Deze handleiding illustreert hoe u VectorStoreRetrieverMemory kunt gebruiken met behulp van het LangChain-framework.
Hoe gebruik ik VectorStoreRetrieverMemory in LangChain?
De VectorStoreRetrieverMemory is de bibliotheek van LangChain die kan worden gebruikt om informatie/gegevens uit het geheugen te extraheren met behulp van de vectorwinkels. Vectorwinkels kunnen worden gebruikt om gegevens op te slaan en te beheren om de informatie efficiënt te extraheren op basis van de prompt of vraag.
Om het proces van het gebruik van VectorStoreRetrieverMemory in LangChain te leren, volgt u eenvoudigweg de volgende handleiding:
Stap 1: Modules installeren
Start het proces van het gebruik van de memory retriever door de LangChain te installeren met behulp van de pip-opdracht:
pip installeer langchain
Installeer de FAISS-modules om de gegevens te verkrijgen met behulp van de semantische gelijkeniszoekopdracht:
pip installeer faiss-gpu 
Installeer de chromadb-module voor het gebruik van de Chroma-database. Het werkt als vectoropslag om het geheugen voor de retriever op te bouwen:
pip installeer chromadb 
Er is een andere module tiktoken nodig om te installeren, die kan worden gebruikt om tokens te maken door gegevens in kleinere stukjes te converteren:
pip installeer tiktoken 
Installeer de OpenAI-module om de bibliotheken te gebruiken voor het bouwen van LLM's of chatbots met behulp van de omgeving:
pip installeer openai 
Stel de omgeving in op de Python IDE of notebook met behulp van de API-sleutel van het OpenAI-account:
importeren Jijimporteren Krijg een pas
Jij . ongeveer [ 'OPENAI_API_KEY' ] = Krijg een pas . Krijg een pas ( 'OpenAI API-sleutel:' )
Stap 2: Bibliotheken importeren
De volgende stap is het ophalen van de bibliotheken uit deze modules voor het gebruik van de geheugenretriever in LangChain:
van langketen. aanwijzingen importeren Promptsjabloonvan datum Tijd importeren datum Tijd
van langketen. llms importeren OpenAI
van langketen. inbedding . openai importeren OpenAIE-inbedding
van langketen. kettingen importeren ConversatieKeten
van langketen. geheugen importeren VectorStoreRetrieverGeheugen
