Dit bericht illustreert de methode voor het gebruik van de uitvoerparserfuncties en -klassen via het LangChain-framework.
Hoe gebruik ik de uitvoerparser via LangChain?
De uitvoerparsers zijn de uitvoer en klassen die kunnen helpen om de gestructureerde uitvoer uit het model te halen. Om het proces van het gebruik van de uitvoerparsers in LangChain te leren, doorloopt u eenvoudigweg de vermelde stappen:
Stap 1: Modules installeren
Start eerst het proces van het gebruik van de uitvoerparsers door de LangChain-module met zijn afhankelijkheden te installeren om het proces te doorlopen:
Pip installeren langketen
Installeer daarna de OpenAI-module om de bibliotheken zoals OpenAI en ChatOpenAI te gebruiken:
Pip installeren openai
Stel nu de omgeving voor de OpenAI met behulp van de API-sleutel van het OpenAI-account:
importeer ons
getpass importeren
os.omgeving [ 'OPENAI_API_KEY' ] = getpass.getpass ( 'OpenAI API-sleutel:' )
Stap 2: Bibliotheken importeren
De volgende stap is het importeren van bibliotheken uit LangChain om de uitvoerparsers in het raamwerk te gebruiken:
van langchain.prompts importeer HumanMessagePromptTemplate
van pydantisch importveld
van langchain.prompts importeer ChatPromptTemplate
van langchain.output_parsers importeer PydanticOutputParser
van pydantic import BaseModel
van pydantic importvalidator
van langchain.chat_models importeer ChatOpenAI
van langchain.llms importeer OpenAI
door importlijst te typen
Stap 3: Gegevensstructuur opbouwen
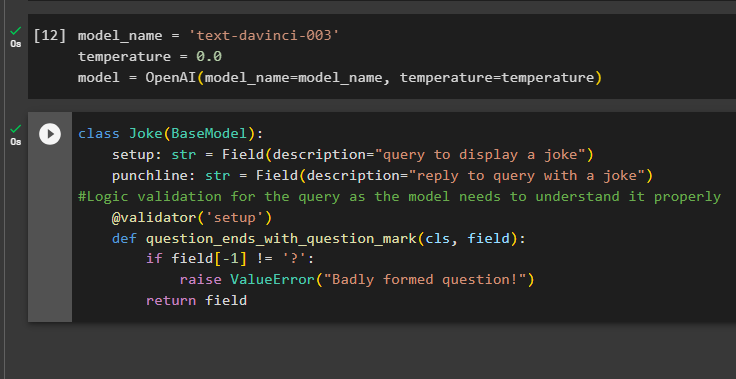
Het opbouwen van de structuur van de uitvoer is de essentiële toepassing van de uitvoerparsers in grote taalmodellen. Voordat we naar de datastructuur van de modellen gaan, is het nodig om de naam te definiëren van het model dat we gebruiken om de gestructureerde uitvoer van uitvoerparsers te verkrijgen:
temperatuur = 0,0
model = OpenAI ( modelnaam =model_naam, temperatuur =temperatuur )
Gebruik nu de klasse Joke die het BaseModel bevat om de structuur van de uitvoer te configureren om de grap uit het model te halen. Daarna kan de gebruiker eenvoudig aangepaste validatielogica toevoegen met de pydantic-klasse, die de gebruiker kan vragen een beter gevormde query/prompt te plaatsen:
klasse grap ( Basismodel ) :instelling: str = Veld ( beschrijving = 'query om een grap weer te geven' )
punchline: str = Veld ( beschrijving = 'antwoord op vraag met een grapje' )
#Logische validatie voor de query, aangezien het model deze goed moet begrijpen
@ validator ( 'opgericht' )
def vraag_eindigt_met_vraagteken ( cls, veld ) :
als veld [ - 1 ] ! = '?' :
Verhoog ValueError ( 'Slecht gevormde vraag!' )
opbrengst veld
Stap 4: Promptsjabloon instellen
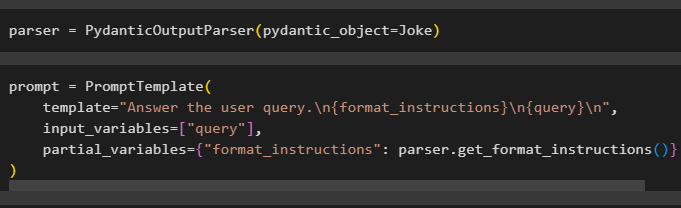
Configureer de parservariabele die de PydanticOutputParser()-methode bevat met de bijbehorende parameters:
Na het configureren van de parser definieert u eenvoudigweg de promptvariabele met behulp van de PromptTemplate() -methode met de structuur van de query/prompt:
prompt = Promptsjabloon (sjabloon = 'Beantwoord de vraag van de gebruiker. \N {format_instructions} \N {vraag} \N ' ,
invoervariabelen = [ 'vraag' ] ,
gedeeltelijke_variabelen = { 'format_instructions' : parser.get_format_instructions ( ) }
)
Stap 5: Test de uitvoerparser
Nadat u alle vereisten hebt geconfigureerd, maakt u een variabele die wordt toegewezen met behulp van een query en roept u vervolgens de methode format_prompt() aan:
_input = prompt.format_prompt ( vraag = grap_query )
Roep nu de functie model() aan om de uitvoervariabele te definiëren:
uitvoer = model ( _invoer.naar_string ( ) )Voltooi het testproces door de methode parser() aan te roepen met de uitvoervariabele als parameter:
parser.parse ( uitgang ) 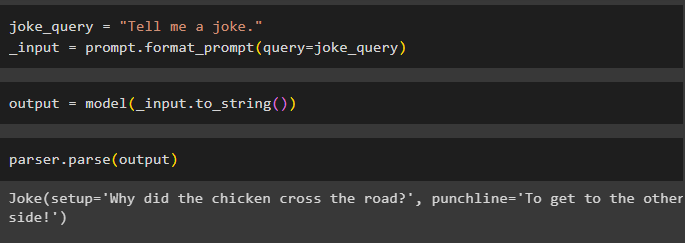
Dat gaat allemaal over het proces van het gebruik van de uitvoerparser in LangChain.
Conclusie
Om de uitvoerparser in LangChain te gebruiken, installeert u de modules en stelt u de OpenAI-omgeving in met behulp van de API-sleutel. Definieer daarna het model en configureer vervolgens de datastructuur van de uitvoer met logische validatie van de door de gebruiker verstrekte zoekopdracht. Zodra de gegevensstructuur is geconfigureerd, stelt u eenvoudigweg de promptsjabloon in en test u vervolgens de uitvoerparser om het resultaat van het model te verkrijgen. Deze handleiding illustreert het proces van het gebruik van de uitvoerparser in het LangChain-framework.