Er zijn veel meer methoden van de File Input Stream-klasse die ook erg handig zijn bij het ophalen van gegevens uit een bestand; sommige zijn int read(byte[] b), deze functie leest gegevens uit de invoerstroom tot een lengte van b.length bytes. Bestandskanaal krijgt het kanaal (): Het specifieke bestandskanaal-object dat is verbonden met de bestandsinvoerstroom, wordt ermee geretourneerd. Finalize() wordt gebruikt om ervoor te zorgen dat de functie close() wordt aangeroepen wanneer er niet langer wordt verwezen naar de bestandsinvoerstroom.”
Voorbeeld 01: lezen van een enkele byte uit een tekstbestand met behulp van de methoden read() en close() van de Input Stream Class
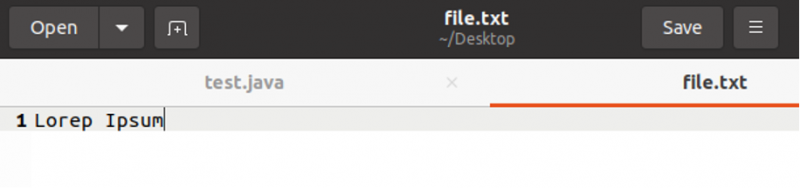
In dit voorbeeld wordt File Input Stream gebruikt om een enkel teken te lezen en de inhoud af te drukken. Stel dat we een bestand hebben met de naam 'file.txt' met de onderstaande inhoud:

Stel dat we een bestand hebben met de naam 'file.txt' met de hierboven getoonde inhoud. Laten we nu proberen het eerste teken van het bestand te lezen en af te drukken.
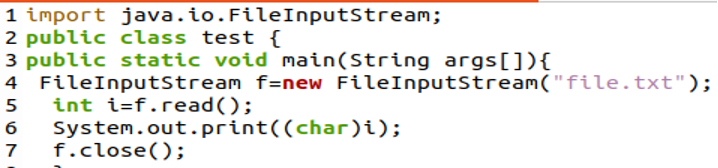
We moeten eerst java.io importeren. Bestandsinvoerstroompakket om een bestandsinvoerstroom te construeren. Vervolgens maken we een nieuw object van File Input Stream dat wordt gekoppeld aan het opgegeven bestand (file.txt) in variabele 'f'.
In dit voorbeeld gebruiken we de methode 'int read()' van de klasse Java File Input Stream, die wordt gebruikt om een enkele byte uit het bestand te lezen en op te slaan in de variabele 'I'. Vervolgens geeft de 'System.out.print(char(i))' het teken weer dat overeenkomt met die byte.
De methode f.close() sluit het bestand en de stream. We zullen de volgende uitvoer verkrijgen na het bouwen en uitvoeren van het bovengenoemde script, omdat we kunnen zien dat alleen de beginletter van de tekst 'L' wordt afgedrukt.

Voorbeeld 02: Alle inhoud van een tekstbestand lezen met behulp van de methoden read() en close() van de invoerstroomklasse
In dit voorbeeld zullen we alle inhoud van een tekstbestand lezen en weergeven; zoals hieronder weergegeven:
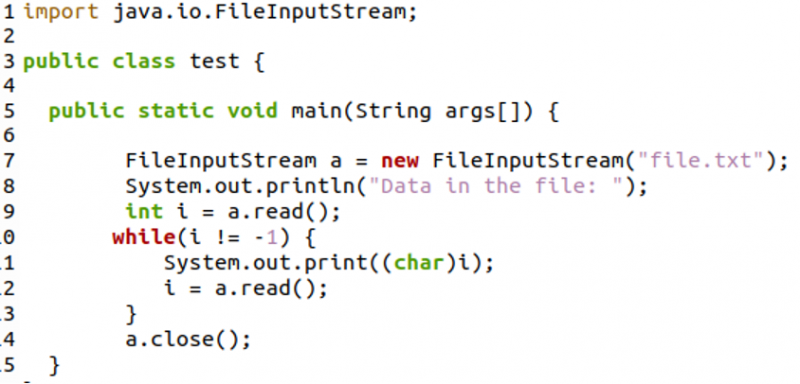
Nogmaals, we zullen java.io importeren. Bestandsinvoerstroompakket om een bestandsinvoerstroom te construeren.
Eerst zullen we de eerste byte van het bestand lezen en het bijbehorende teken in de while-lus weergeven. De while-lus wordt uitgevoerd totdat er geen bytes meer over zijn, dat wil zeggen het einde van de tekst in het bestand. Regel 12 leest de volgende byte en de lus gaat door tot de laatste byte van het bestand.
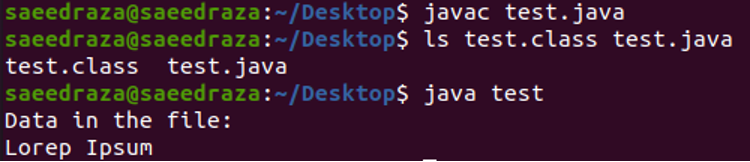
Na het compileren en uitvoeren van de bovenstaande code, krijgen we de volgende resultaten. Zoals we kunnen zien, wordt de hele tekst van het bestand 'Lorep Ipsum' weergegeven in de terminal.
