De methode 'Series.to_csv()' in Pandas voert het opgegeven serieobject uit in een door komma's gescheiden waarden (csv)-notatie. Deze functie haalt eenvoudig de waarden uit een reeks en wijzigt hun formaat door komma's toe te voegen voor de scheiding van index- en kolomwaarden.
Om deze functie te gebruiken, moeten we de volgende syntaxis gebruiken:

Dit artikel geeft je twee verschillende technieken om te leren hoe je deze methode in een python-programma kunt gebruiken.
Voorbeeld # 1: de methode Series.to_csv() gebruiken om een reeks met DatetimeIndex te converteren naar door komma's gescheiden waarden
Om een serie te wijzigen in een CSV-indeling, gebruiken we de functie 'Series.to_csv()'. Deze illustratie genereert een reeks met een DatetimeIndex en converteert deze vervolgens naar een door komma's gescheiden waardenformaat.
Om deze methode in werking te stellen, moeten we een tool hebben die python-programmering ondersteunt. Voor het samenstellen van de codes wordt gekozen voor de tool “Spyder”. Om het script erop te schrijven, hebben we eerst de geïnstalleerde tool in ons systeem gelanceerd. Het python-programma heeft een bibliotheek nodig om zijn methoden uit te oefenen om het vereiste resultaat te bereiken. De bibliotheek die we hier hebben geladen, is de 'Panda's'. In dezelfde coderegel wordt de alias van deze bibliotheek geïdentificeerd als 'pd'. Dus overal in het programma moeten we 'panda's' schrijven om toegang te krijgen tot een functie. We zouden in plaats daarvan 'pd' schrijven.
De eerste stap om met de code te beginnen, is het genereren van een Pandas-serie. We moeten 'pd' schrijven om de methode voor het maken van series van panda's te gebruiken. De functie 'pd.Series()' wordt aangeroepen om een reeks met de opgegeven waarden te construeren. De waarden die we voor de serie hebben gegeven zijn 'Istanbul', 'Izmir', 'Ankara', 'Ankara', 'Antalya', 'Konya' en 'Bursa'. Als u deze array van waarden een naam wilt geven, kunt u dit doen door de parameter 'name' te gebruiken. Hier hebben we deze reeks waarden 'Steden' genoemd, omdat deze de namen van 6 steden bevat. Om deze serie op te slaan is een serieobject “Turkije” aangemaakt.
Om een DatetimeIndex te maken, hebben we de methode 'pd.date_range()' aangeroepen. Tussen de haakjes van deze functie hebben we 4 argumenten doorgegeven, namelijk: 'start', 'freq', 'perioden' en 'tz'.
Het 'start' -argument neemt een datum en tijd in om te beginnen met het genereren van een datumbereik. Hier hebben we de startdatum en -tijd gespecificeerd als '2022-03-02 02:30'. De parameter 'freq' classificeert de frequentie voor het datumbereik. Dus hebben we het de waarde 'D' gegeven. Nu zal het een datumbereik maken op dagelijkse frequentie. Het argument 'periode' is ingesteld op '6', wat betekent dat het een datumbereik voor 6 dagen genereert. De laatste parameter is 'tz' die de tijdzone voor het gespecificeerde gebied specificeert. We hebben de tijdzone voor “Azië/Istanbul” gespecificeerd.
Om dit datumbereik op te slaan, hebben we een variabele 'Datetime' -variabele gemaakt. Om de DatetimeIndex in te stellen, hebben we de eigenschap 'Series.index' gebruikt. De naam van de reeks 'Turkije' wordt geleverd met de eigenschap '.index' en toegewezen aan het datum-tijdbereik dat is opgeslagen in de variabele 'Datetime'. De eigenschap 'index' neemt dus de waarden van de variabele 'Datetime' en maakt ze de indexlijst van de reeks 'Turkey'. Ten slotte hebben we, om de uitvoerreeksen te bekijken, de methode 'print()' gebruikt en de reeks 'Turkije' als invoer doorgegeven om de inhoud ervan weer te geven.
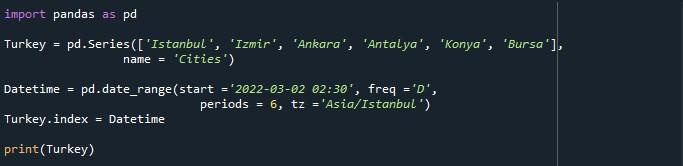
We hebben zojuist op de optie 'Bestand uitvoeren' gedrukt om het script uit te voeren. Bijgevolg kunnen we een reeks zien met de DatetimeIndex die begint vanaf '2022-03-02 02:30:00+03:00' en eindigt op '2022-03-07 02:30:00+03:00' en een periode creëert van 6 dagen. Onder de reeks staan ook de “Freq :D”, de naam van de arraylijst “Cities” en het dtype “object” vermeld.
Nu zullen we leren deze serie, die we zojuist in de bovenstaande snapshot hebben gezien, naar een CSV-indeling te converteren. Om de reeks te wijzigen in door komma's gescheiden waarden, hebben we een methode die wordt geleverd door de panda's-module, namelijk 'Series.to_csv()'. Deze methode neemt de waarden van de opgegeven reeks en voegt komma's toe tussen de waarden van de kolom.
De functie 'Series.to_csv()' wordt aangeroepen. De naam van de serie die we willen converteren wordt bij de methode vermeld als “Turkey.to_csv()”. Om de door komma's gescheiden waarden te behouden, hebben we een variabele 'Comma_Separated' gemaakt en vervolgens de inhoud ervan in het uitvoervenster geplaatst door de functie 'print()' aan te roepen.

