Snel overzicht
Dit bericht bevat de volgende secties:
- Hoe u een asynchrone API-agent in LangChain gebruikt
- Methode 1: Seriële uitvoering gebruiken
- Methode 2: Gelijktijdige uitvoering gebruiken
- Conclusie
Hoe gebruik ik een asynchrone API-agent in LangChain?
Chatmodellen voeren meerdere taken tegelijkertijd uit, zoals het begrijpen van de structuur van de prompt, de complexiteit ervan, het extraheren van informatie en nog veel meer. Door de Async API-agent in LangChain te gebruiken, kan de gebruiker efficiënte chatmodellen bouwen die meerdere vragen tegelijk kunnen beantwoorden. Volg eenvoudigweg deze handleiding om het proces van het gebruik van de Async API-agent in LangChain te leren:
Stap 1: Frameworks installeren
Installeer eerst het LangChain-framework om de afhankelijkheden van de Python-pakketbeheerder op te halen:
pip installeer langchain
Installeer daarna de OpenAI-module om het taalmodel zoals llm te bouwen en de omgeving in te stellen:
pip installeer openai
Stap 2: OpenAI-omgeving
De volgende stap na de installatie van modules is het opzetten van de omgeving met behulp van de API-sleutel van OpenAI en Serper-API om gegevens van Google te zoeken:
importeren Jij
importeren Krijg een pas
Jij . ongeveer [ 'OPENAI_API_KEY' ] = Krijg een pas . Krijg een pas ( 'OpenAI API-sleutel:' )
Jij . ongeveer [ 'SERPER_API_KEY' ] = Krijg een pas . Krijg een pas ( 'Serper API-sleutel:' )
Stap 3: Bibliotheken importeren
Nu de omgeving is ingesteld, importeert u eenvoudigweg de vereiste bibliotheken zoals asyncio en andere bibliotheken met behulp van de LangChain-afhankelijkheden:
van langketen. agenten importeren initialiseer_agent , laad_toolsimporteren tijd
importeren asynchroon
van langketen. agenten importeren Agenttype
van langketen. llms importeren OpenAI
van langketen. terugbellen . stoer importeren StdOutCallbackHandler
