Hoe gebruik ik een gespreksbuffervenster in LangChain?
Het gespreksbuffervenster wordt gebruikt om de meest recente berichten van het gesprek in het geheugen te bewaren om de meest recente context te verkrijgen. Het gebruikt de waarde van de K voor het opslaan van de berichten of tekenreeksen in het geheugen met behulp van het LangChain-framework.
Om het proces van het gebruik van het gespreksbuffervenster in LangChain te leren, volgt u eenvoudigweg de volgende handleiding:
Stap 1: Modules installeren
Start het proces van het gebruik van het gespreksbuffervenster door de LangChain-module te installeren met de vereiste afhankelijkheden voor het bouwen van gespreksmodellen:
pip installeer langchain
Installeer daarna de OpenAI-module die kan worden gebruikt om de grote taalmodellen in LangChain te bouwen:
pip installeer openai
Nu, het opzetten van de OpenAI-omgeving om de LLM-ketens te bouwen met behulp van de API-sleutel van het OpenAI-account:
importeren Jij
importeren Krijg een pas
Jij . ongeveer [ 'OPENAI_API_KEY' ] = Krijg een pas . Krijg een pas ( 'OpenAI API-sleutel:' )
Stap 2: Het gespreksbuffervenstergeheugen gebruiken
Om het gespreksbuffervenstergeheugen in LangChain te gebruiken, importeert u het ConversatieBufferWindowMemory bibliotheek:
van langketen. geheugen importeren ConversatieBufferWindowMemoryConfigureer het geheugen met behulp van de ConversatieBufferWindowMemory () methode met de waarde van k als argument. De waarde van k wordt gebruikt om de meest recente berichten uit het gesprek te behouden en vervolgens de trainingsgegevens te configureren met behulp van de invoer- en uitvoervariabelen:
geheugen = ConversatieBufferWindowMemory ( k = 1 )geheugen. bewaar_context ( { 'invoer' : 'Hallo' } , { 'uitvoer' : 'Hoe is het met je' } )
geheugen. bewaar_context ( { 'invoer' : 'Met mij is alles in orde, hoe gaat het met jou' } , { 'uitvoer' : 'niet veel' } )
Test het geheugen door de laad_geheugen_variabelen () methode om het gesprek te starten:
geheugen. laad_geheugen_variabelen ( { } ) 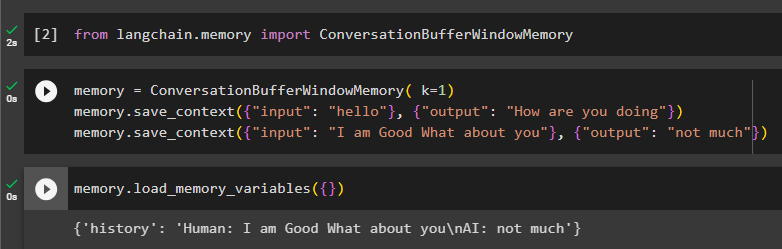
Om de geschiedenis van het gesprek op te halen, configureert u de functie ConversationBufferWindowMemory() met behulp van de return_messages argument:
geheugen = ConversatieBufferWindowMemory ( k = 1 , return_messages = WAAR )geheugen. bewaar_context ( { 'invoer' : 'Hoi' } , { 'uitvoer' : 'wat is er' } )
