In deze handleiding wordt uitgelegd hoe u crawlers maakt om gegevens op te halen uit de S3-bucket.
Hoe een crawler maken om gegevens op te halen uit de S3-bucket?
Om een crawler in AWS te maken, gaat u naar de ' AWS-lijm ”-service van het Amazon-dashboard:
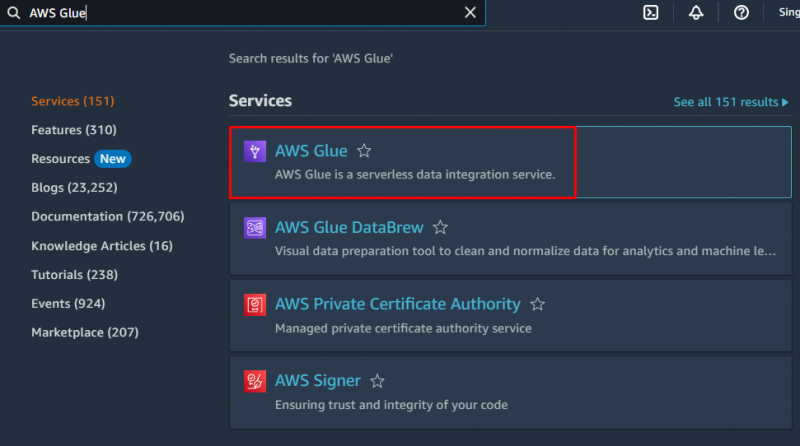
Klik op de ' Databanken ”-knop in de sectie Gegevenscatalogus om een database te maken:
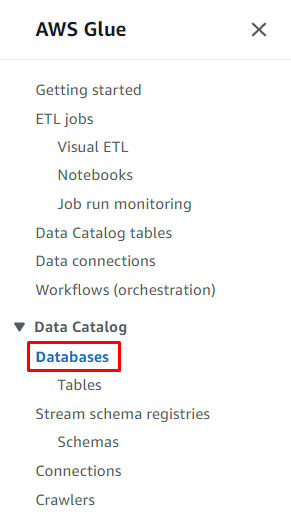
Klik op de ' Databank toevoegen ”-knop om de configuratie te starten:
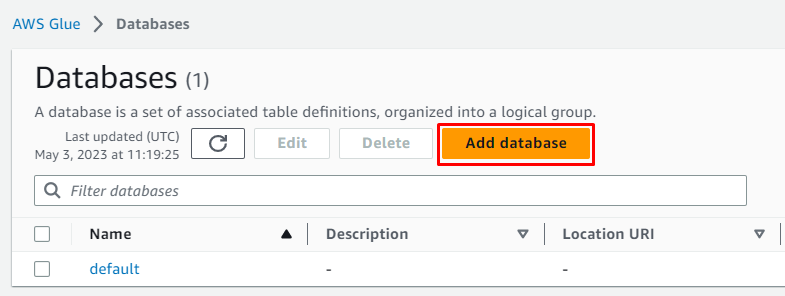
Voer de naam van de database in en laat alles zoals het optioneel is voordat u op de knop ' Maak een databank aan ' knop:
