In dit artikel wordt besproken hoe u de Elasticsearch multi-get API kunt gebruiken om meerdere JSON-documenten op te halen op basis van hun ID's. Bovendien kunt u met Elasticsearch een enkele get-query gebruiken om de documenten uit indices op te halen met alleen de document-ID's.
Laten we onderzoeken.
Syntaxis aanvragen
Het volgende is de syntaxis voor de Elasticsearch multi-get API:
GET /_mget
GET /
De multi-get API ondersteunt meerdere indices waardoor u de documenten kunt ophalen, zelfs als ze zich niet in dezelfde index bevinden.
De aanvraag ondersteunt de volgende padparameters:
-
– De naam van de index waaruit de documenten moeten worden opgehaald, zoals gespecificeerd door hun ID's.
U kunt ook de andere queryparameters opgeven, zoals weergegeven:
- Voorkeur – Definieert het voorkeursknooppunt of de shard.
- Echte tijd – Indien ingesteld op waar, wordt de bewerking in realtime uitgevoerd.
- Vernieuwen – Forceert de bewerking om de doelscherven te vernieuwen voordat de opgegeven documenten worden opgehaald.
- Routering – Een waarde die wordt gebruikt om de bewerkingen naar een specifieke Shard te routeren.
- Store_fields – Haalt de documentvelden op die zijn opgeslagen in een index in plaats van in het document.
- _bron – Een Booleaanse waarde die bepaalt of de aanvraag het veld _source moet retourneren of niet.
De query vereist de hoofdtekst, die de volgende waarden bevat:
- Documenten – Specificeert de documenten die u wilt ophalen. Daarnaast ondersteunt deze sectie de volgende kenmerken:
- _ID kaart – Unieke ID van het doeldocument.
- _inhoudsopgave – De index die het doeldocument bevat.
- Routering – De sleutel voor de primaire shard van het document.
- _bron – Indien waar, bevat het alle bronvelden; anders sluit het hen uit.
- _stored_fields – De opgeslagen_velden die u wilt opnemen.
- ID's – De id's van de documenten die u wilt ophalen.
Voorbeeld 1: Haal meerdere documenten op uit dezelfde index
Het volgende voorbeeld laat zien hoe u de Elasticsearch multi-get API gebruikt om de documenten met specifieke ID's uit de Netflix-index op te halen:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportage' -H 'Content-Type: application/json' -d'{
'documenten': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Het gegeven verzoek moet de documenten met de opgegeven ID's ophalen uit de Netflix-index. De resulterende uitvoer is zoals weergegeven:
{'documenten': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_versie 1,
'_seq_no': 0,
'_primary_term': 1,
'gevonden': waar,
'_bron': {
'duur': '90 min',
'listed_in': 'Documenten',
'land': 'Verenigde Staten',
'date_added': '25 september 2021',
'show_id': 's1',
'regisseur': 'Kirsten Johnson',
'release_jaar': 2020,
'beoordeling': 'PG-13',
'description': 'Terwijl haar vader het einde van zijn leven nadert, ensceneert filmmaker Kirsten Johnson zijn dood op inventieve en komische manieren om hen beiden te helpen het onvermijdelijke onder ogen te zien.',
'type': 'Film',
'titel': 'Dick Johnson is dood'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_versie 1,
'_seq_no': 12,
'_primary_term': 1,
'gevonden': waar,
'_bron': {
'land': 'Duitsland, Tsjechië',
'show_id': 's13',
'regisseur': 'Christian Schwochow',
'release_jaar': 2021,
'beoordeling': 'TV-MA',
'description': 'Nadat het grootste deel van haar familie is vermoord bij een terroristische bomaanslag, wordt een jonge vrouw onbewust gelokt om zich bij de groep aan te sluiten die hen heeft vermoord.',
'type': 'Film',
'titel': 'Ik ben Karl',
'duur': '127 minuten',
'listed_in': 'Drama's, Internationale films',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 september 2021'
}
}
]
}
We kunnen het verzoek ook vereenvoudigen door de document-ID's in een eenvoudige array te plaatsen, zoals hieronder wordt weergegeven:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportage' -H 'Content-Type: application/json' -d'{
'id's': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Het vorige verzoek zou een vergelijkbare actie moeten uitvoeren.
Voorbeeld 2: Haal de documenten op van meerdere aanduidingen
In het volgende voorbeeld haalt het verzoek meerdere documenten op van verschillende indexen, zoals weergegeven:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportage' -H 'Inhoudstype: applicatie/json' -d'{
'documenten': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
De resulterende uitvoer is zoals weergegeven:

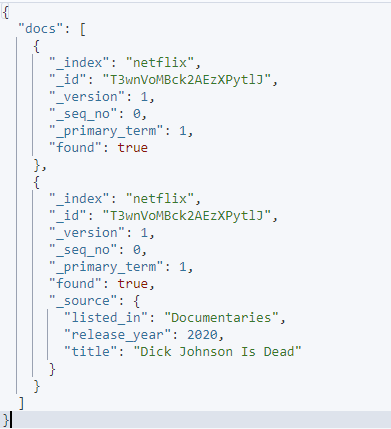
Voorbeeld 3: Specifieke velden uitsluiten
We kunnen specifieke velden uitsluiten van een bepaald verzoek met behulp van de parameters source_include en source_exclude.
Een voorbeeld is zoals getoond:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportage' -H 'Inhoudstype: applicatie/json' -d'{
'documenten': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': false
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_bron': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'description', 'type', 'date_added' ]
}
}
]
}'
Het gegeven verzoek gebruikt de bron include en exclude om aan te geven welke velden u in een bepaald document wilt ophalen.
De resulterende uitvoer is zoals weergegeven:
Conclusie
In dit bericht hebben we de basisprincipes besproken van het werken met Elasticsearch multi-get API waarmee u meerdere documenten uit verschillende bronnen kunt ophalen op basis van hun ID's. Bekijk gerust de andere documenten voor meer informatie.
Veel plezier met coderen!