geheugen. bewaar_context ( { 'invoer' : 'niet veel Jij' } , { 'uitvoer' : 'niet veel' } )
Roep nu het geheugen op met behulp van de laad_geheugen_variabelen () methode om het antwoord te krijgen met de geschiedenis van het gesprek:
geheugen. laad_geheugen_variabelen ( { } ) 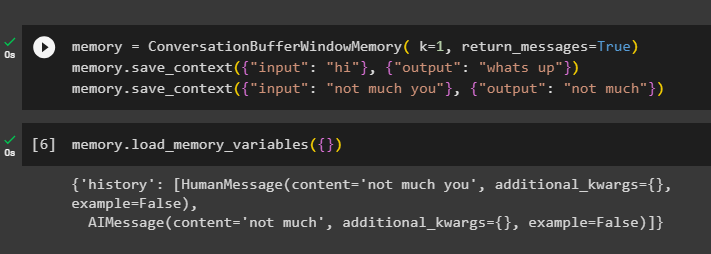
Stap 3: Buffervenster in een keten gebruiken
Bouw de keten met behulp van de OpenAI En ConversatieKeten bibliotheken en configureer vervolgens het buffergeheugen om de meest recente berichten in het gesprek op te slaan:
van langketen. kettingen importeren ConversatieKetenvan langketen. llms importeren OpenAI
#samenvatting van het gesprek opbouwen met behulp van meerdere parameters
gesprek_met_samenvatting = ConversatieKeten (
llm = Open AI ( temperatuur = 0 ) ,
#building geheugenbuffer met behulp van zijn functie met de waarde k om recente berichten op te slaan
geheugen = ConversatieBufferWindowMemory ( k = 2 ) ,
#configure uitgebreide variabele om beter leesbare uitvoer te krijgen
uitgebreid = WAAR
)
gesprek_met_samenvatting. voorspellen ( invoer = 'Hoi, hoe is het' )
Houd het gesprek nu gaande door de vraag te stellen die verband houdt met de output van het model:
gesprek_met_samenvatting. voorspellen ( invoer = 'Wat zijn hun problemen' ) 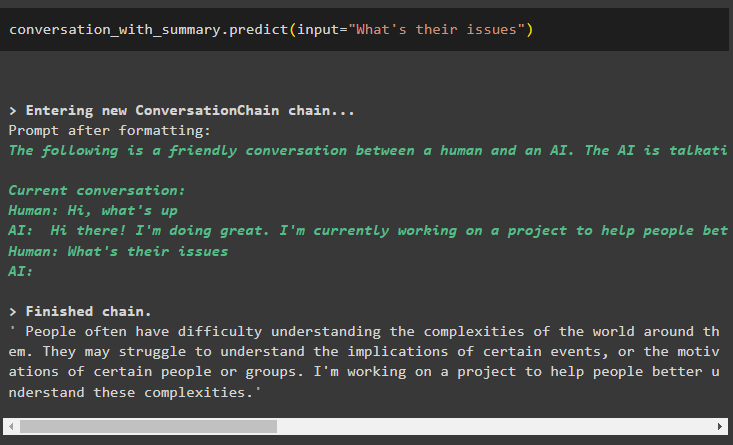
Het model is geconfigureerd om slechts één eerder bericht op te slaan dat als context kan worden gebruikt:
gesprek_met_samenvatting. voorspellen ( invoer = 'Gaat het goed' ) 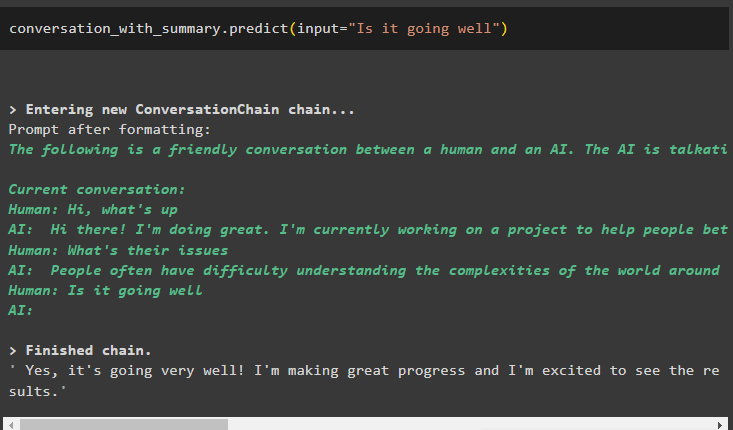
Vraag naar de oplossing voor de problemen en de uitvoerstructuur zal het buffervenster blijven verschuiven door de eerdere berichten te verwijderen:
gesprek_met_samenvatting. voorspellen ( invoer = 'Wat is de oplossing' ) 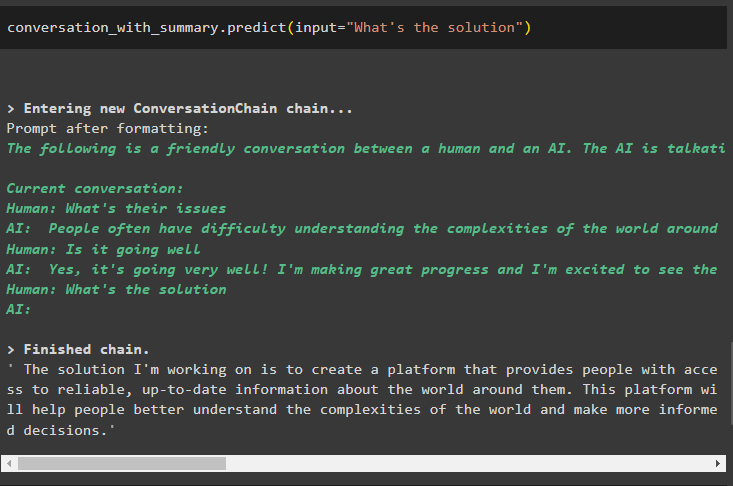
Dat gaat allemaal over het proces van het gebruik van de gespreksbuffervensters LangChain.
Conclusie
Om het gespreksbuffervenstergeheugen in LangChain te gebruiken, installeert u eenvoudig de modules en stelt u de omgeving in met behulp van de API-sleutel van OpenAI. Bouw daarna het buffergeheugen op met behulp van de waarde k om de meest recente berichten in het gesprek te behouden en de context te behouden. Het buffergeheugen kan ook worden gebruikt bij ketens om het gesprek met de LLM of keten op gang te brengen. In deze handleiding wordt dieper ingegaan op het proces van het gebruik van het gespreksbuffervenster in LangChain.