In deze tutorial leren we hoe we een Apache Kafka-cluster kunnen implementeren met behulp van de docker. Hierdoor kunnen we de meegeleverde docker-image gebruiken om snel een Kafka-cluster in bijna elke omgeving op te starten.
Laten we beginnen met de basis en bespreken wat Kafka is.
Wat is Apache Kafka?
Apache Kafka is een gratis, open-source, zeer schaalbaar, gedistribueerd en fouttolerant berichtensysteem voor publiceren en abonneren. Het is ontworpen om een hoog volume, hoge doorvoer en real-time datastroom aan te kunnen, waardoor het geschikt is voor vele gebruiksscenario's, waaronder logaggregatie, real-time analyse en event-driven architecturen.
Kafka is gebaseerd op een gedistribueerde architectuur waardoor het grote hoeveelheden gegevens over meerdere servers kan verwerken. Het maakt gebruik van een publish-subscribe-model waarbij de producenten berichten naar de onderwerpen sturen en de consumenten zich erop abonneren om ze te ontvangen. Dit zorgt voor ontkoppelde communicatie tussen de producenten en consumenten, wat zorgt voor een hoge schaalbaarheid en flexibiliteit.
Wat is Docker Compose
Docker compose verwijst naar een docker-plug-in of tool voor het definiëren en uitvoeren van toepassingen met meerdere containers. Docker stelt ons samen om de containerconfiguratie in een YAML-bestand te definiëren. Het configuratiebestand bevat de containerspecificaties zoals de services, netwerken en volumes die vereist zijn voor een toepassing.
Met behulp van de opdracht docker-compose kunnen we meerdere containers maken en starten met een enkele opdracht.
Docker en Docker Compose installeren
De eerste stap is om ervoor te zorgen dat u de docker op uw lokale computer hebt geïnstalleerd. U kunt de volgende bronnen raadplegen voor meer informatie:
- https://linuxhint.com/install_configure_docker_ubuntu/
- https://linuxhint.com/install-docker-debian/
- https://linuxhint.com/install_docker_debian_10/
- https://linuxhint.com/install-docker-ubuntu-22-04/
- https://linuxhint.com/install-docker-on-pop_os/
- https://linuxhint.com/how-to-install-docker-desktop-windows/
- https://linuxhint.com/install-use-docker-centos-8/
- https://linuxhint.com/install_docker_on_raspbian_os/
Op het moment van schrijven van deze zelfstudie vereist het installeren van de docker-compositie de installatie van de Docker-desktop op uw doelcomputer. Daarom wordt het installeren van Docker Compose als een zelfstandige eenheid afgeschaft.
Nadat we de Docker hebben geïnstalleerd, kunnen we het YAML-bestand configureren. Dit bestand bevat alle details die we nodig hebben om een Kafka-cluster te laten draaien met behulp van een docker-container.
De Docker-Compose.YAML instellen
Maak de docker-compose.yaml en bewerk deze met uw favoriete teksteditor:
$ tik op docker-compose.yaml$ vim docker-compose.yaml
Voeg vervolgens het docker-configuratiebestand toe zoals hieronder wordt weergegeven:
versie : '3'Diensten :
dierentuinmedewerker :
afbeelding : bitnami / dierentuinmedewerker : 3.8
havens :
- '2181:2181'
volumes :
- 'dierenverzorger_data:/bitnami'
omgeving :
- ALLOW_ANONYMOUS_LOGIN = Ja
kafka :
afbeelding : havenarbeider. dit / bitnami / kafka : 3.3
havens :
- '9092:9092'
volumes :
- 'kafka_data:/bitnami'
omgeving :
- KAFKA_CFG_ZOOKEEPER_CONNECT = dierentuinmedewerker : 2181
- ALLOW_PLAINTEXT_LISTENER = Ja
hangt af van :
- dierentuinmedewerker
volumes :
dierenverzorger_data :
bestuurder : lokaal
kafka_gegevens :
bestuurder : lokaal
Het voorbeeld docker-bestand stelt een Zookeeper- en een Kafka-cluster in waarbij het Kafka-cluster is verbonden met de Zookeeper-service voor coördinatie. Het bestand configureert ook de poorten en omgevingsvariabelen voor elke service om communicatie en toegang tot de services mogelijk te maken.
We hebben ook de benoemde volumes ingesteld om de gegevens van de services te behouden, zelfs als de containers opnieuw worden opgestart of opnieuw worden gemaakt.
Laten we het vorige bestand opsplitsen in eenvoudige secties:
We beginnen met de Zookeeper-service met behulp van de afbeelding bitnami/zookeeper:3.8. Deze afbeelding wijst vervolgens poort 2181 op de hostcomputer toe aan poort 2181 op de container. We hebben ook de omgevingsvariabele ALLOW_ANONYMOUS_LOGIN ingesteld op 'ja'. Ten slotte stellen we het volume in waarop de service de gegevens opslaat als zookeeper_data volume.
Het tweede blok definieert de details om de Kafka-service in te stellen. In dit geval gebruiken we de docker.io/bitnami/kafka:3.3-afbeelding die de hostpoort 9092 toewijst aan de containerpoort 9092. Evenzo definiëren we ook de omgevingsvariabele KAFKA_CFG_ZOOKEEPER_CONNECT en stellen de waarde ervan in op het adres van Zookeeper zoals toegewezen aan poort 2181. De tweede omgevingsvariabele die we in deze sectie definiëren, is de ALLOW_PLAINTEXT_LISTENER omgevingsvariabele. Door de waarde van deze omgevingsvariabele in te stellen op 'ja', is onbeveiligd verkeer naar het Kafka-cluster mogelijk.
Ten slotte geven we het volume aan waarop de Kafka-service zijn gegevens opslaat.
Om ervoor te zorgen dat de koppelaar de volumes voor Zookeeper en Kafka configureert, moeten we ze definiëren zoals weergegeven in de volumessectie. Hiermee worden de volumes zookeeper_data en kafka_data ingesteld. Beide volumes gebruiken de lokale driver, wat betekent dat de gegevens op de hostcomputer worden opgeslagen.
Daar heb je het! Een eenvoudig configuratiebestand waarmee u in eenvoudige stappen een Kafka-container kunt opstarten met behulp van docker.
Het runnen van de container
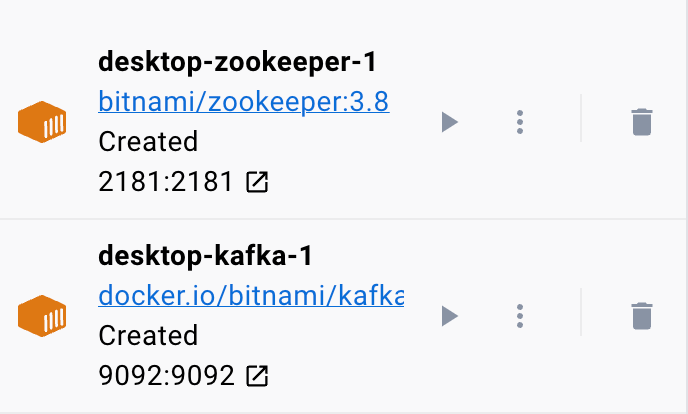
Om ervoor te zorgen dat de docker actief is, kunnen we de container uitvoeren vanuit het YAML-bestand met de volgende opdracht:
$ sudo havenarbeider samenstellenDe opdracht moet het YAML-configuratiebestand lokaliseren en de container uitvoeren met de opgegeven waarden:
Conclusie
U hebt nu geleerd hoe u de Apache Kafka kunt configureren en uitvoeren vanuit een docker compose YAML-configuratiebestand.