Gegevens worden dagelijks in grote aantallen verzameld en het beheer van big data is de belangrijkste use-case van de Elasticsearch-engine. De gegevens worden in realtime opgeslagen in de analysedatabase en de gebruiker kan gegevens extraheren om er nuttige kennis uit te halen met behulp van query's. De gebruiker kan query's toepassen om gegevens uit meerdere indexen te vinden en deze in een enkele bucket uit de relationele database weergeven.
Deze gids legt de Elasticsearch-aggregaties uit met voorbeelden van verschillende aggregaties.
Wat is Elasticsearch-aggregatie?
In Elasticsearch is aggregatie het proces van het combineren of groeperen van de velden om informatie uit de relationele database te extraheren. De aggregatie in Elasticsearch kan worden beschouwd als de GROEP PER CLAUSULE of TOTAAL() functie in de SQL-taal.
Hoe Elasticsearch-aggregatie te gebruiken?
Om de aggregatie in Elasticsearch te gebruiken, moet de gebruiker een basiskennis hebben van zijn database. Laten we de syntaxis en de praktische implementatie ervan verkennen:
Syntaxis
Om gegevens uit de database te vinden, de syntaxis van de aggregatie in de Elasticsearch-engine zoals hieronder:
'aggs' : {'naam_van_aggregatie' : {
'type_van_aggregatie' : {
'veld' : 'document_veld_naam'
}
Bovenstaande fragmenten:
-
- Het gebruikt de ' aggs ” sleutelwoord dat het gebruik van aggregatie in de zoekopdracht verklaart.
- De naam_van_aggregatie wordt ingesteld door de gebruiker volgens de vereiste informatie.
- Daarna de type_van_aggregatie wordt gebruikt om gegevens op te halen.
- De laatste regel gebruikt de veld trefwoord dat wordt gevolgd door de naam van het attribuut uit het document.
Voorbeeld 1: Aggregatie in Kibana-voorbeeldgegevens
In dit gedeelte wordt de aggregatie uitgelegd aan de hand van een voorbeeld waarbij de voorbeeldgegevens van Kibana worden gebruikt door er eerst verbinding mee te maken. Ga daarna gewoon naar de ' Ontwikkeltools ” door ernaar te zoeken vanuit de zoekbalk en erop te klikken:
Gegevens ophalen uit voorbeeldgegevens
Gebruik gewoon de volgende opdracht om de gegevens op te halen van de ' kibana_sample_data_logs ”index op de Dev Tools-console:
KRIJGEN / kibana_sample_data_logs / _zoekopdracht
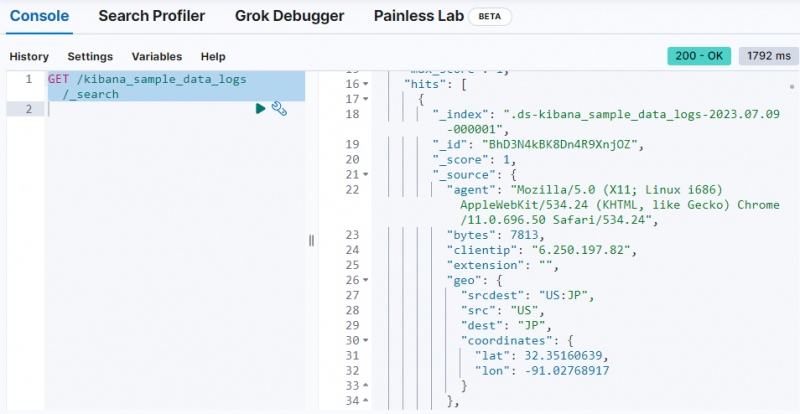
De uitvoer laat zien dat gegevens zijn opgehaald uit de ' kibana_sample_data_logs ' inhoudsopgave.
