Het beheren van grote hoeveelheden gegevens kan een zware taak zijn voor gegevensbeheerders, vooral als uw zoekopdracht of scanresultaten uit meerdere pagina's bestaan. Paginering in DynamoDB stelt de database in staat om de grote hoeveelheden gegevens te verwerken door de resultaten op te splitsen in meerdere beheersbare pagina's. In dit artikel wordt de paginering van DynamoDB uitgelegd en worden verschillende mogelijke use-cases en voorbeelden gegeven. Het benadrukt ook hoe de paginering in DynamoDB verschilt van de paginering in andere databases.
Wat is paginering in DynamoDB?
Over het algemeen is paginering, afgeleid van het woord pagina's, een techniek die door databases wordt gebruikt om de gegevensrecords op te splitsen in meerdere delen, segmenten of pagina's. En aangezien AWS DynamoDB de opslag van grote hoeveelheden gegevens ondersteunt, beschikt het over betrouwbare pagineringsmogelijkheden.
De pagineringscomponent DynamoDB zorgt ervoor dat u maximaal 1 GB aan gegevens per scan of query kunt ophalen. Hoewel dat een standaardinstelling is, kunt u een limietparameter aan een query toevoegen om een limiet op te geven. U kunt verder een limiet instellen voor het aantal records in elke scanquery.
Er zijn met name enkele verschillen tussen paginering in DynamoDB en paginering in een typische SQL-database. Het is duidelijk dat elk gepagineerd record dat wordt opgehaald in DynamoDB directe kosten met zich meebrengt, waardoor dit een ongeschreven regel is bij het gebruik van paginering in DynamoDB. Deze functie maakt paginering een essentiële factor bij het beperken van zowel de opgehaalde records als de directe kosten.
Hoe paginering te gebruiken in DynamoDB
1. Paginering tijdens een zoekopdracht
In DynamoDB retourneert een query alleen de resultaten van maximaal 1 MB. Maar u kunt effectief bevestigen of er meer resultaten zijn door uw resultaten nauwkeurig te onderzoeken. Met name het resultaat van een querybewerking op laag niveau bevat een LastEvaluatedKey-element dat niet null is om aan te geven dat er meer items met betrekking tot uw query zijn die u moet ophalen.
Een resultaat zonder een LastEvaluatedKey-element dat niet null is, houdt in dat alle items die overeenkomen met de query binnen de limiet van 1 MB passen en dat er geen items meer zijn om op te halen. U kunt natuurlijk ook een limiet instellen voor het aantal items per resultaat. Zie de volgende voorbeeldopdracht:
aws dynamodb-query \
--table-name MyTableName \
--sleutelvoorwaarde-expressie 'Partitiesleutel = :pk \
--expressie-attribuutwaarden '{' :pk ':{' S ':' a1234b '}},
--limiet 10 \
U kunt de vorige opdracht gebruiken om uw tabel te doorzoeken op de items met dezelfde sleutelvoorwaarde-expressiewaarden. Laten we in onze tabel 'Orders' zoeken naar order_Ids van Darry Tech. We hebben ook een limiet gesteld aan 10 items per pagina. Een andere optie voor de parameter –limit is om de parameter –page-size voor hetzelfde doel te gebruiken.
Paginering is een automatische bewerking in AWS CLI voor items van minder dan 1 MB aan gegevens. U kunt een exclusieve startsleutel aan de opdracht toevoegen als u wilt dat uw zoekopdracht in een bepaalde volgorde begint.
De reactie ziet er als volgt uit:
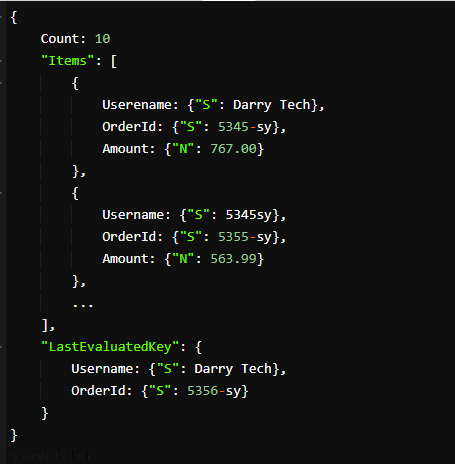
De verstrekte resultaten tonen 10 Darry Tech op de eerste pagina. U kunt de LastEvaluatedKey-waarden gebruiken om meer orders te krijgen die overeenkomen met de uitdrukkingssleutelwaarden van uw zoekopdracht om een nieuwe query samen te stellen. De nieuwe queryaanvraag bevat de LastEvaluatedKey-waarden in de parameter ExclusiveStartKey.
Een voorbeeld van de syntaxis wordt hieronder getoond:
aws dynamodb-query \--table-name Voorbeeldtabel \
--sleutelvoorwaarde-expressie 'Partitiesleutel = :pk \
--expressie-attribuutwaarden '{' :pk ':{' S ': Darry Tech' \
--limiet 10 \
--exclusieve-startsleutel '{' Partitiesleutel ':{' S ': Darry Tech' }, 'Sorteersleutel' :{ 'S' : '5356' }} '
De vorige opdracht produceert de volgende verrekeningsorders op de volgende pagina, te beginnen met de order-ID die de opgegeven primaire sleutel heeft, d.w.z. {“PartitionKey”:{“S”: Darry Tech”},”SortKey”:{“S”: ”5356-sy”}}.
2. Paginering tijdens scanbewerkingen
Het is ook mogelijk om de paginering te gebruiken voor scanbewerkingen. Alles werkt op dezelfde manier als bij de query-commando's. U moet echter het kenmerk filter-expressie gebruiken. De opdracht ziet eruit als wat we hier hebben:
aws dynamodb-scan \--table-name MijnTabel \
--filter-expressie 'Kenmerknaam = :waarde' \
--expressie-attribuutwaarden '{':value':{'S':'ABC123'}}' \
--begrenzing twintig \
--exclusieve-startsleutel '{'PartitionKey':{'S':'ABC123'},'SortKey':{'S':'XYZ987'}}'
De vorige opdracht haalt tot 20 items per pagina op uit de MyTable-tabel, te beginnen met het item waarvan de primaire sleutel {“PartitionKey”: “ABC123”, “SortKey”: “XYZ987”} is. Het filtert de resultaten zodat alleen de items worden opgenomen waarvan het kenmerk AttributeName de waarde 'ABC123' heeft.
In de reactie, de LastEvaluatedKey veld bevat de primaire sleutel van het laatste item in de resultatenset. U kunt deze waarde gebruiken als de ExclusieveStartKey in een volgende scannen bewerking om de volgende pagina met resultaten op te halen.
Gevolgtrekking
Paginering in DynamoDB verbetert de beheersbaarheid van gegevens. Het is echter essentieel om te weten of uw systemen zullen profiteren van paginering. Het is noodzakelijk om paginering te gebruiken als u een lange lijst met items in een toepassing heeft. Hoewel de geleverde illustratie zich richt op de AWS CLI-aanroep, kunt u ook paginering gebruiken met AWS SDK's zoals Python's Boto3 of een SDK die u verkiest.