Dubbele gegevens kunnen vaak leiden tot verwarring, fouten en vertekende inzichten. Gelukkig biedt Google Spreadsheets ons veel hulpmiddelen en technieken om de taak van het identificeren en verwijderen van deze overbodige vermeldingen te vereenvoudigen. Van eenvoudige celvergelijkingen tot geavanceerde, op formules gebaseerde benaderingen: u bent in staat om rommelige werkbladen om te zetten in georganiseerde, waardevolle bronnen.
Of u nu klantenlijsten, enquêteresultaten of een andere dataset verwerkt, het elimineren van dubbele invoer is een fundamentele stap in de richting van betrouwbare analyse en besluitvorming.
In deze handleiding gaan we dieper in op twee methoden waarmee u dubbele waarden kunt identificeren en verwijderen.
Tabel creatie
We hebben eerst een tabel gemaakt in Google Spreadsheets, die later in dit artikel in de voorbeelden zal worden gebruikt. Deze tabel heeft 3 kolommen: Kolom A, met de kop “Naam”, slaat namen op; Kolom B heeft de kop “Leeftijd”, die de leeftijden van de mensen bevat; en ten slotte bevat kolom C, kop 'Stad', steden. Als we observeren, zijn sommige vermeldingen in deze tabel gedupliceerd, zoals de vermeldingen voor ‘John’ en ‘Sara’.
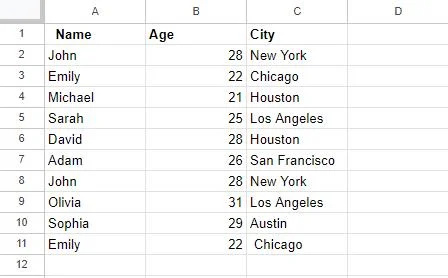
We zullen aan deze tabel werken om deze dubbele waarden met verschillende methoden te verwijderen.
Methode 1: De functie 'Duplicaten verwijderen' gebruiken in Google Spreadsheets
De eerste methode die we hier bespreken, is het verwijderen van de dubbele waarden door gebruik te maken van de functie 'Duplicaten verwijderen' van Google Spreadsheet. Deze methode verwijdert permanent dubbele vermeldingen uit het geselecteerde celbereik.
Om deze methode te demonstreren, zullen we opnieuw de hierboven gegenereerde tabel bekijken.
Om aan deze methode te gaan werken, moeten we eerst het volledige bereik selecteren dat onze gegevens bevat, inclusief headers. In dit scenario hebben we cellen gekozen A1:C11 .
Bovenaan het Google Spreadsheets-venster ziet u een navigatiebalk met verschillende menu's. Zoek en klik op de optie 'Gegevens' in de navigatiebalk.
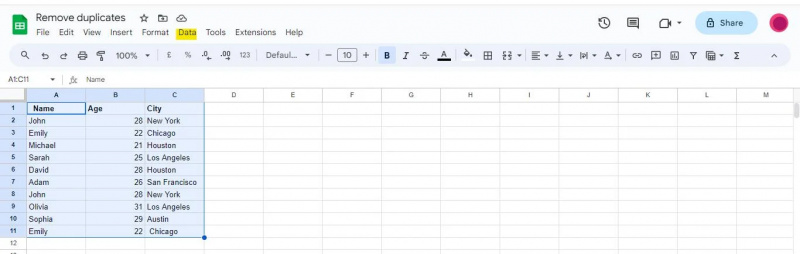
Er verschijnt een vervolgkeuzemenu wanneer u op de optie ‘Gegevens’ klikt, waarin u verschillende gegevensgerelateerde tools en functies krijgt aangeboden die kunnen worden gebruikt om uw gegevens te analyseren, op te schonen en te manipuleren.
Voor dit voorbeeld hebben we toegang nodig tot het menu ‘Gegevens’ om naar de optie ‘Gegevens opschonen’ te navigeren, die de functie ‘Duplicaten verwijderen’ bevat.