Stap 3: Vector Store initialiseren
Deze handleiding gebruikt de Chroma-database na het importeren van de FAISS-bibliotheek om de gegevens te extraheren met behulp van de invoeropdracht:
importeren faisvan langketen. docstore importeren InMemoryDocstore
#importerende bibliotheken voor het configureren van de databases of vectorwinkels
van langketen. vectorwinkels importeren FAISS
#creëer insluitingen en teksten om ze op te slaan in de vectorwinkels
inbedding_grootte = 1536
inhoudsopgave = fais. IndexFlatL2 ( inbedding_grootte )
embedding_fn = OpenAIE-inbedding ( ) . embed_query
vectorwinkel = FAISS ( embedding_fn , inhoudsopgave , InMemoryDocstore ( { } ) , { } )
Stap 4: Retriever bouwen, ondersteund door een vectorwinkel
Bouw het geheugen op om de meest recente berichten in het gesprek op te slaan en de context van de chat te krijgen:
terugvinder = vectorwinkel. als_retriever ( zoek_kwargs = dictaat ( k = 1 ) )geheugen = VectorStoreRetrieverGeheugen ( terugvinder = terugvinder )
geheugen. bewaar_context ( { 'invoer' : 'Ik eet graag pizza' } , { 'uitvoer' : 'fantastisch' } )
geheugen. bewaar_context ( { 'invoer' : ‘Ik ben goed in voetbal’ } , { 'uitvoer' : 'OK' } )
geheugen. bewaar_context ( { 'invoer' : ‘Ik houd niet van de politiek’ } , { 'uitvoer' : 'Zeker' } )
Test het geheugen van het model met behulp van de invoer van de gebruiker met zijn geschiedenis:
afdrukken ( geheugen. laad_geheugen_variabelen ( { 'snel' : 'Welke sport moet ik kijken?' } ) [ 'geschiedenis' ] ) 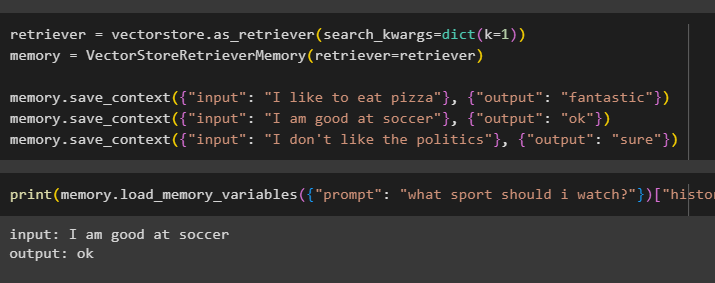
Stap 5: Retriever in een ketting gebruiken
De volgende stap is het gebruik van een geheugenretriever met de ketens door de LLM te bouwen met behulp van de OpenAI()-methode en de promptsjabloon te configureren:
llm = OpenAI ( temperatuur = 0 )_DEFAULT_TEMPLATE = '''Het is een interactie tussen een mens en een machine
Het systeem produceert nuttige informatie met details met behulp van context
Als het systeem het antwoord niet voor u heeft, zegt het eenvoudigweg: ik heb het antwoord niet
Belangrijke informatie uit het gesprek:
{geschiedenis}
(als de tekst niet relevant is, gebruik deze dan niet)
Huidige chat:
Mens: {invoer}
AI:'''
SNEL = Promptsjabloon (
invoervariabelen = [ 'geschiedenis' , 'invoer' ] , sjabloon = _DEFAULT_TEMPLATE
)
#configure de ConversationChain() met behulp van de waarden voor de parameters
gesprek_met_samenvatting = ConversatieKeten (
llm = llm ,
snel = SNEL ,
geheugen = geheugen ,
uitgebreid = WAAR
)
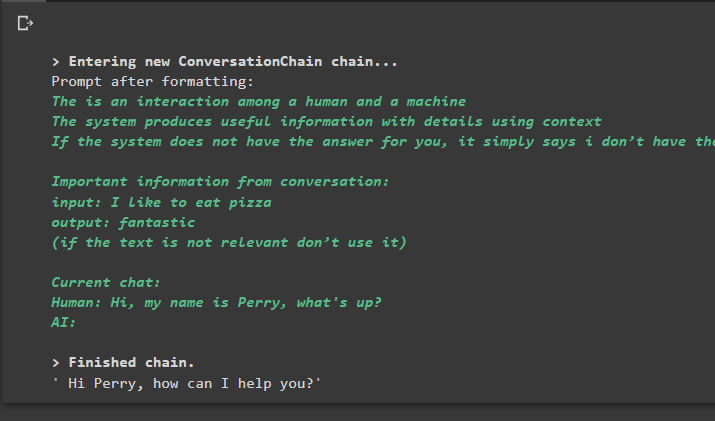
gesprek_met_samenvatting. voorspellen ( invoer = 'Hallo, mijn naam is Perry, wat is er?' )
Uitvoer
Als u de opdracht uitvoert, wordt de keten uitgevoerd en wordt het antwoord weergegeven dat door het model of de LLM wordt gegeven:
Ga verder met het gesprek met behulp van de prompt op basis van de gegevens die zijn opgeslagen in de vectoropslag:
gesprek_met_samenvatting. voorspellen ( invoer = 'Wat is mijn favoriete sport?' ) 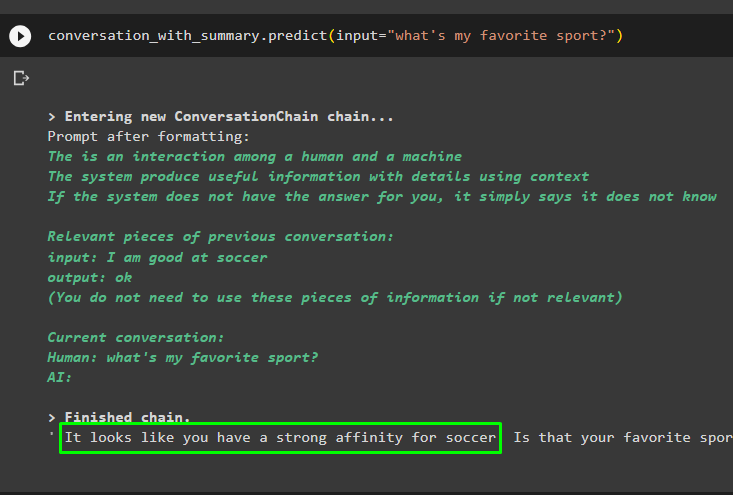
De eerdere berichten worden opgeslagen in het geheugen van het model, dat door het model kan worden gebruikt om de context van het bericht te begrijpen:
gesprek_met_samenvatting. voorspellen ( invoer = 'Wat is mijn favoriete eten' ) 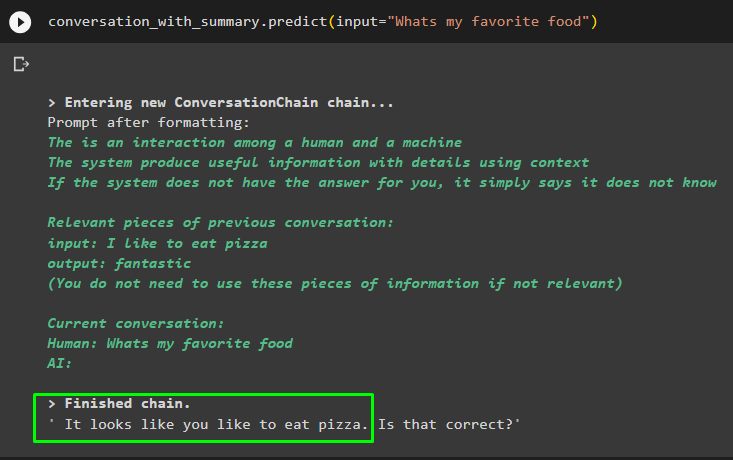
Ontvang het antwoord aan het model in een van de voorgaande berichten om te controleren hoe de memory retriever werkt met het chatmodel:
gesprek_met_samenvatting. voorspellen ( invoer = 'Wat is mijn naam?' )Het model heeft de uitvoer correct weergegeven met behulp van het zoeken naar overeenkomsten op basis van de gegevens die in het geheugen zijn opgeslagen:
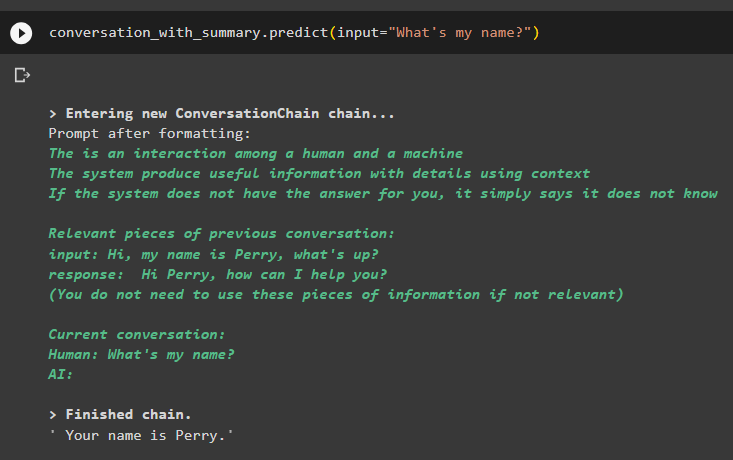
Dat gaat allemaal over het gebruik van de vector store retriever in LangChain.
Conclusie
Om de geheugenretriever op basis van een vectorwinkel in LangChain te gebruiken, installeert u eenvoudig de modules en frameworks en stelt u de omgeving in. Importeer daarna de bibliotheken uit de modules om de database te bouwen met behulp van Chroma en stel vervolgens de promptsjabloon in. Test de retriever nadat u gegevens in het geheugen heeft opgeslagen door het gesprek te starten en vragen te stellen over de eerdere berichten. In deze handleiding wordt dieper ingegaan op het gebruik van de VectorStoreRetrieverMemory-bibliotheek in LangChain.