Deze gids illustreert het proces van het gebruik van de gesprekskennisgrafiek in LangChain.
Hoe gebruik je de Conversatiekennisgrafiek in LangChain?
De GesprekKGGeheugen bibliotheek kan worden gebruikt om het geheugen opnieuw te creëren dat kan worden gebruikt om de context van de interactie te achterhalen. Om het proces van het gebruik van de gesprekskennisgrafiek in LangChain te leren, doorloopt u eenvoudigweg de vermelde stappen:
Stap 1: Modules installeren
Ga eerst aan de slag met het gebruik van de gesprekskennisgrafiek door de LangChain-module te installeren:
pip installeer langchain
Installeer de OpenAI-module die kan worden geïnstalleerd met behulp van de pip-opdracht om de bibliotheken te verkrijgen voor het bouwen van grote taalmodellen:
pip installeer openai
Nu, de omgeving opzetten met behulp van de OpenAI API-sleutel die vanuit zijn account kan worden gegenereerd:
importeren Jij
importeren Krijg een pas
Jij . ongeveer [ 'OPENAI_API_KEY' ] = Krijg een pas . Krijg een pas ( 'OpenAI API-sleutel:' )
Stap 2: Geheugen gebruiken met LLM's
Zodra de modules zijn geïnstalleerd, kunt u het geheugen met LLM gaan gebruiken door de vereiste bibliotheken uit de LangChain-module te importeren:
van langketen. geheugen importeren GesprekKGGeheugenvan langketen. llms importeren OpenAI
Bouw de LLM met behulp van de OpenAI()-methode en configureer het geheugen met behulp van de GesprekKGGeheugen () methode. Sla daarna de promptsjablonen op met behulp van meerdere invoer met hun respectievelijke reactie om het model op deze gegevens te trainen:
llm = OpenAI ( temperatuur = 0 )geheugen = GesprekKGGeheugen ( llm = llm )
geheugen. bewaar_context ( { 'invoer' : 'zeg hoi tegen john' } , { 'uitvoer' : 'Jan! Wie' } )
geheugen. bewaar_context ( { 'invoer' : 'hij is een vriend' } , { 'uitvoer' : 'Zeker' } )