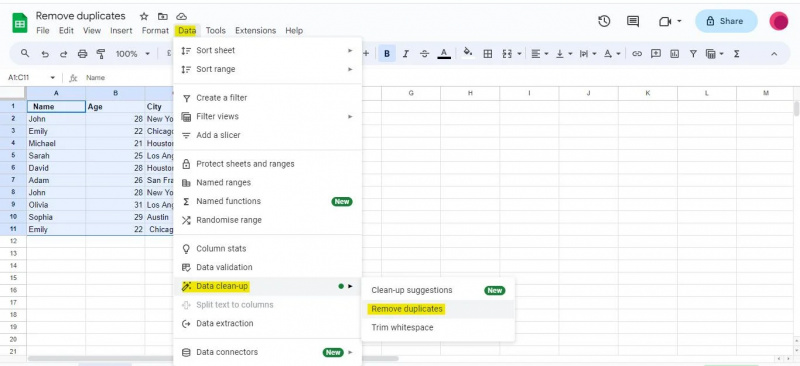
Nadat we het dialoogvenster ‘Duplicaten verwijderen’ hebben geopend, krijgen we een lijst met kolommen in onze dataset te zien. Op basis van deze kolommen worden duplicaten gevonden en verwijderd. We zullen de overeenkomstige selectievakjes in het dialoogvenster markeren, afhankelijk van welke kolommen we willen gebruiken voor het identificeren van duplicaten.
In ons voorbeeld hebben we drie kolommen: 'Naam', 'Leeftijd' en 'Plaats'. Omdat we duplicaten willen identificeren op basis van alle drie de kolommen, hebben we alle drie de selectievakjes aangevinkt. Afgezien daarvan moet u het selectievakje 'Gegevens hebben koptekstrij' aanvinken als uw tabel kopteksten heeft. Omdat we headers hebben in de bovenstaande tabel, hebben we het selectievakje ‘Gegevens hebben headerrij’ aangevinkt.
Zodra we de kolommen hebben geselecteerd om duplicaten te identificeren, kunnen we doorgaan met het verwijderen van die duplicaten uit onze dataset.
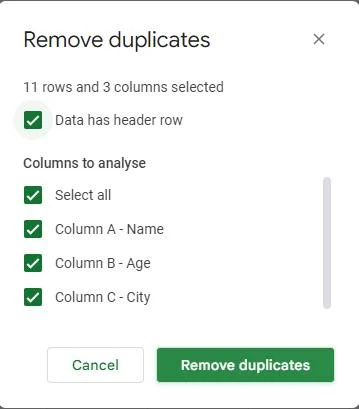
Onderaan het dialoogvenster 'Duplicaten verwijderen' vindt u een knop met de naam 'Duplicaten verwijderen'. Klik op deze knop.
Nadat u op 'Duplicaten verwijderen' heeft geklikt, verwerkt Google Spreadsheets uw verzoek. De kolommen worden gescand en alle rijen met dubbele waarden in die kolommen worden verwijderd, waardoor duplicaten met succes worden geëlimineerd.
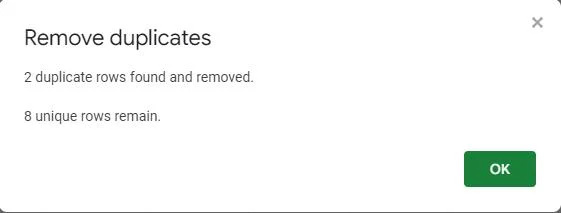
Een pop-upscherm bevestigt dat de dubbele waarden uit de tabel zijn verwijderd. Hieruit blijkt dat er twee dubbele rijen zijn gevonden en verwijderd, waardoor de tabel acht unieke vermeldingen bevat.
Nadat we de functie ‘Duplicaten verwijderen’ hebben gebruikt, wordt onze tabel als volgt bijgewerkt:
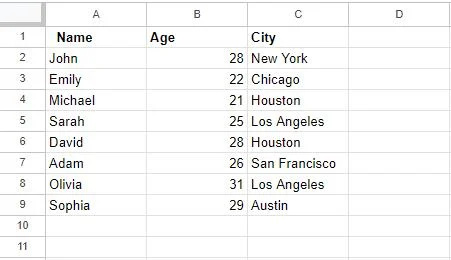
Een belangrijke opmerking om hier rekening mee te houden is dat het verwijderen van duplicaten met deze functie een permanente actie is. Dubbele rijen worden uit uw dataset verwijderd en u kunt deze actie niet ongedaan maken, tenzij u over een gegevensback-up beschikt. Zorg er dus voor dat u de juiste kolommen heeft gekozen om duplicaten te vinden door uw selectie nogmaals te controleren.