van langketen. terugbellen . tracers importeren LangChainTracer
van aiohttp importeren Klantsessie
Stap 4: Installatievragen
Stel een vraagdataset in met meerdere zoekopdrachten gerelateerd aan verschillende domeinen of onderwerpen die op internet (Google) kunnen worden doorzocht:
vragen = ['Wie is de winnaar van het US Open kampioenschap in 2021' ,
'Wat is de leeftijd van het vriendje van Olivia Wilde' ,
'Wie is de winnaar van de wereldtitel Formule 1' ,
'Wie won de US Open damesfinale in 2021' ,
'Wie is de echtgenoot van Beyoncé en wat is zijn leeftijd' ,
]
Methode 1: Seriële uitvoering gebruiken
Zodra alle stappen zijn voltooid, voert u eenvoudigweg de vragen uit om alle antwoorden te krijgen met behulp van de seriële uitvoering. Het betekent dat één vraag tegelijk wordt uitgevoerd/weergegeven en ook de volledige tijd retourneert die nodig is om deze vragen uit te voeren:
llm = OpenAI ( temperatuur = 0 )hulpmiddelen = laad_tools ( [ 'google-header' , 'llm-wiskunde' ] , llm = llm )
tussenpersoon = initialiseer_agent (
hulpmiddelen , llm , tussenpersoon = Agenttype. ZERO_SHOT_REACT_DESCRIPTION , uitgebreid = WAAR
)
S = tijd . perf_teller ( )
#configuring time counter om de tijd te krijgen die voor het volledige proces wordt gebruikt
voor Q in vragen:
tussenpersoon. loop ( Q )
verstreken = tijd . perf_teller ( ) - S
#print de totale tijd die de agent heeft gebruikt om de antwoorden te krijgen
afdrukken ( F 'Serie uitgevoerd in {verstreken:0,2f} seconden.' )
Uitvoer
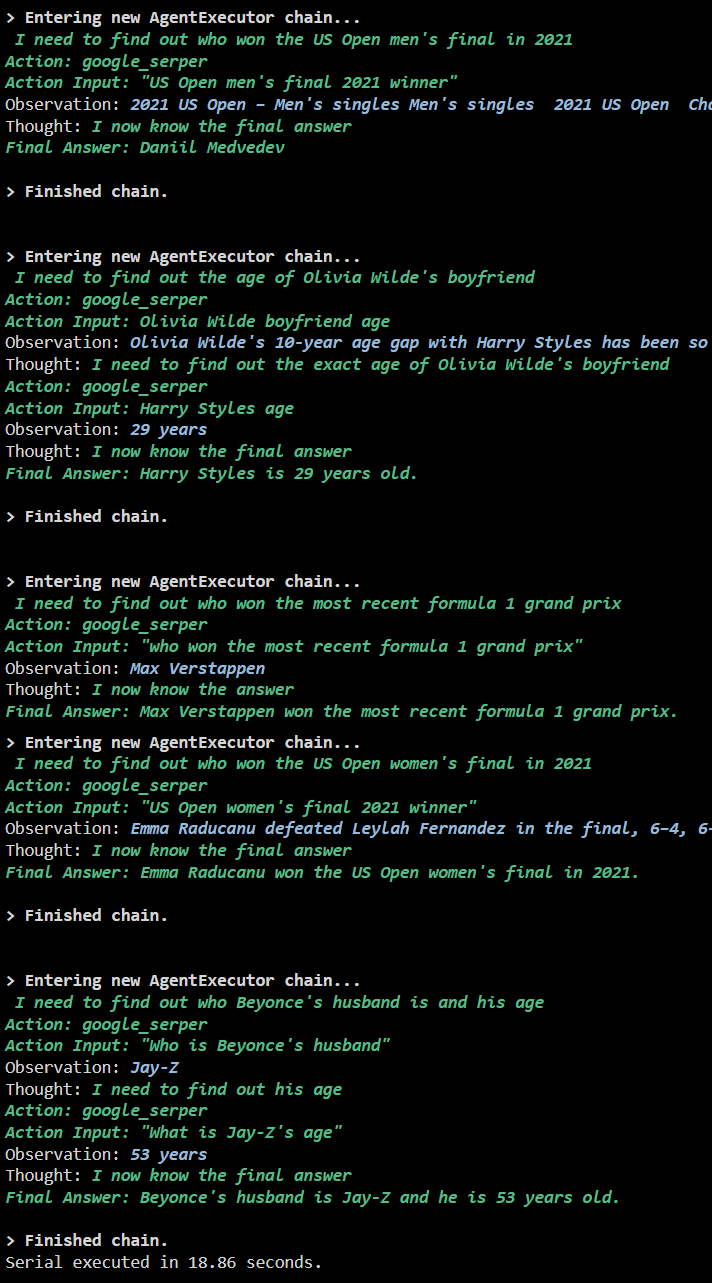
De volgende schermafbeelding laat zien dat elke vraag in een afzonderlijke keten wordt beantwoord en zodra de eerste keten is voltooid, wordt de tweede keten actief. De seriële uitvoering kost meer tijd om alle antwoorden afzonderlijk te krijgen:
Methode 2: Gelijktijdige uitvoering gebruiken
De gelijktijdige uitvoeringsmethode neemt alle vragen en krijgt de antwoorden tegelijkertijd.