Hier is onze serie in csv-formaat. We kunnen in de momentopname zien dat de index en de reekswaarden zijn gescheiden met behulp van de komma's erin.

Voorbeeld #2: de methode Series.to_csv() gebruiken om een reeks met NaN-waarden om te zetten in door komma's gescheiden waarden
De tweede techniek om de methode 'Series.to_csv()' uit te voeren, is om deze methode toe te passen om een reeks die enkele null-items bevat, om te zetten in een CSV-indeling.
We hebben in eerste instantie de benodigde pakketten geïmporteerd. De 'pd' is een alias voor panda's en 'np' als een alias voor numpy. De numpy-toolkit wordt hier geladen omdat we enkele null-items in onze serie zullen maken met behulp van 'np.NaN' terwijl we deze maken met behulp van de panda's 'pd.Series()' -methode.
De functie 'pd.Series()' wordt aangeroepen voor het bouwen van een reeks panda's met deze waarden: 'Nile', 'Amazon', np.NaN, 'Ganges', 'Mississippi', 'np.NaN', 'Yangtze', 'Donau', 'Mekong', 'np.NaN' en 'Volga'. Er zijn in totaal 21 waarden gedefinieerd voor de reeks, waarvan 3 vermeldingen 'np.NaN' -waarden bevatten, wat betekent dat er 3 waarden in de reeks ontbreken. De eigenschap 'name' specificeert de naam voor deze reeks waarden die we hebben opgegeven met 'Titles'. De eigenschap 'index' wordt gebruikt om de door de gebruiker gedefinieerde indexlijst in te stellen in plaats van met de standaardlijst te gaan.
Hier willen we de indexlijst met de waarden '10', '11', '12', '13', '14', '16', '17', '18', '19', '20', en 21'. Nu zal onze serie de indexlijst hebben die begint bij '10' in plaats van '0'. Sla deze serie nu op zodat we deze later in het programma kunnen gebruiken. We hebben een serieobject 'Rivers' geïnitialiseerd en de uitvoerreeks toegewezen die is gegenereerd door het aanroepen van de 'pd.Series()' -methode. De serie kan worden bekeken door deze te tonen met behulp van de functie 'print()' van python.
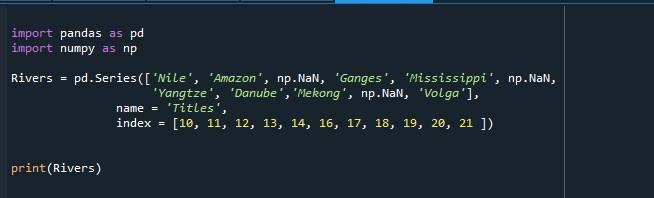
De weergegeven uitvoer op de terminal drukte een reeks af waarvan de indexlijst begint bij 10 en eindigt bij 21, wat betekent dat de reeks 21 waarden heeft.
De serie wordt omgezet in een CSV-indeling met de methode 'Series.to_csv()'.
We hebben de methode 'Series.to_csv()' aangeroepen met onze serie 'Turkey'. Daarom neemt deze methode de waarden uit de reeks 'Turkije' en converteert ze naar een door komma's gescheiden waardenformaat. Het resultaat wordt opgeslagen in de variabele 'Converted_csv'. En uiteindelijk wordt de geconverteerde serie afgedrukt met behulp van de functie “print()”.

In de momentopname van de uitkomst hieronder kunt u zien dat de waarden van de reeks nu zijn gewijzigd op een manier waarbij een komma wordt gebruikt om ze van de indexlijst te scheiden. Bovendien, waar de waarden ontbreken, wordt alleen het indexnummer met een komma afgedrukt.

Conclusie
Het aanpassen van een panda-serie naar een CSV-formaat is een praktische benadering. Dit kan worden bereikt door de panda's 'Series.to_csv()' -functie te gebruiken. Deze gids bracht twee technieken in de praktijk om deze methode toe te passen. In de eerste illustratie hebben we deze methode aangeroepen om een reeks met een DatetimeIndex om te zetten naar een door komma's gescheiden waardenformaat. De tweede instantie gebruikte de functie 'Series.to_csv()' om een reeks met enkele ontbrekende vermeldingen te wijzigen in een CSV-indeling. Beide technieken zijn praktisch geïmplementeerd met behulp van de 'Spyder' -tool op het Windows-besturingssysteem.