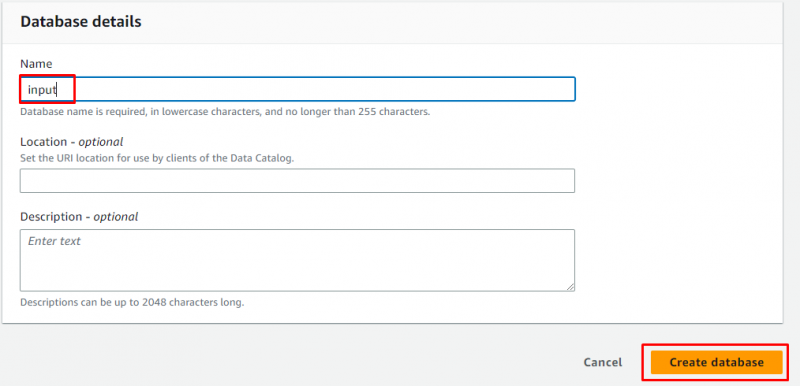
De database is succesvol aangemaakt:
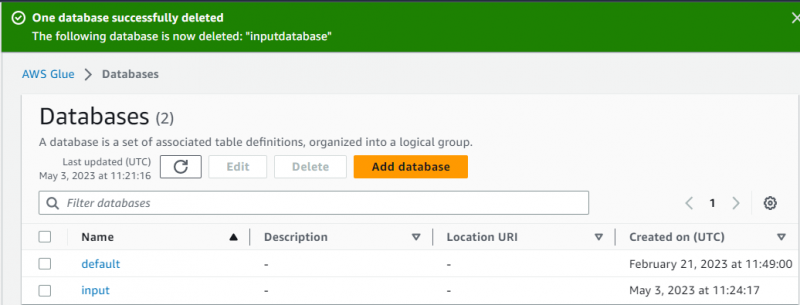
Ga daarna gewoon naar de ' Kruipers '-pagina door erop te klikken in het linkerdeelvenster:
Klik op de ' Maak een crawler ' knop:

Typ de naam van de crawler en klik op de ' Volgende ' knop:

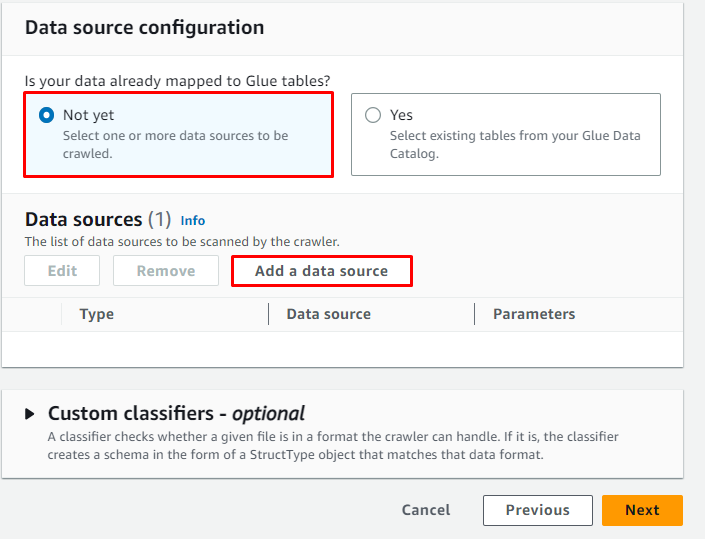
Klik op de ' Voeg een gegevensbron toe ”-knop om de bron van de gegevens te selecteren:
Ga naar de S3-service om het pad te controleren waar de gegevens zijn opgeslagen:
Ga naar de S3-bucket waar de gegevens worden geüpload. De gebruiker kan creëren een emmer en uploaden gegevens erop vanuit het AWS S3-dashboard:

Klik op de ' Blader door S3 ” knop om het pad van de gegevens te kiezen:
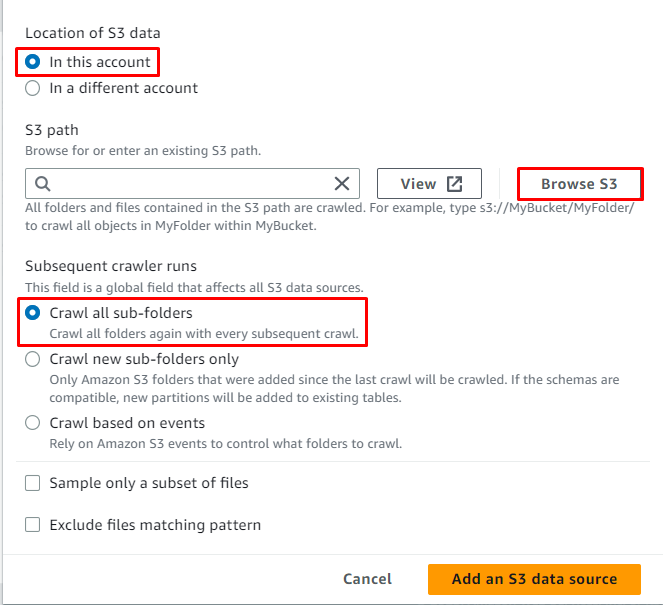
Selecteer de map met de gegevens en klik vervolgens op de knop ' Kiezen ' knop:

Het S3-pad is geselecteerd, klik nu op de ' Voeg een S3-gegevensbron toe ' knop:

Zodra de gegevensbron is toegevoegd, klikt u eenvoudig op de knop ' Volgende ' knop:
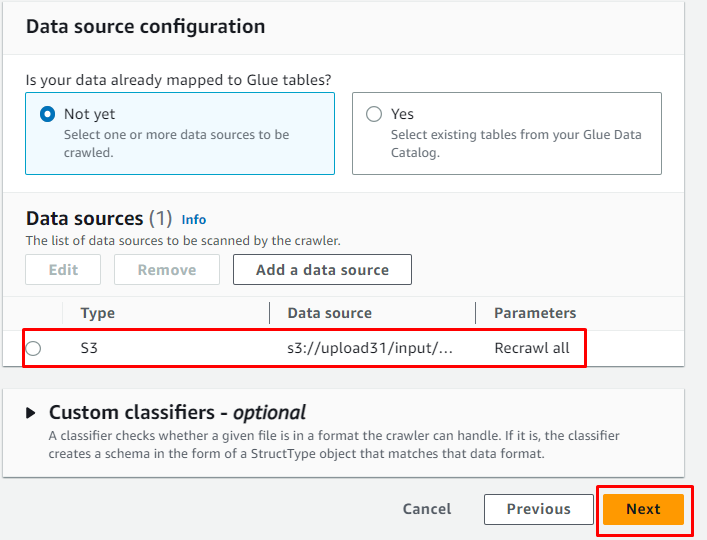
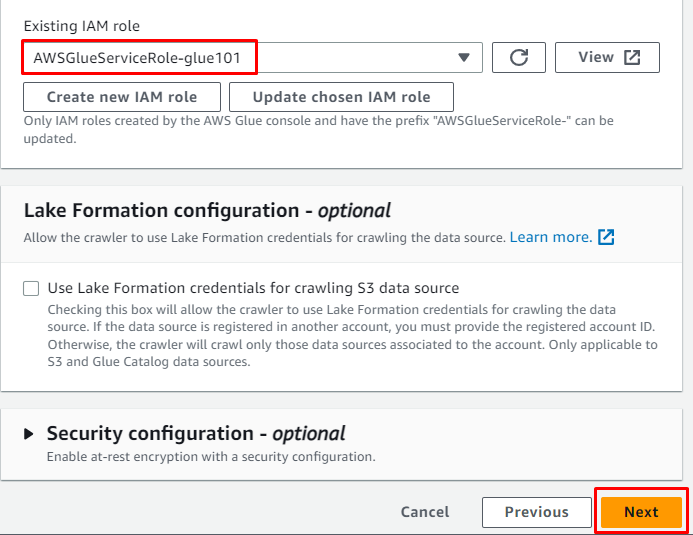
Voeg de IAM-rol toe en klik vervolgens op de “ Volgende ' knop:
Voer de eerder gemaakte doeldatabase in en typ vervolgens de naam voor de tabel:
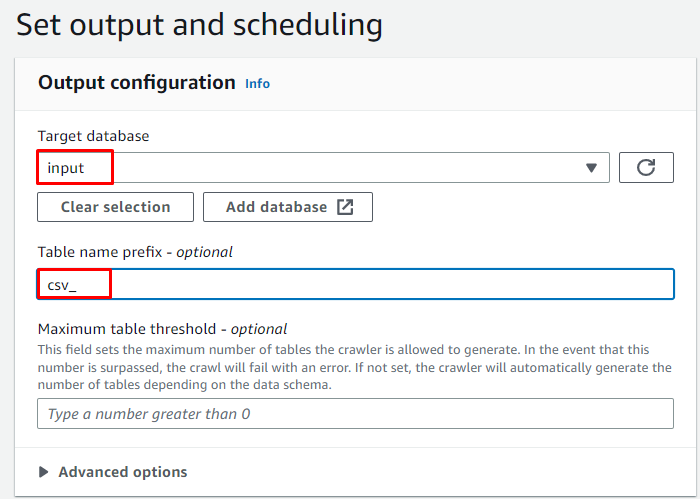
Selecteer het On demand-schema voor de crawler en klik op de knop ' Volgende ' knop:
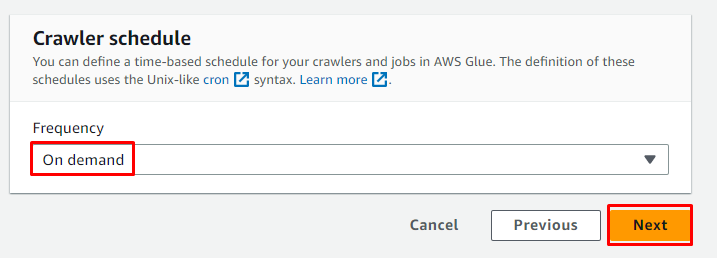
Bekijk de crawler en klik op de ' Maak een crawler ' knop:
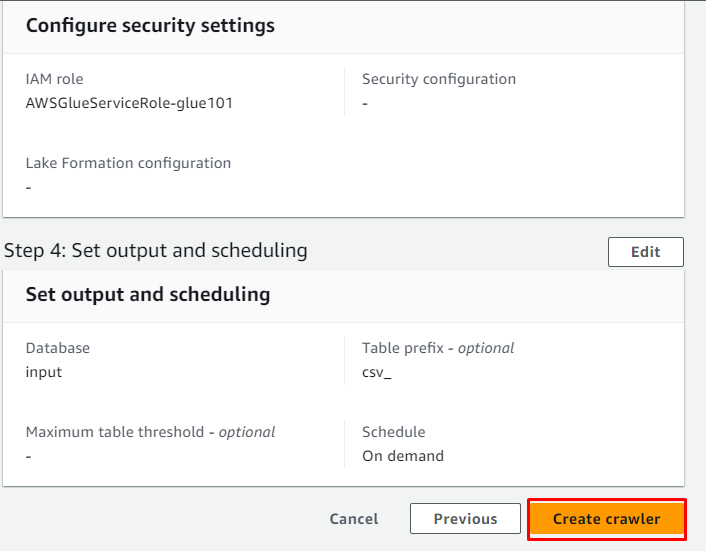
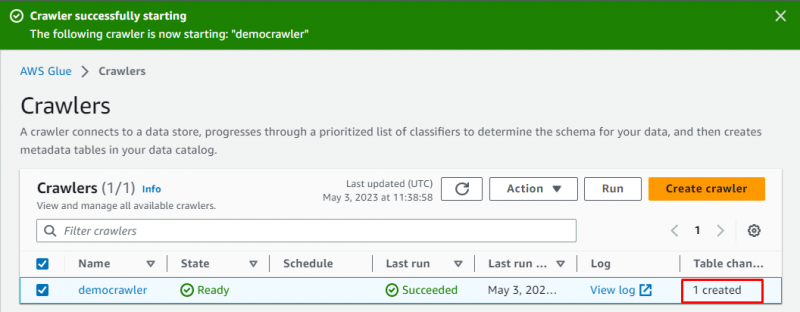
De crawler is succesvol aangemaakt, klik op de ' Loop ”-knop nadat u deze hebt geselecteerd:

Het duurt even om de crawler uit te voeren en hij zal gegevens ophalen en een tabel maken om de gegevens op te slaan:
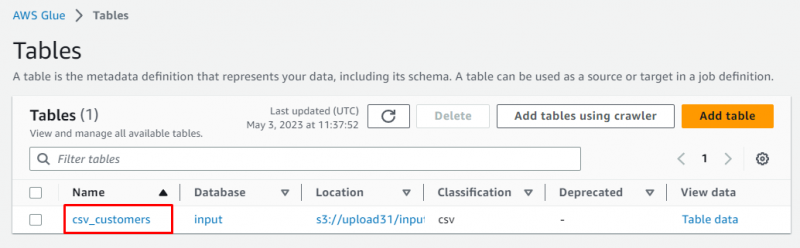
Ga naar de “ Tafels '-pagina van het Glue-dashboard:
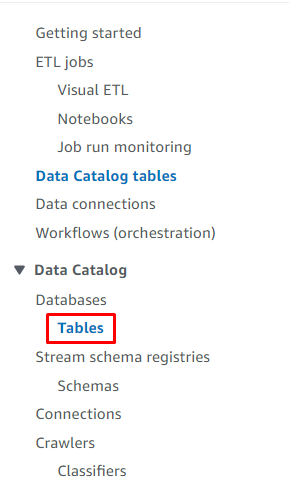
Selecteer de tabel door op de naam te klikken:
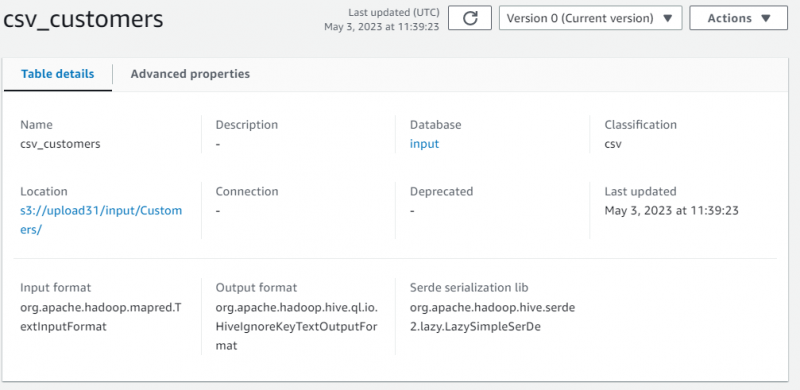
