Deze tutorial gaat over het uploaden van de dataset op Hugging Face, maar laten we eerst het idee begrijpen van het uploaden van een dataset naar en de voor- en nadelen ervan.
Is het maken van een aangepaste dataset met knuffelgezichten een goed of een slecht idee?
De bibliotheek met datasets op Hugging Face is aanwezig om gebruikers te helpen tijd te besparen, omdat ze hun gegevens niet hoeven op te schonen om modellen uit te voeren. Aangepaste datasets zijn echter altijd een beter idee om de beste resultaten te genereren. Hier bekijken we de voor- en nadelen van het maken van datasets op basis van persoonlijke gegevens.
Voordelen
- Het belangrijkste voordeel van het uitvoeren van uw Machine Learning-modellen op aangepaste datasets is de betrouwbaarheid van de resultaten.
- Het gebruik van persoonsgegevens om ML-modellen te trainen zorgt ervoor dat de gebruiker zich scherp bewust is van het trainen van zijn of haar model en precies weet hoe het werkt.
- Door AI-modellen uit te voeren op een persoonlijke gegevensset, kunt u conclusies trekken uit de gegevens om weloverwogen beslissingen te nemen.
Nadelen
- Het kost veel tijd en moeite om uw dataset samen te stellen en klaar te maken voor toepassing van AI-modellen.
- De aangepaste datasets moeten worden opgeschoond om de gegevens toegankelijk te maken.
- De beschikbaarheid van alle soorten datasets in de Hugging Face-bibliotheek maakt deze taak gewoon overbodig.
- Bovendien bevatten de eerder beschikbare datasets veel grotere datavolumes. Aangepaste datasets kunnen niet concurreren met de hoeveelheid gegevens van Hugging Face-datasets.
Gegevensset uploaden op knuffelend gezicht - stapsgewijze methode
Stap 1: Log eerst in op uw account:
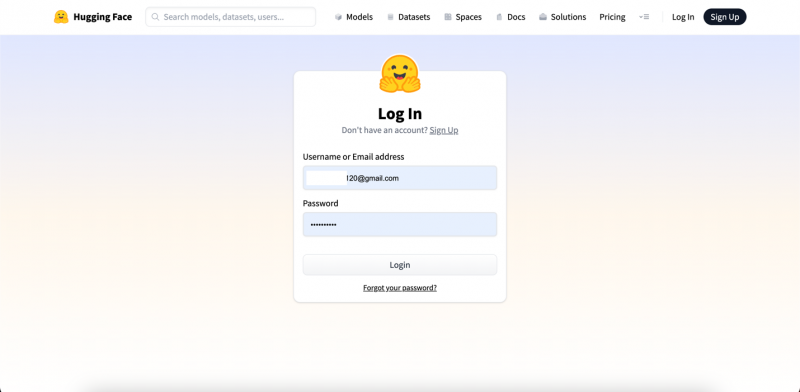
Stap 2: Klik op het profielpictogram:
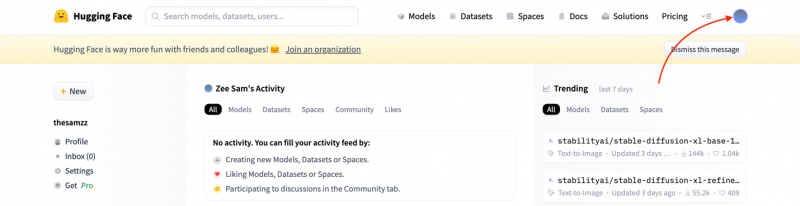
Er verschijnt een vervolgkeuzemenu, klik op a Nieuwe dataset :
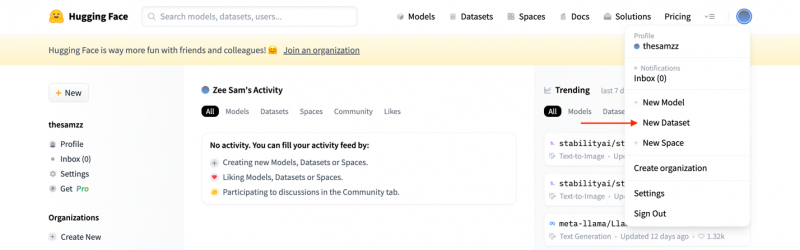
Stap 3: Daarna verschijnt een nieuwe reeks opties waar u de details van de dataset moet invoeren, zoals naam, licentie:
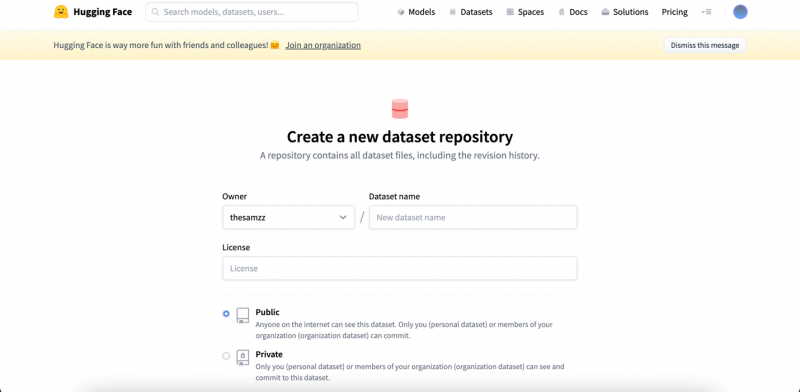
Stap 4: Klik op Gegevensset maken voor verdere actie:
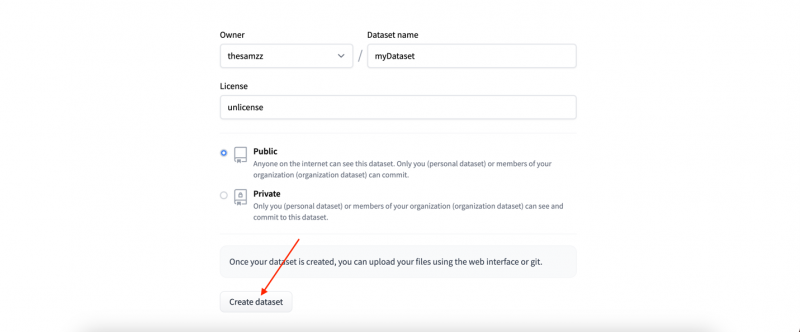