Test het geheugen door het geheugenvariabelen () methode met behulp van de query met betrekking tot de bovenstaande gegevens:
geheugen. laad_geheugen_variabelen ( { 'invoer' : 'wie is johan' } ) 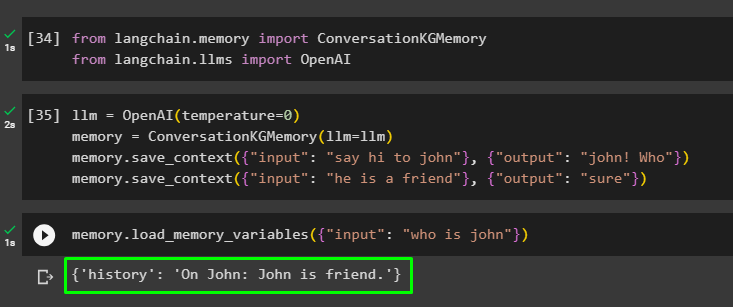
Configureer het geheugen met behulp van de ConversationKGMemory() -methode met de return_messages argument om ook de geschiedenis van de invoer te krijgen:
geheugen = GesprekKGGeheugen ( llm = llm , return_messages = WAAR )geheugen. bewaar_context ( { 'invoer' : 'zeg hoi tegen john' } , { 'uitvoer' : 'Jan! Wie' } )
geheugen. bewaar_context ( { 'invoer' : 'hij is een vriend' } , { 'uitvoer' : 'Zeker' } )
Test eenvoudigweg het geheugen door het invoerargument zijn waarde te geven in de vorm van een query:
geheugen. laad_geheugen_variabelen ( { 'invoer' : 'wie is johan' } ) 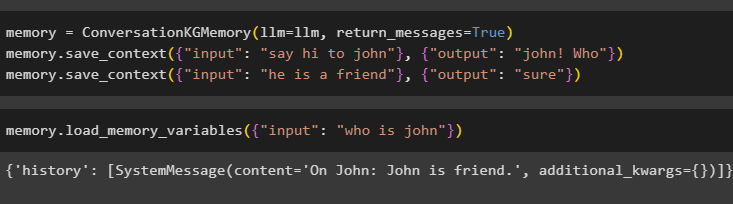
Test nu het geheugen door de vraag te stellen die niet in de trainingsgegevens wordt vermeld, en het model heeft geen idee van het antwoord:
geheugen. get_current_entities ( 'wat is de lievelingskleur van john' )Gebruik de get_knowledge_triplets () methode door te reageren op de eerder gestelde vraag:
geheugen. get_knowledge_triplets ( 'Zijn favoriete kleur is rood' ) 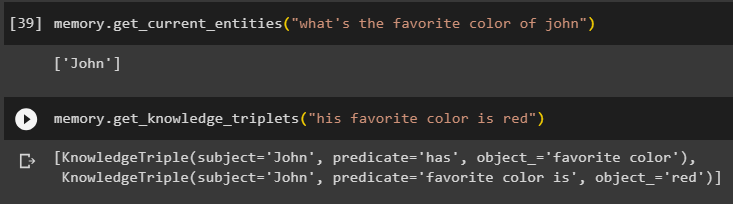
Stap 3: Geheugen in keten gebruiken
De volgende stap gebruikt het gespreksgeheugen met de ketens om het LLM-model te bouwen met behulp van de OpenAI()-methode. Configureer daarna de promptsjabloon met behulp van de gespreksstructuur en de tekst wordt weergegeven terwijl de uitvoer door het model wordt opgehaald:
llm = OpenAI ( temperatuur = 0 )van langketen. aanwijzingen . snel importeren Promptsjabloon
van langketen. kettingen importeren ConversatieKeten
sjabloon = '''Dit is het sjabloon voor de interactie tussen mens en machine
Het systeem is een AI-model dat over meerdere aspecten kan praten of informatie kan extraheren
