een DataFrame gemaakt met enkele null-waarden om de functie Pandas 'fillna()' toe te passen om de ontbrekende waarden met 0 te vullen. Laten we eens kijken hoe we dat kunnen doen.
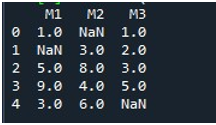
Na het weergeven van het DataFrame, hebben we de functie Pandas 'fillna()' aangeroepen. Hier zullen we leren om de ontbrekende waarden in een enkele kolom in te vullen. De syntaxis hiervoor wordt al genoemd aan het begin van de tutorial. We hebben de naam van het DataFrame opgegeven en de specifieke kolomtitel gespecificeerd met de functie '.fillna()'. Tussen de haakjes van deze methode hebben we de waarde opgegeven die op de lege plaatsen wordt geplaatst. De DataFrame-naam is 'ontbrekend' en de kolom die we hier hebben gekozen is 'M2'. De waarde tussen de accolades van de “fillna()” is “0”. Ten slotte hebben we de functie 'print()' aangeroepen om het bijgewerkte DataFrame te bekijken.

Hier kunt u zien dat de kolom 'M2' van het DataFrame nu geen ontbrekende waarden bevat omdat de NaN-waarde is gevuld met 0.
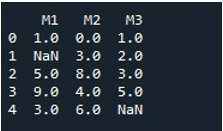
Om de NaN-waarden voor een heel DataFrame met dezelfde methode te vullen, hebben we de 'fillna()' genoemd. Dit is vrij eenvoudig. We hebben de DataFrame-naam voorzien van de functie 'fillna()' en de functiewaarde '0' tussen haakjes toegewezen. Ten slotte liet de functie 'print()' ons het gevulde DataFrame zien.

Dit levert ons een DataFrame op zonder NaN-waarden, omdat alle waarden nu worden aangevuld met 0.
Voorbeeld 2: Vul NaN-waarden in met behulp van de Panda's 'Replace()'-methode
Dit deel van het artikel demonstreert een andere methode om de NaN-waarden in een DataFrame te vullen. We zullen de functie 'replace()' van Panda's gebruiken om de waarden in een enkele kolom en in een volledig DataFrame te vullen.
We beginnen met het schrijven van de code in de tool 'Spyder'. Eerst hebben we de vereiste bibliotheken geïmporteerd. Hier hebben we de Pandas-bibliotheek geladen om het Python-programma in staat te stellen de Pandas-methoden te gebruiken. De tweede bibliotheek die we hebben geladen, is NumPy en alias deze naar 'np'. NumPy verwerkt de ontbrekende gegevens met de methode 'replace()'.
Vervolgens hebben we een DataFrame gegenereerd met drie kolommen: 'schroef', 'spijker' en 'boor'. De waarden in elke kolom worden respectievelijk gegeven. De kolom 'schroef' heeft de waarden '112', '234', 'Geen' en '650'. De kolom 'nagel' heeft '123', '145', 'Geen' en '711'. Ten slotte heeft de kolom 'drill' de waarden '312', 'Geen', '500' en 'Geen'. Het DataFrame wordt opgeslagen in het 'tool' DataFrame-object en weergegeven met behulp van de 'print()'-methode.
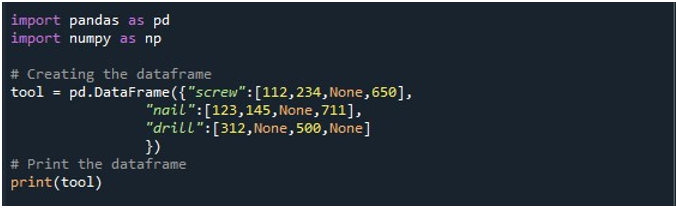
Een DataFrame met vier NaN-waarden in het record is te zien in de volgende uitvoerafbeelding:
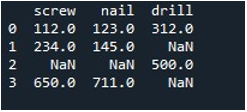
Nu gebruiken we de Panda's 'replace()' -methode om de null-waarden in een enkele kolom van het DataFrame te vullen. Voor de taak hebben we de functie 'replace()' aangeroepen. We hebben de DataFrame-naam 'tool' en kolom 'schroef' geleverd met de '.replace()'-methode. Tussen de accolades stellen we de waarde '0' in voor de 'np.nan' -vermeldingen in het DataFrame. De methode 'print()' wordt gebruikt om de uitvoer weer te geven.

Het resulterende DataFrame toont ons de eerste kolom waarin NaN-vermeldingen worden vervangen door 0 in de kolom 'schroef'.
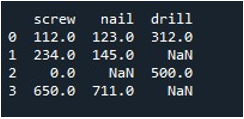
Nu zullen we leren de waarden in het hele DataFrame in te vullen. We noemden de methode 'replace()' met de naam van het DataFrame en gaven de waarde die we willen vervangen door np.nan-items. Ten slotte hebben we het bijgewerkte DataFrame afgedrukt met de functie 'print()'.

Dit levert ons het resulterende DataFrame op zonder ontbrekende records.
Conclusie
Omgaan met de ontbrekende vermeldingen in een DataFrame is een fundamentele en noodzakelijke vereiste om de complexiteit te verminderen en de gegevens uitdagend te behandelen in het gegevensanalyseproces. Pandas biedt ons een paar opties om met dit probleem om te gaan. In deze gids hebben we twee handige strategieën ingebracht. We hebben beide technieken in de praktijk gebracht met behulp van de 'Spyder'-tool om de voorbeeldcodes uit te voeren om het u een beetje begrijpelijk en gemakkelijker te maken. Door kennis van deze functies op te doen, worden je Panda's-vaardigheden aangescherpt.