Stap 5: Nu in de Bestanden en versies tab klik op de knop bestand toevoegen om de dataset te uploaden:
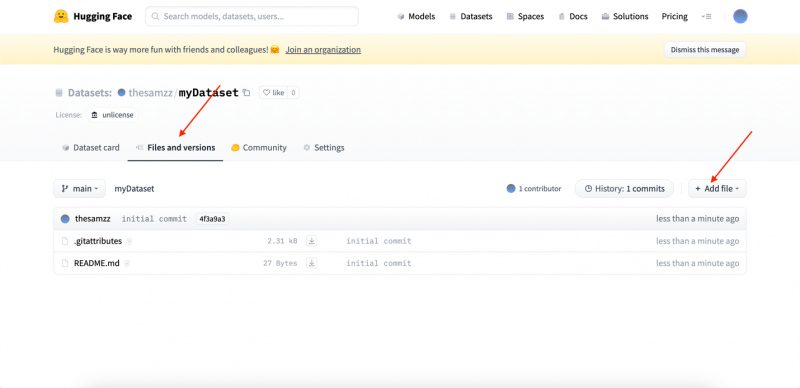
Er verschijnt een vervolgkeuzelijst wanneer u op Bestand toevoegen klikt en vervolgens op klikt Upload bestanden :
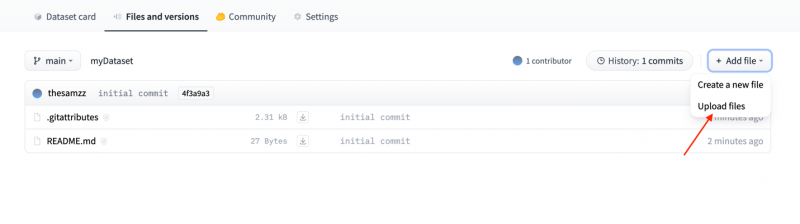
Stap 6: Sleep nu de dataset in het venster:
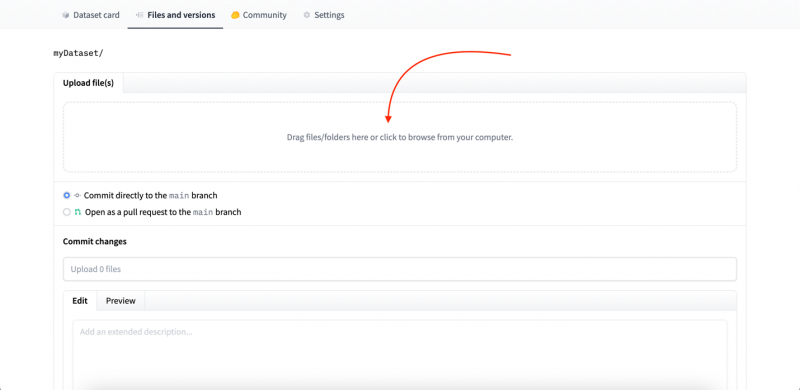
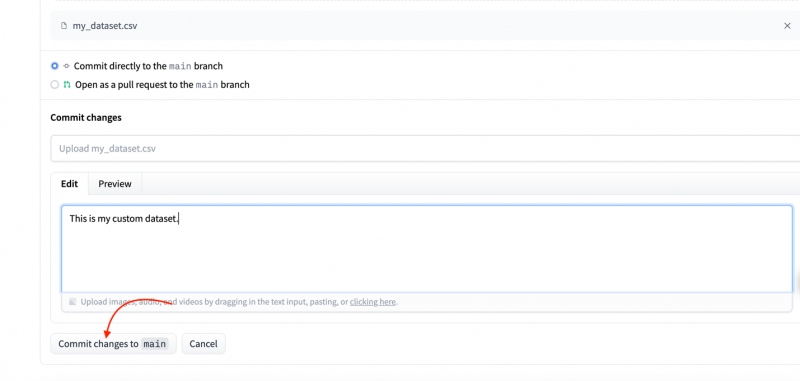
Stap 7: Voer de beschrijving in en klik vervolgens op de wijzigingen doorvoeren :
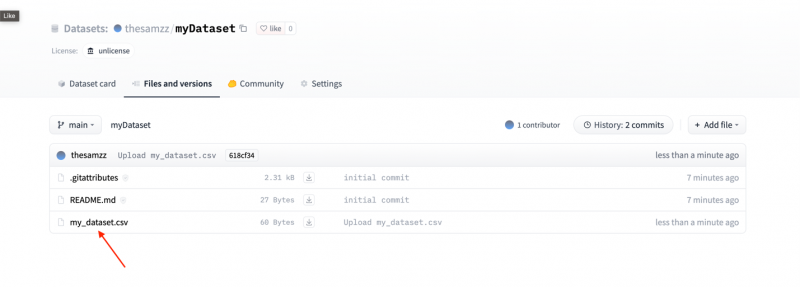
De dataset is geüpload:
Conclusie
Hugging Face-datasets bieden veel flexibiliteit, maar het gebruik van uw gegevens is erg belangrijk als het gaat om het testen van real-life algoritmen voor bedrijven of andere ondernemingen. Met Hugging Face kun je een persoonlijke dataset maken en deze uploaden naar hun bibliotheek voor het trainen en testen van verschillende Machine Learning-modellen. Bijgevolg kunt u real-time conclusies trekken uit uw gegevens en de informatie gebruiken om belangrijke beslissingen te beïnvloeden.