Als hij de vraag niet begrijpt of het antwoord niet heeft, zegt hij dat gewoon
Het systeem extraheert gegevens die zijn opgeslagen in de sectie 'Specifiek' en hallucineert niet
Specifiek:
{geschiedenis}
Gesprek:
Mens: {invoer}
AI:'''
#Configureer de sjabloon of structuur voor het geven van aanwijzingen en het krijgen van reactie van het AI-systeem
snel = Promptsjabloon ( invoervariabelen = [ 'geschiedenis' , 'invoer' ] , sjabloon = sjabloon )
gesprek_met_kg = ConversatieKeten (
llm = llm , uitgebreid = WAAR , snel = snel , geheugen = GesprekKGGeheugen ( llm = llm )
)
Zodra het model is gemaakt, roept u eenvoudigweg de gesprek_met_kg model met behulp van de voorspellen() methode met de door de gebruiker gestelde vraag:
gesprek_met_kg. voorspellen ( invoer = 'Hoi, hoe is het?' ) 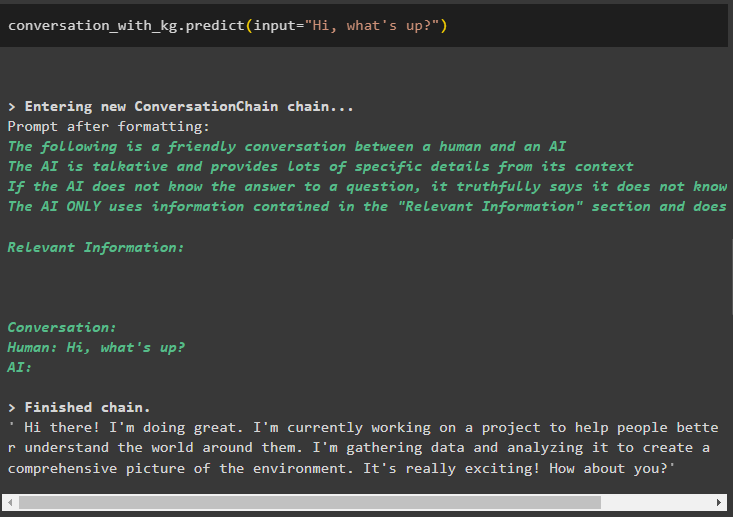
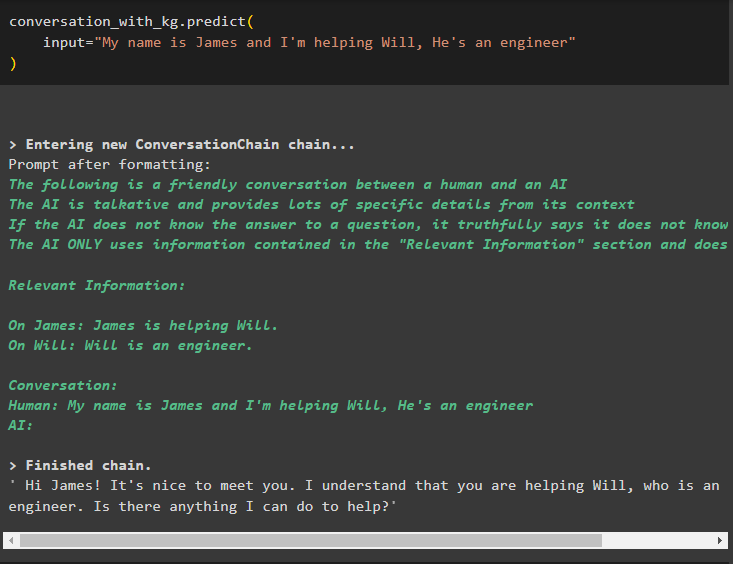
Train het model nu met behulp van het gespreksgeheugen door de informatie op te geven als invoerargument voor de methode:
gesprek_met_kg. voorspellen (invoer = 'Mijn naam is James en ik help Will, hij is een ingenieur'
)
Dit is het moment om het model te testen door de vragen te stellen om informatie uit de gegevens te extraheren:
gesprek_met_kg. voorspellen ( invoer = 'Wie is Wil' ) 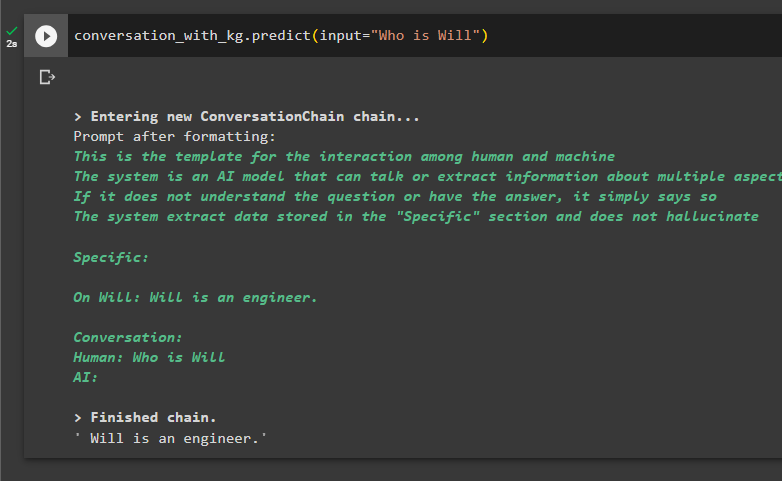
Dat gaat allemaal over het gebruik van de gesprekskennisgrafiek in LangChain.
Conclusie
Om de conversatiekennisgrafiek in LangChain te gebruiken, installeert u de modules of raamwerken om bibliotheken te importeren voor het gebruik van de ConversationKGMemory() -methode. Bouw daarna het model met behulp van het geheugen om de ketens te bouwen en informatie te extraheren uit de trainingsgegevens in de configuratie. In deze gids wordt dieper ingegaan op het proces van het gebruik van de gesprekskennisgrafiek in LangChain.