In dit artikel bespreken we hoe u kunt verdelen VERSCHILLEND geheugen via de “ pytorch_cuda_alloc_conf methode.
Wat is de “pytorch_cuda_alloc_conf”-methode in PyTorch?
In wezen is de “ pytorch_cuda_alloc_conf ” is een omgevingsvariabele binnen het PyTorch-framework. Deze variabele maakt een efficiënt beheer van de beschikbare verwerkingsbronnen mogelijk, wat betekent dat de modellen in de kortst mogelijke tijd worden uitgevoerd en resultaten opleveren. Als dit niet goed wordt gedaan, wordt de “ VERSCHILLEND 'berekeningsplatform toont de' uit het geheugen ”fout en beïnvloedt de runtime. Modellen die moeten worden getraind over grote hoeveelheden gegevens of die grote “ batchgroottes ” kan runtimefouten veroorzaken omdat de standaardinstellingen hiervoor mogelijk niet voldoende zijn.
De ' pytorch_cuda_alloc_conf 'variabele gebruikt het volgende' opties ” om de toewijzing van middelen af te handelen:
- oorspronkelijk : deze optie gebruikt de reeds beschikbare instellingen in PyTorch om geheugen toe te wijzen aan het lopende model.
- max_split_size_mb : Het zorgt ervoor dat elk codeblok groter dan de opgegeven grootte niet wordt opgesplitst. Dit is een krachtig hulpmiddel om “ fragmentatie ”. We zullen deze optie gebruiken voor de demonstratie in dit artikel.
- roundup_power2_divisies : Deze optie rondt de grootte van de toewijzing af naar de dichtstbijzijnde “ kracht van 2 ”verdeling in megabytes (MB).
- roundup_bypass_threshold_mb: Het kan de toewijzingsgrootte naar boven afronden voor elk verzoek dat meer dan de opgegeven drempelwaarde vermeldt.
- garbage_collection_threshold : Het voorkomt latentie door het beschikbare geheugen van de GPU in realtime te gebruiken om ervoor te zorgen dat het reclaim-all-protocol niet wordt gestart.
Hoe geheugen toewijzen met behulp van de “pytorch_cuda_alloc_conf” -methode?
Elk model met een aanzienlijke gegevensset vereist extra geheugentoewijzing die groter is dan de standaardinstelling. De aangepaste toewijzing moet worden gespecificeerd, waarbij rekening moet worden gehouden met de modelvereisten en de beschikbare hardwarebronnen.
Volg de onderstaande stappen om de “ pytorch_cuda_alloc_conf ”-methode in de Google Colab IDE om meer geheugen toe te wijzen aan een complex machine-learning-model:
Stap 1: Open Google Colab
Zoek naar Google Samenwerkend in de browser en maak een “ Nieuw notitieboekje ” om te gaan werken:
Stap 2: Stel een aangepast PyTorch-model in
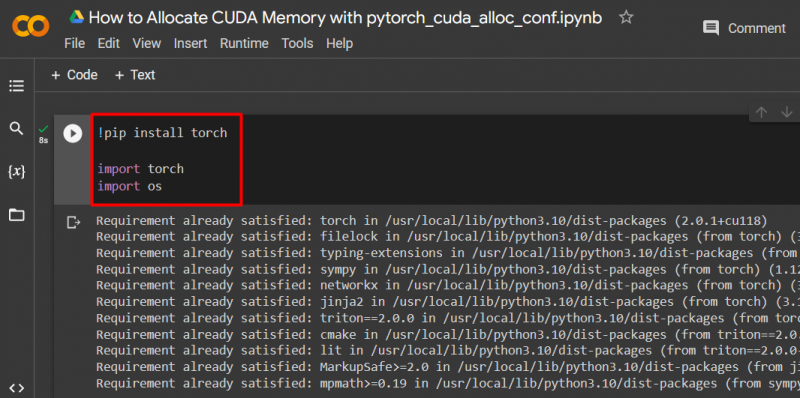
Stel een PyTorch-model in met behulp van de “ !Pip ” installatiepakket om de “ fakkel ” bibliotheek en de “ importeren 'commando om te importeren' fakkel ' En ' Jij ”bibliotheken in het project:
fakkel importeren
importeer ons
Voor dit project zijn de volgende bibliotheken nodig:
- Fakkel – Dit is de fundamentele bibliotheek waarop PyTorch is gebaseerd.
- JIJ - De ' besturingssysteem ”-bibliotheek wordt gebruikt voor het afhandelen van taken die verband houden met omgevingsvariabelen zoals “ pytorch_cuda_alloc_conf ”evenals de systeemmap en de bestandsrechten:
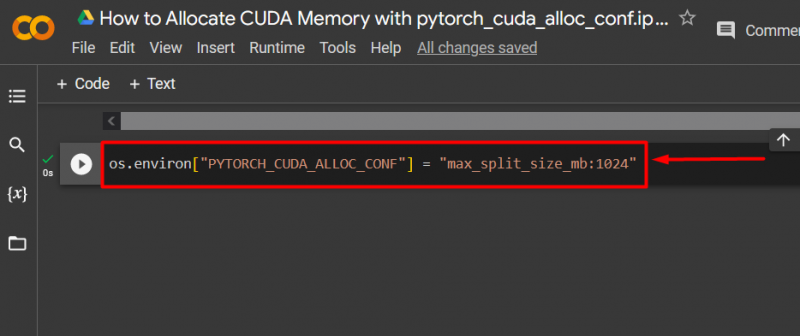
Stap 3: Wijs CUDA-geheugen toe
Gebruik de ' pytorch_cuda_alloc_conf ”-methode om de maximale gesplitste grootte op te geven met “ max_split_size_mb ”:
Stap 4: Ga verder met uw PyTorch-project
Na het specificeren van “ VERSCHILLEND ” ruimtetoewijzing met de “ max_split_size_mb ' optie, blijf normaal aan het PyTorch-project werken zonder angst voor de ' uit het geheugen ' fout.
Opmerking : U kunt hier toegang krijgen tot ons Google Colab-notebook koppeling .
Pro-tip
Zoals eerder vermeld is de “ pytorch_cuda_alloc_conf '-methode kan elk van de bovengenoemde opties gebruiken. Gebruik ze volgens de specifieke vereisten van uw deep learning-projecten.
Succes! We hebben zojuist gedemonstreerd hoe u de “ pytorch_cuda_alloc_conf ” methode om een “ max_split_size_mb ” voor een PyTorch-project.
Conclusie
Gebruik de ' pytorch_cuda_alloc_conf ”-methode om CUDA-geheugen toe te wijzen met behulp van een van de beschikbare opties volgens de vereisten van het model. Deze opties zijn elk bedoeld om een bepaald verwerkingsprobleem binnen PyTorch-projecten te verlichten voor betere looptijden en soepelere bewerkingen. In dit artikel hebben we de syntaxis gedemonstreerd om de “ max_split_size_mb ”optie om de maximale grootte van de splitsing te definiëren.