llm = OpenAI ( temperatuur = 0 )hulpmiddelen = laad_tools ( [ 'google-header' , 'llm-wiskunde' ] , llm = llm )
#Configureer de agent met behulp van de bovenstaande tools om gelijktijdig antwoorden te krijgen
tussenpersoon = initialiseer_agent (
hulpmiddelen , llm , tussenpersoon = Agenttype. ZERO_SHOT_REACT_DESCRIPTION , uitgebreid = WAAR
)
#configuring time counter om de tijd te krijgen die voor het volledige proces wordt gebruikt
S = tijd . perf_teller ( )
taken = [ tussenpersoon. ziekte ( Q ) voor Q in vragen ]
wacht asynchroon. bijeenkomen ( *taken )
verstreken = tijd . perf_teller ( ) - S
#print de totale tijd die de agent heeft gebruikt om de antwoorden te krijgen
afdrukken ( F 'Gelijktijdig uitgevoerd in {verstreken:0,2f} seconden' )
Uitvoer
De gelijktijdige uitvoering extraheert alle gegevens tegelijkertijd en kost veel minder tijd dan de seriële uitvoering:
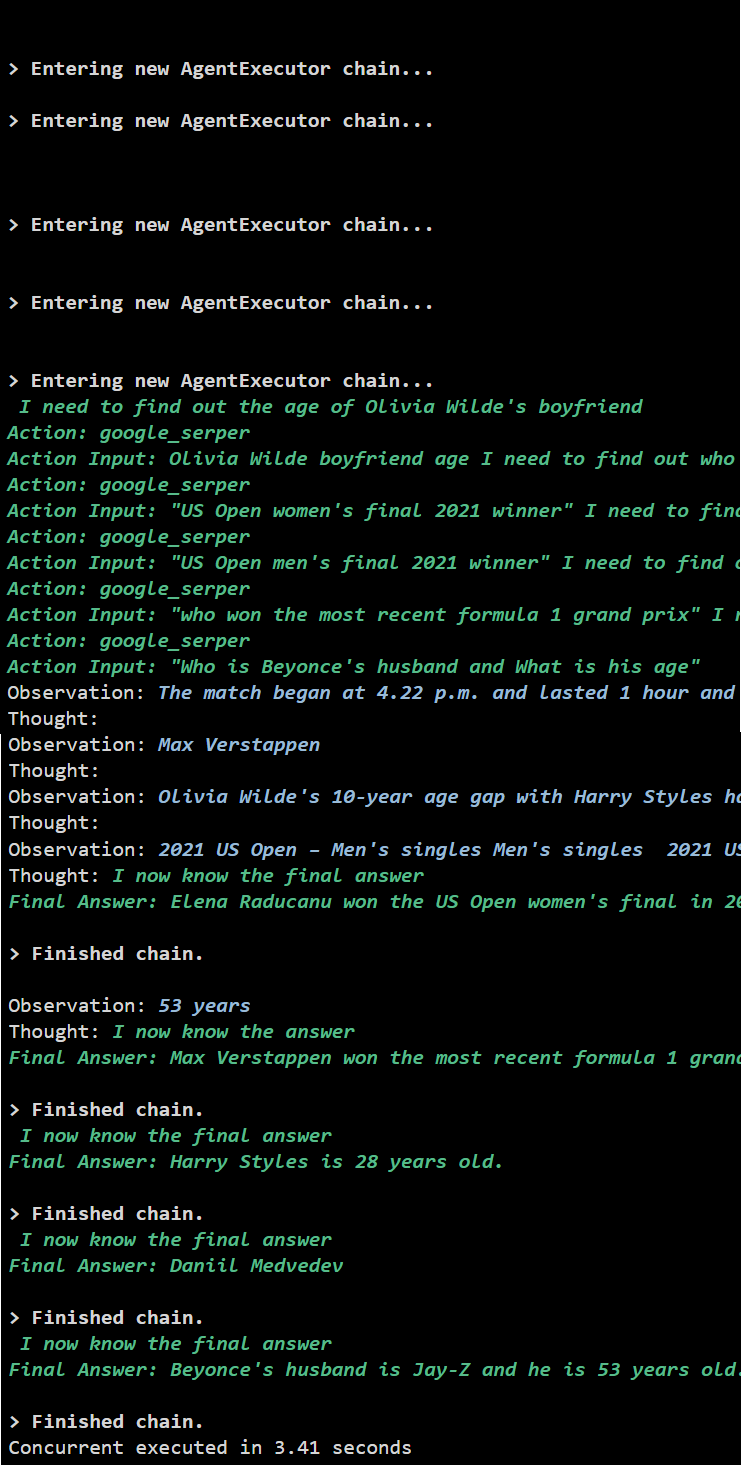
Dat draait allemaal om het gebruik van de Async API-agent in LangChain.
Conclusie
Om de Async API-agent in LangChain te gebruiken, installeert u eenvoudigweg de modules om de bibliotheken van hun afhankelijkheden te importeren om de asyncio-bibliotheek te verkrijgen. Stel daarna de omgevingen in met behulp van de OpenAI- en Serper API-sleutels door in te loggen op hun respectievelijke accounts. Configureer de reeks vragen met betrekking tot verschillende onderwerpen en voer de ketens serieel en gelijktijdig uit om hun uitvoeringstijd te verkrijgen. In deze handleiding wordt dieper ingegaan op het proces van het gebruik van de Async API-agent in LangChain.