De verhaaldetails zijn weergegeven met de metadata van de opgehaalde gegevens:
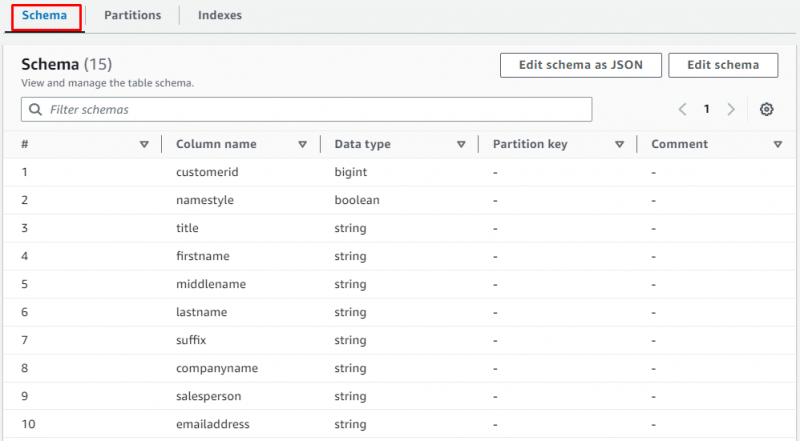
Scroll naar beneden op de pagina en selecteer de sectie om de tabel met de gegevens te bekijken:
Dat is alles over het maken van een crawler om gegevens op te halen uit de S3-bucket.
Conclusie
Als u een crawler wilt maken om gegevens uit de S3-bucket op te halen, maakt u een database op AWS Glue waarin de gecrawlde gegevens worden opgeslagen. Configureer de crawler vanuit het Glue-dashboard door de gegevensbron (S3-bucket) en de doeldatabase op te geven. Voer de crawler uit en haal de gegevens uit de S3-bucket naar de databasetabel, zoals in deze handleiding grondig is uitgelegd.