De volgende code gebruikt een KRIJGEN aanvraag op de “ kibana_sample_data_log ” om er vanuit te zoeken met behulp van de value_count-aggregatie op de cliënteel ' veld:
KRIJGEN / kibana_sample_data_logs / _zoekopdracht{ 'maat' : 0 ,
'aggs' : {
'ip_count' : {
'value_count' : {
'veld' : 'klantip'
}
}
}
}
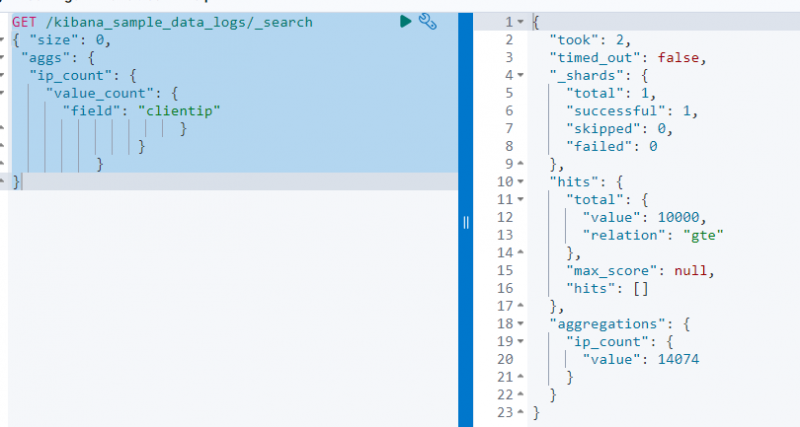
De bovenstaande schermafbeelding toont de aggregatie op de cliënteel veld met de waarde 14074 .
Belangrijke aggregaties
Enkele van de belangrijke aggregaties die worden gebruikt om efficiënt gegevens uit de database te vinden, worden hieronder vermeld:
In de volgende voorbeelden worden de bovengenoemde aggregaties uitgelegd met behulp van de KRIJGEN verzoek van de “ kibana_sample_data_ecommerce ' inhoudsopgave:
Kardinaliteit Aggregatie
De volgende code gebruikt de ' kardinaliteit ” aggregatie op de “ sku ”-veld uit de e-commercegegevens. Als u deze code uitvoert, krijgt u aggregatie met één waarde om de unieke SKU's uit de Elasticsearch-database te krijgen:
KRIJGEN / kibana_sample_data_ecommerce / _zoekopdracht{
'maat' : 0 ,
'aggs' : {
'unieke_skus' : {
'kardinaliteit' : {
'veld' : 'sku'
}
}
}
}
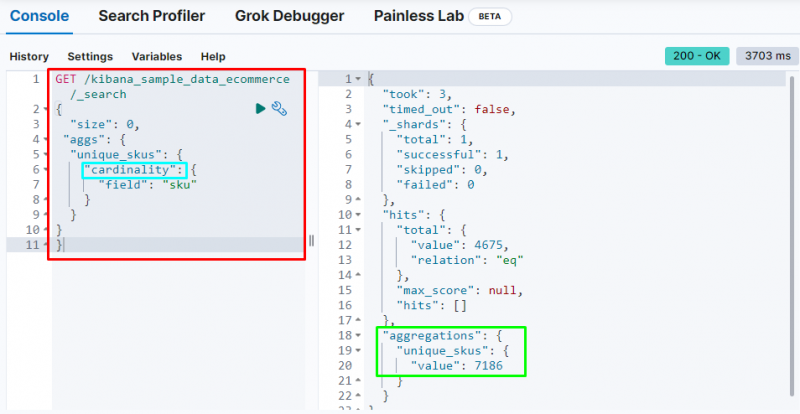
Het toont de kardinaliteit aggregatie vinden van de 7186 waarden uit de index.
Statistieken Aggregatie
Een andere belangrijke aggregatie is de “ statistieken ” aggregatie die wordt gebruikt om de “ graaf ”, “ min ”, “ max ”, “ gem ', En ' som ”statistieken van de “ totale kwantiteit ' veld:
KRIJGEN / kibana_sample_data_ecommerce / _zoekopdracht{
'maat' : 0 ,
'aggs' : {
'hoeveelheid_statistieken' : {
'statistieken' : {
'veld' : 'totale kwantiteit'
}
}
}
}
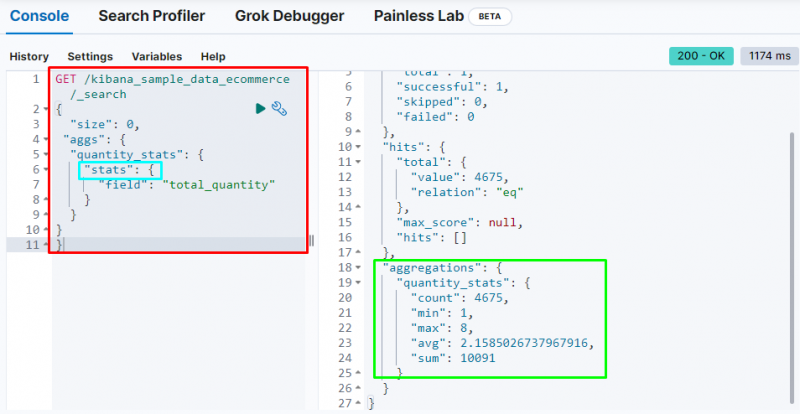
De bovenstaande schermafbeelding toont de statistieken in de uitvoer van de ' totale kwantiteit ' veld.