Methode 2: De UNIEKE functie gebruiken om duplicaten te verwijderen
De tweede methode die we hier zullen bespreken, is het gebruik van de UNIEK functie in Google Spreadsheets. De UNIEK functie haalt verschillende waarden op uit een opgegeven bereik of kolom met gegevens. Hoewel duplicaten niet rechtstreeks uit de originele gegevens worden verwijderd, wordt er wel een lijst met unieke waarden gemaakt die u kunt gebruiken voor gegevenstransformatie of -analyse zonder duplicaten.
Laten we een voorbeeld maken om deze methode te begrijpen.
We zullen de tabel gebruiken die in het eerste deel van deze zelfstudie is gegenereerd. Zoals we al weten, bevat de tabel bepaalde gegevens die gedupliceerd zijn. We hebben dus een cel, “E2”, gekozen om de UNIEK formule in. De formule die we hebben geschreven is als volgt:
=UNIEK(A2:A11)
Bij gebruik in Google Spreadsheets haalt de UNIQUE-formule unieke waarden op in een aparte kolom. Daarom hebben we deze formule voorzien van een celbereik A2 naar A11 , die wordt toegepast in kolom A. Deze formule extraheert dus de unieke waarden uit kolom A en geeft ze weer in de kolom waarin de formule is geschreven.
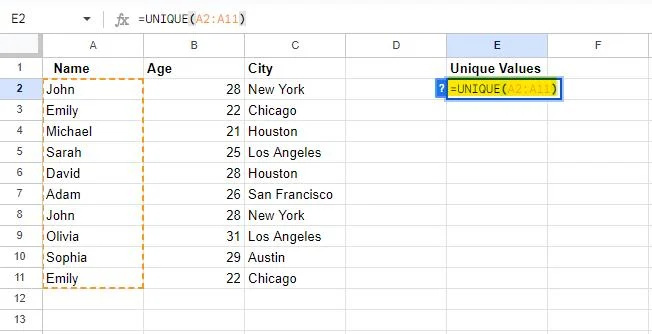
De formule wordt toegepast op het aangegeven bereik wanneer u op Enter drukt.
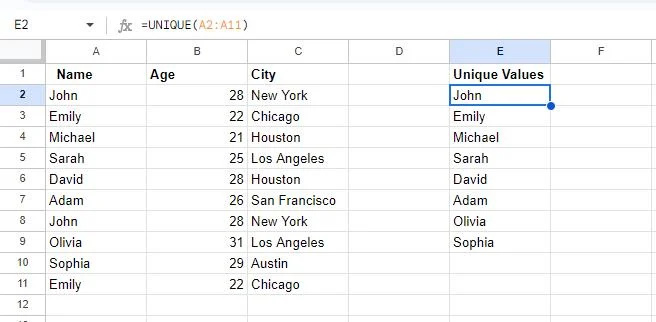
In deze momentopname kunnen we zien dat twee cellen leeg zijn. Dit komt omdat er twee waarden in de tabel zijn gedupliceerd, namelijk John en Emily. De UNIEK functie geeft slechts één exemplaar van elke waarde weer.
Deze methode verwijderde de dubbele waarden niet rechtstreeks uit de opgegeven kolom, maar creëerde een andere kolom om ons de unieke vermeldingen van die kolom te verschaffen, waardoor de duplicaten werden geëlimineerd.
Conclusie
Het verwijderen van duplicaten in Google Spreadsheets is een nuttige methode voor het analyseren van gegevens. In deze handleiding worden twee methoden gedemonstreerd waarmee u eenvoudig dubbele vermeldingen uit uw gegevens kunt verwijderen. De eerste methode legde het gebruik van Google Spreadsheets uit om de dubbele functie te verwijderen. Deze methode scant het opgegeven celbereik en elimineert duplicaten. De andere methode die we hebben besproken is het gebruik van de formule voor het ophalen van dubbele waarden. Hoewel duplicaten niet direct uit het bereik worden verwijderd, worden in plaats daarvan de unieke waarden in een nieuwe kolom weergegeven.