Voorbeeld 03: Het aantal beschikbare bytes in een tekstbestand bepalen met behulp van de methode available() van de invoerstroomklasse
In dit voorbeeld gebruiken we de functie 'available()' van de bestandsinvoerstroom om het aantal bestaande bytes in de bestandsinvoerstroom te bepalen.
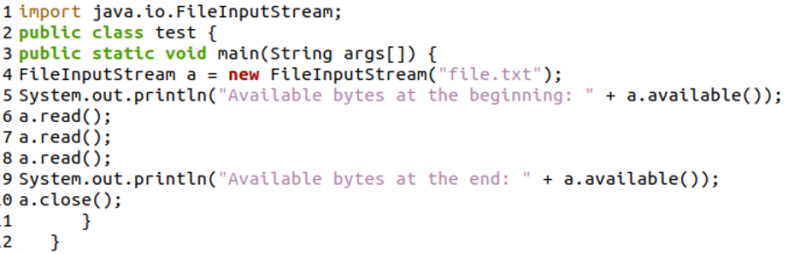
Eerst hebben we een object van de bestandsinvoerstroomklasse met de naam 'a' gegenereerd met de volgende code. In regel 5 hebben we de methode 'available()' gebruikt om het totale aantal beschikbare bytes in het bestand te bepalen en weer te geven. Vervolgens hebben we van regel 6 naar regel 8 de functie 'read()' driemaal gebruikt. Nu in regel 9 hebben we de methode 'available()' opnieuw gebruikt om de resterende bytes te controleren en weer te geven.
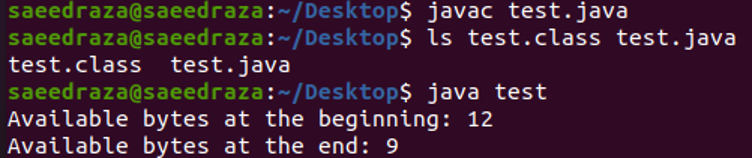
Na het compileren en uitvoeren van de code, kunnen we zien dat de eerste regel van de uitvoer het totale aantal beschikbare bytes in het bestand toont. De volgende regel toont het aantal beschikbare bytes aan het einde van de code, dat 3 minder is dan het aantal beschikbare bytes aan het begin. Dit komt omdat we de leesmethode driemaal in onze code hebben gebruikt.
Voorbeeld 04: Bytes van een tekstbestand overslaan om gegevens vanaf een specifiek punt te lezen met behulp van de skip()-methode van de invoerstroomklasse
In dit voorbeeld gebruiken we de methode 'skip(x)' van File Input Stream, die wordt gebruikt om het opgegeven aantal bytes aan gegevens uit de invoerstroom te negeren en te negeren.
In de onderstaande code hebben we eerst een bestandsinvoerstroom gemaakt en deze opgeslagen in de variabele 'a'. Vervolgens hebben we de methode 'a.skip(5)' gebruikt, die de eerste 5 bytes van het bestand overslaat. Vervolgens hebben we de resterende tekens van het bestand afgedrukt met behulp van de 'read()'-methode in een while-lus. Ten slotte hebben we de bestandsinvoerstroom afgesloten met de methode 'close()'.
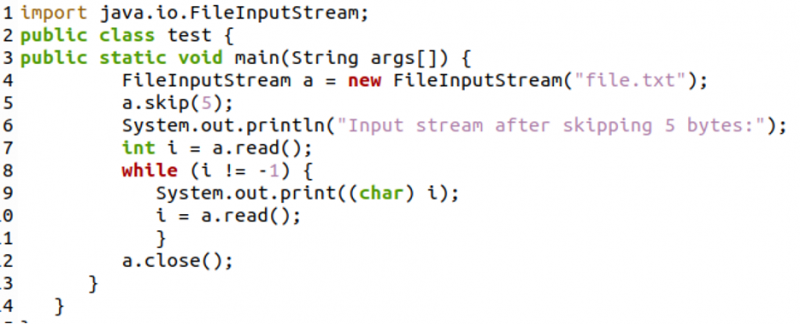
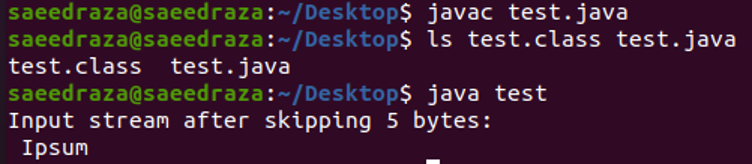
Hieronder ziet u de schermafbeelding van de terminal na het compileren en uitvoeren van de code. Zoals we kunnen zien, wordt alleen 'Ipsum' weergegeven omdat we de eerste 5 bytes hebben overgeslagen met behulp van de 'skip()'-methode.
Conclusie
In dit artikel hebben we het gebruik van de klasse File Input Stream en de verschillende methoden besproken; read(), available(), skip() en close(). We hebben deze methoden gebruikt om het eerste element van een bestand te lezen met behulp van de methoden read() en close(). Vervolgens lezen we het hele bestand via de iteratieve benadering en met dezelfde methoden. Vervolgens hebben we de methode available() gebruikt om het aantal bytes te bepalen dat aanwezig is bij het begin en bij het voltooien van het bestand. Daarna hebben we de methode skip() gebruikt om verschillende bytes over te slaan voordat we het bestand hebben gelezen, waardoor we de specifieke gegevens konden krijgen die we nodig hadden.