Aggregatie filteren
Filteraggregatie wordt gebruikt om gegevens uit te filteren op basis van een term of zin uit de database, aangezien de volgende code deze bevat:
KRIJGEN / kibana_sample_data_ecommerce / _zoekopdracht{ 'maat' : 0 ,
'aggs' : {
'filter_aggregatie' : {
'filter' : {
'termijn' : {
'gebruiker' : 'eddie' } } ,
'aggs' : {
'prijs_gem' : {
'gemiddeld' : {
'veld' : 'producten.prijs' } }
} } } }
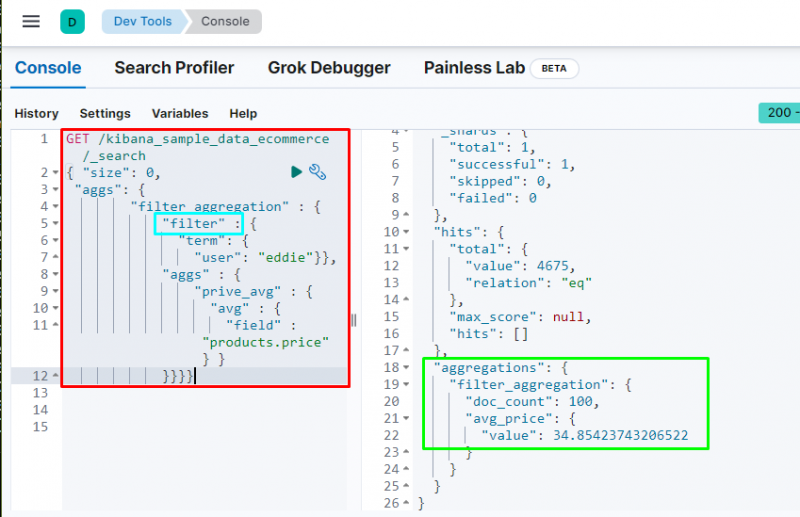
Uitvoering van code zal de gegevens filteren op basis van de ' eddie ” gebruiker en toont de gemiddelde prijs van de gekochte artikelen. De bovenstaande schermafbeelding laat zien dat de gebruiker heeft gevonden 100 keer uit de gegevens en de waarde van de gem _ prijs aggregatie.
Termijnaggregatie
De term aggregatie maakt een bucket en slaat gegevens uit het veld op in de bucket en de volgende code gebruikt de ' gebruiker ”-veld om de gegevens in de bucket op te slaan:
KRIJGEN / kibana_sample_data_ecommerce / _zoekopdracht{
'maat' : 0 ,
'aggs' : {
'Term_Aggregatie' : {
'voorwaarden' : {
'veld' : 'gebruiker'
}
}
}
}
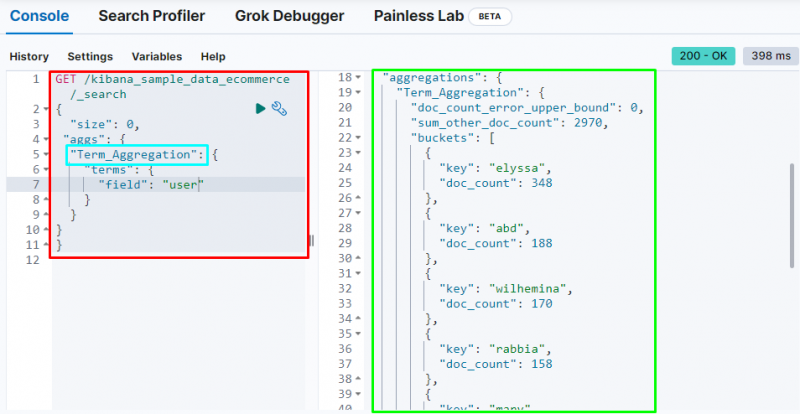
De volgende schermafbeelding laat zien dat de term aggregatie buckets heeft gemaakt voor elke gebruiker en hun aantal documenten.
Dat is alles over Elasticsearch-aggregatie en andere belangrijke aggregatie.
Conclusie
In Elasticsearch wordt de aggregatie gebruikt om gegevens uit de geaggregeerde documenten te halen en deze documenten worden uit een specifiek veld geëxtraheerd. Er zijn enkele belangrijke aggregaties die worden gebruikt om bruikbare inzichten uit de indexen te halen die worden uitgelegd. Deze gids heeft Elasticsearch-aggregatie uitgelegd en het proces van het gebruik van Elasticsearch-aggregatie gedemonstreerd.